Keras中RNN、LSTM、GRU等输入形状batch_input_shape=(batch_size,time_steps,input_dim)及TimeseriesGenerator详解
最近在使用Keras进行项目实战时,在RNN这块迷惑了,迷惑就是这个输入数据的形状以及如何定义自己的输入数据,因此系统的学习了一下,把学习的总结一下,感觉会有很多人在这里迷惑,如果对你有帮助记得点赞哈。
为了便于大家深入理解batch_input_shape=(batch_size,time_steps,input_dim)的意思,这里我们先从制作数据开始理解,这样效果更好,一旦这个学会,我们就可以使用这个函数制作自己的训练数据集和验证数据集,请大家一定深入理解,最后我们再看看batch_input_shape=(batch_size,time_steps,input_dim)为什么要这样。
keras.preprocessing.sequence.TimeseriesGenerator(data, targets,
length,
sampling_rate=1,
stride=1,
start_index=0,
end_index=None,
shuffle=False,
reverse=False,
batch_size=128)参数
- data:可索引的生成器(例如列表或Numpy数组),包含连续数据点(时间步)。数据应该是2D的,且第0个轴为时间维度。
- targets:对应于
data的时间步的目标值。它应该与data的长度相同。 - length:输出序列的长度(以时间步数表示)。
- sampling_rate:序列内连续各个时间步之间的周期对于周期
r,时间步data[i],data[i-r]......data[i - length]被用于生成样本序列。 - stride:连续输出序列之间的周期。对于周期
s,连续输出样本将为data[i],data[i+s],data[i+2*s]等。 - start_index:在
start_index之前的数据点在输出序列中将不被使用。这对保留部分数据以进行测试或验证很有用。 - end_index:在
end_index之后的数据点在输出序列中将不被使用。这对保留部分数据以进行测试或验证很有用。 - shuffle:是否打乱输出样本,还是按照时间顺序绘制它们。
- 反向:布尔值:如果
true,每个输出样本中的时间步将按照时间倒序排列。 - batch_size:每个批次中的时间序列样本数(可能除最后一个外)。
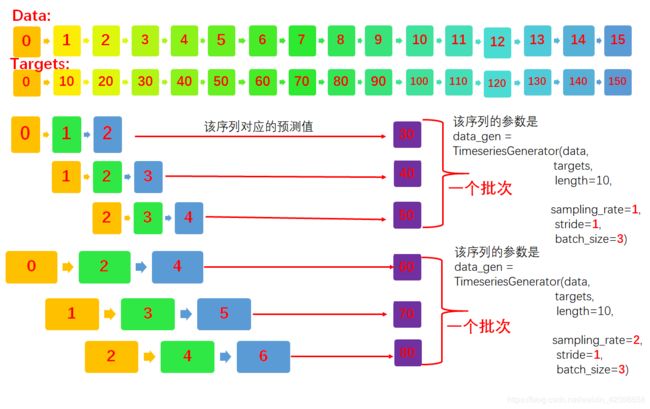
下面就详细的介绍一下,然后给出大量的示例,这个理解对时间序列模型的数据输入具有很好的启发性,假设有序列数据为0,1,2,,,,15,该序列数据对应的目标数据是0,10,20,,,,,150,下面主要看看三个参数即sampling_rat、stride、batch_size.如下下图所示,假如输出的length = 4(图中的length=10,忘了改了),就是说输出时间步数应该小于等于4,例如0,1,2的时间步数为3,可以输出,此时输出的第一组数据为0,1,2,且对应的目标是30,这里大家需要理解的是时间序列总是预测的是下一个时间点,这里的samping_rate=1,说明就每次前进的就是下一个时间点,因此预测的也是下一个时间点测试技术targets的下一个时间点为30,下面开始去除第二组,这个和stride有关了,我们发现第二组是1,2,3,和第一组相比,比第一组延后了一个时间点,这是因为stride=1的缘故,同时呢每一组的都递进也是1,这个和Sampling_rate有关,因为此时Sampling_rate=1,这样一直去下去,直到把整个数据取完,下面我们我们看看如果Sampling_rate=2会是什么情况呢?这里的其他参数不变,我们发现改变的只是每组的数据步进长为2,如下图的第一组的0,2,4,此时的length应该为6,我们发现他的预测值是对应targets位置的下一个时间点,此时间隔也是2,即是60,这里大家需要理解,这是第一组的数据,下面我们来看看第二组数据,因为stride=1即步幅等于1,所以这组的开始为从1,开始,但是间隔仍为2,记得到1,3,5且对应的目标为70,下面我们改变其他的量即stride = 2会是什么情况呢?
