当你在搜索引擎中输入想要搜索的一部分内容时,搜索引擎就会自动弹出下拉框,里面是各种关键词提示,这个功能是怎么实现的呢?其实底层最基本的就是 Trie 树这种数据结构。
1. 什么是 “Trie” 树
Trie 树也叫 “字典树”。顾名思义,它是一个树形结构,专门用来处理在一组字符串集合中快速查找某个字符串的问题。
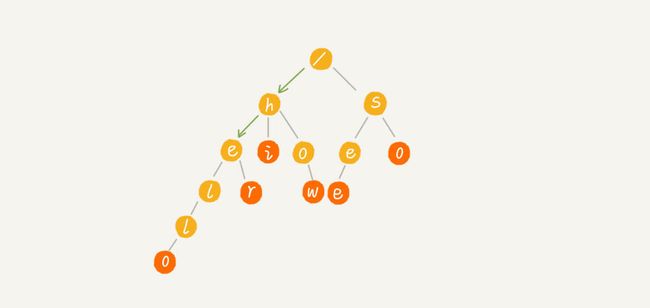
假设我们有 6 个字符串,它们分别是:how,hi,her,hello,so,see。我们希望在这里面多次查找某个字符串是否存在,如果每次都拿要查找的字符串和这六个字符串依次进行匹配,那效率就会比较低。
如果我们可以对这六个字符串做一下预处理,组织成 Trie 树的结构,那之后每次查找,都只要在 Trie 树中进行匹配即可。Trie 树的本质,就是利用字符串之间的公共前缀,将重复的前缀合并在一起。
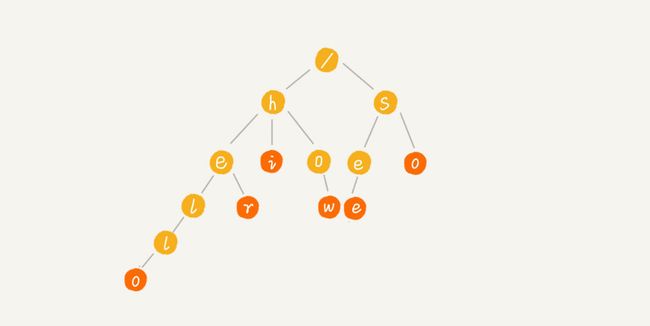
其中,根节点不包含任何信息,每个节点代表字符串中的一个字符,从根节点到红色节点的一条路径表示一个字符串。注意红色节点并不都是叶子节点,比如有两个词 how 和 however,那么 w 和 r 都是红色节点。一个 Trie 树的构造过程如下所示。
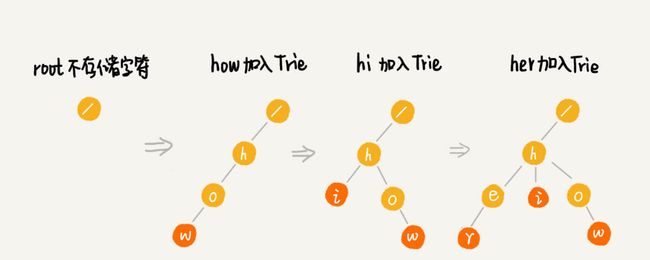
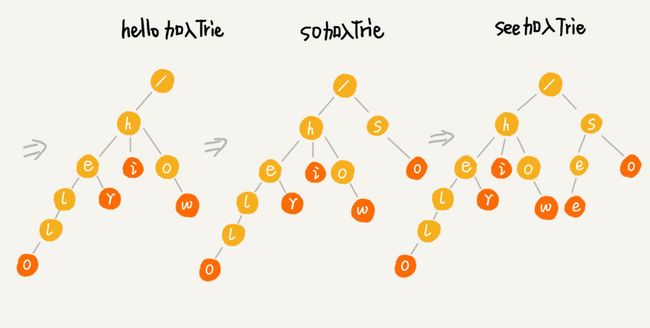
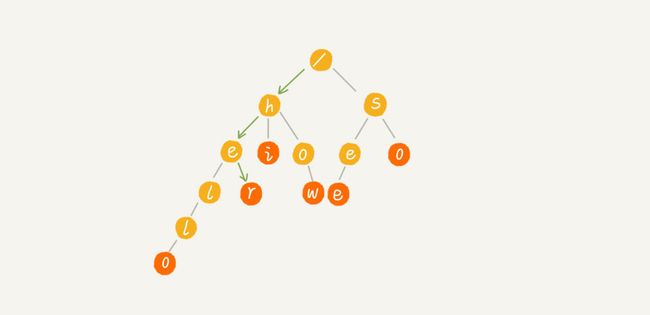
当我们要在构建好的 Trie 树中查找一个字符串的时候,那就要将查找的字符串分割成单个的字符,然后从根节点开始匹配。如下面的例子所示,绿色路径就是 “her” 的匹配路径,而 “he” 的最后一个匹配节点并不是红色节点,所以其并不能完全匹配任何字符串。
2. 如何实现一棵 Trie 树
从上面我们可以看到,Trie 树主要有两个操作:一个是将字符串集合构建成 Trie 树,另一个是在 Trie 树中查询一个字符串。
Trie 树是一个多叉树结构,其子节点个数事先未知,但我们可以借助散列表的思想,在下标与字符之间建立一个一一映射,来存储子节点的指针。
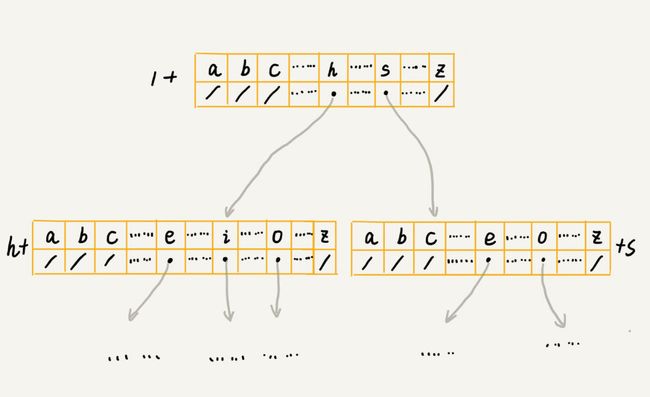
假设我们的字符串只有 a 到 z 这 26 个字母,那么数组下标为 0 的元素就存储指向子节点 a 的指针,下标为 1 的元素就存储指向子节点 b 的指针,以此类推,下标为 25 的元素就存储指向子节点 z 的指针。如果某个字符的子节点不存在,那对应该下标位置的元素就为 NULL。当我们在 Trie 树中进行查找的时候,就可以拿字符的 ASCII 码减去 'a' 的 ASCII 码来获取其子节点的指针。
#include
#include
using namespace std;
class TrieNode
{
public:
char data;