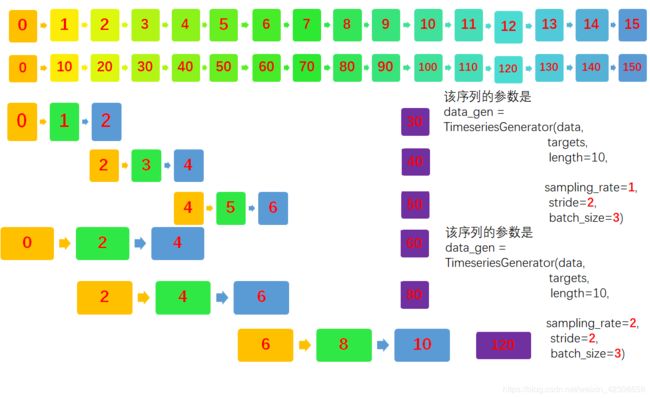
下面考虑stride = 2的情况:
这个大家自己看吧,下面我们开始使用代码测试观察。
我们通过代码继续深入理解一下,时间步和批次的概念。
我们先看看数据是设么样的:
from keras.preprocessing.sequence import TimeseriesGenerator
import numpy as np
data = np.array([[i] for i in range(50)])
targets = np.array([[i] for i in range(0,500,10)])
print('data.shape : ',data.shape)
print('targets.shape: ',targets.shape)data.shape : (50, 1) targets.shape: (50, 1)
print(data[:10])
print(targets[:10])[[0 1 2 3 4 5 6 7 8 9]] [[ 0 10 20 30 40 50 60 70 80 90]]
上面第一行就是时间序列,第二行就是对应的目标序列他们是一一对应的,同时时间序列可以的多个特征的,上面的知识一个特征,如果是多个特征应该是这样的[[[1,1, 1],[2,2,2][3,3,3],[4,4,4].....],他们对应的目标也是这样的的,希望大家理解,下面我们就具体看看:
从输出数据来看length=10,
sampling_rate=1,
stride=1,
batch_size=2
说明每组的采样点为 sampling_rate=1,即每一个时间步输出一个数组组成一组,不同相邻组之间的开始相差1取决于stride=1,就这样把所有时间的序列都生成这样的序列,然后按照batch_size=2进行组合,也就是说每两组进行组合成一个批次,如下数据所示,下面就不详细的说了,简单的给定参数,大家可以根据结果自己分析。
# 这里我们设置的length=10,说明需要输出数据的最大时间间隔是10,例如第一组0到9时间间隔就是10了,
data_gen = TimeseriesGenerator(data, targets,
length=10,
sampling_rate=1,
stride=1,
batch_size=2)
print('data_gen.length = ',data_gen.length)
print('-------------------------')
for i in zip(*data_gen[0]):
print(*i)
print('******************')data_gen.length = 10 ------------------------- [[0.] [1.] [2.] [3.] [4.] [5.] [6.] [7.] [8.] [9.]] [100.] ****************** [[ 1.] [ 2.] [ 3.] [ 4.] [ 5.] [ 6.] [ 7.] [ 8.] [ 9.] [10.]] [110.] ******************
下面是只改了length=5
data_gen = TimeseriesGenerator(data, targets,
length=5,
sampling_rate=1,
stride=1,
batch_size=2)
print('data_gen.length = ',data_gen.length)
print('-------------------------')
for i in zip(*data_gen[0]):
print(*i)
print('******************')data_gen.length = 5 ------------------------- [[0.] [1.] [2.] [3.] [4.]] [50.] ****************** [[1.] [2.] [3.] [4.] [5.]] [60.] ******************
data_gen = TimeseriesGenerator(data, targets,
length=10,
sampling_rate=2,
stride=1,
batch_size=2)
print('data_gen.length = ',data_gen.length)
print('第一个批次:')
for i in zip(*data_gen[0]):
print(*i)
print('******************')
print('第二个批次:')
for i in zip(*data_gen[1]):
print(*i)
print('******************')这个大家结合上面的讲解可以明白。
data_gen.length = 10 第一个批次: [[0.] [2.] [4.] [6.] [8.]] [100.] ****************** [[1.] [3.] [5.] [7.] [9.]] [110.] ****************** 第二个批次: [[ 2.] [ 4.] [ 6.] [ 8.] [10.]] [120.] ****************** [[ 3.] [ 5.] [ 7.] [ 9.] [11.]] [130.] ******************
data_gen = TimeseriesGenerator(data, targets,
length=10,
sampling_rate=1,
stride=2,
batch_size=2)
print('data_gen.length = ',data_gen.length)
print('第一个批次:')
for i in zip(*data_gen[0]):
print(*i)
print('******************')
print('第二个批次:')
for i in zip(*data_gen[1]):
print(*i)
print('******************')data_gen.length = 10 第一个批次: [[0.] [1.] [2.] [3.] [4.] [5.] [6.] [7.] [8.] [9.]] [100.] ****************** [[ 2.] [ 3.] [ 4.] [ 5.] [ 6.] [ 7.] [ 8.] [ 9.] [10.] [11.]] [120.] ****************** 第二个批次: [[ 4.] [ 5.] [ 6.] [ 7.] [ 8.] [ 9.] [10.] [11.] [12.] [13.]] [140.] ****************** [[ 6.] [ 7.] [ 8.] [ 9.] [10.] [11.] [12.] [13.] [14.] [15.]] [160.] ******************
data_gen = TimeseriesGenerator(data, targets,
length=10,
sampling_rate=2,
stride=2,
batch_size=2)
print('data_gen.length = ',data_gen.length)
print('第一个批次:')
for i in zip(*data_gen[0]):
print(*i)
print('******************')
print('第二个批次:')
for i in zip(*data_gen[1]):
print(*i)
print('******************')
data_gen.length = 10 第一个批次: [[0.] [2.] [4.] [6.] [8.]] [100.] ****************** [[ 2.] [ 4.] [ 6.] [ 8.] [10.]] [120.] ****************** 第二个批次: [[ 4.] [ 6.] [ 8.] [10.] [12.]] [140.] ****************** [[ 6.] [ 8.] [10.] [12.] [14.]] [160.] ******************
有兴趣的同学可直接多尝试看看,至于时间序列的输入batch_input_shape=(batch_size,time_steps,input_dim)是什么意思呢?
现在来看是不是很简单呢?其实所谓时间序列的预测就是说,数据是按照时间生成的,那么按理说我们应该一个个输入的,但是这样输入的,得到的特征无法体现时间的前后联系性,同时我们根据当前时刻的前n个时间步去预测下一个时间步的输出,上面的一直都是这样,因为我们,至于批次,那就更简单了,我把组合的时间点数据,按不同的书进行一次输入,然后把累加误差求和取均值在调整参数,这样模型更容易收敛,大家可以参考我的调优方面的文章。至于input_dim就是输入数据的特征,即每个时间点都有这么多的特征,这样就好理解了,大家可以试试通过这个函数去去生成自己的数据。