bool is_ending_char;
TrieNode *children[26];
TrieNode(char ch)
{
data = ch;
is_ending_char = false;
for (int i = 0; i < 26; i++)
children[i] = NULL;
}
};
class Trie
{
private:
TrieNode *root;
public:
// 构造函数,根节点存储无意义字符 '/'
Trie()
{
root = new TrieNode('/');
}
// 向 Trie 树中添加一个字符串
void insert_string(const char str[])
{
TrieNode *cur = root;
for (unsigned int i = 0; i < strlen(str); i++)
{
int index = int(str[i] - 'a');
if (cur->children[index] == NULL)
{
TrieNode *temp = new TrieNode(str[i]);
cur->children[index] = temp;
}
cur = cur->children[index];
}
cur->is_ending_char = true;
}
// 在 Trie 树中查找一个字符串
bool search_string(const char str[])
{
TrieNode *cur = root;
for (unsigned int i = 0; i < strlen(str); i++)
{
int index = int(str[i] - 'a');
if (cur->children[index] == NULL)
{
return false;
}
cur = cur->children[index];
}
if (cur->is_ending_char == true) return true;
else return false;
}
};
int main()
{
char str[][8] = {"how", "hi", "her", "hello", "so", "see", "however"};
Trie test;
for (int i = 0; i < 7; i++)
{
test.insert_string(str[i]);
}
cout << "Finding \'her\': " << test.search_string("her") << endl;
cout << "Finding \'he\': " << test.search_string("he") << endl;
cout << "Finding \'how\': " << test.search_string("how") << endl;
cout << "Finding \'however\': " << test.search_string("however") << endl;
return 0;
} 在构建 Trie 树的过程中,需要扫描所有的字符串,时间复杂度为 O(n),其中 n 表示所有字符串的长度之和。而在 Trie 树中进行查找的话,如果待查找字符串的长度为 k 的话,那最多只需要对比 k 个节点即可,时间复杂度为 O(k)。
3. Trie 树的内存消耗
在上面的例子中,Trie 树的每个节点都要存储 26 个指针,尽管某些节点的子节点很少,我们依然要维护这么一个长度的数组。另外,如果字符串中不仅包含小写字母,而且包含大写字母、数字甚至是中文等,那就会需要更多的存储空间。也就是说,在某些情况下,Trie 树并不一定会节省内存空间,尤其是在重复前缀不多的时候。
当然,尽管 Trie 树可能会很浪费内存,但是确实非常高效,这也是一种空间换时间的折中。如果我们可以稍微牺牲一点查询的效率,那就可以选用数组、散列表、红黑树等其他数据结构来存储一个节点的子节点指针。
假设我们使用数组,数组中的指针按照所指向子节点的字符大小顺序排列。这样,在查找的时候,我们可以通过二分算法来快速找到指向子节点的指针。但是,在往 Trie 树中插入字符串的话,为了维护数组的有序性,就会稍微慢了点。
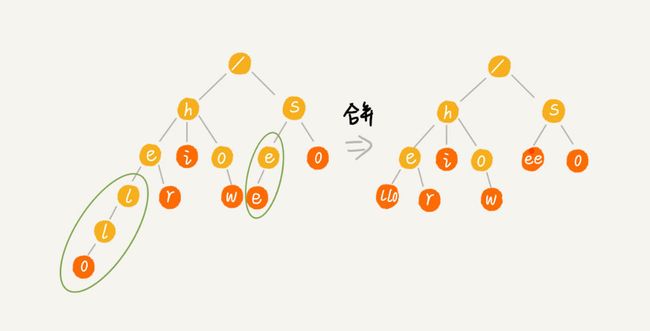
另外,还可以采用缩点优化,将只有一个子节点而且不是结束节点的节点与其子节点进行合并,来节省空间,但这也增加了编码难度。
4. Trie 树与散列表、红黑树的比较
在字符串匹配或者说查找问题上,Trie 树对要处理的字符串有极其严格的要求。
- 字符串中包含的字符集不能太大;
- 字符串的前缀重合比较多;
- 从零开始实现一个 Trie 树,比较复杂,不便于维护;
- Trie 树中利用指针来存储数据,不利用利用缓存。
因此,在工程中,我们更倾向于使用散列表或者红黑树,它们都不需要自己去实现,直接利用编程语言中提供的线程类库就行。实际上,Trie 树不适合这种精确查找,更适合的是查找前缀匹配的字符串,也就是搜索时的关键词提示功能。
5. 搜索关键词提示功能的实现
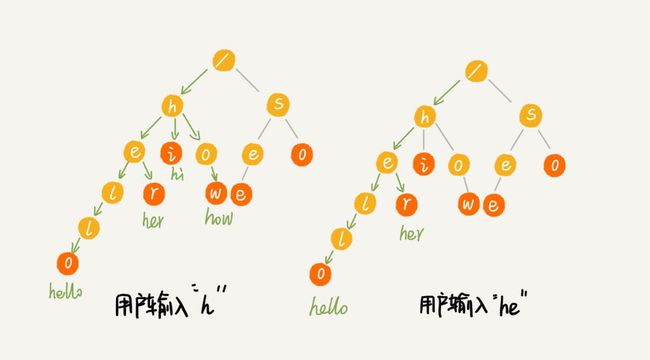
假设关键词库由用户的热门搜索关键词组成,我们将这个词库构建成一个 Trie 树。当用户输入其中某个单词的时候,把这个词作为一个前缀子串在 Trie 树中匹配。还以上面为例,当用户输入 'h' 时,我们就可以将以 'h' 为前缀的单词 hello,her,hi,how 展示在搜索提示框,当用户输入 'he' 时,我们就可以将以 'h' 为前缀的单词 hello,her 展示在搜索提示框。这就是搜索关键词提示的最基本的算法原理。
另外,Trie 树还可以扩展到更加广泛的应用上,比如输入法、代码编辑器和浏览器的自动输入补全功能。
参考资料-极客时间专栏《数据结构与算法之美》
获取更多精彩,请关注「seniusen」! 