TensorFlow的MNIST手写数字分类问题 基础篇
本次笔记是训练一个机器学习模型用于预测图片里面的数字。
目录
- 数据集
- softmax 模型
- 实现回归模型
- 训练模型
- 评估模型
数据集
MNIST 数据集的官网是Yann LeCun’s website. 在这里,我们提供了一份 python 源代码用于自动下载和安装这个数据集.你可以下载 这份代码,然后用下面的代码导入到你的项目里面,也可以直接复制粘贴到你的代码文件里面.
import input_data
mnist = input_data.read_data_sets("MNIST_data/", one_hot=True)
标签数据是"one-hot vectors". 一个 one-hot 向量除了某一位的数字是1以外其余各维度数字都是0.
本次有60000行的训练数据集(mnist.train)和10000行的测试数据集(mnist.test).这样的切分很重要,在机器学习模型设计时必须有一个单独的测试数据集不用于训练而是用来评估这个模型的性能,从而更加容易把设计的模型推广到其他数据集上(泛化).
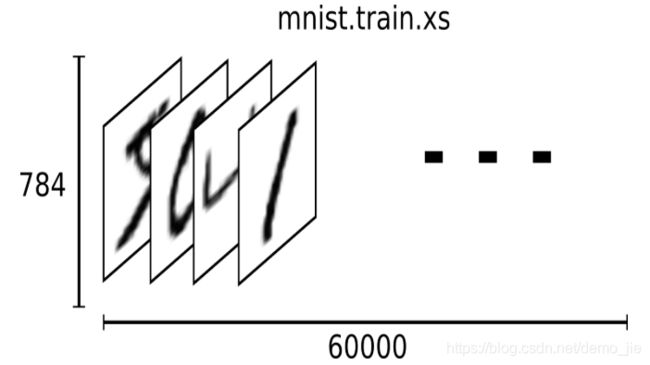
每一个 MNIST 数据单元有两部分组成:一张包含手写数字的图片和一个对应的标签.我们把这些图片设为“xs”,把这些标签设为“ys”.训练数据集和测试数据集都包含xs和ys,比如训练数据集的图片是 mnist.train.images ,训练数据集的标签是 mnist.train.labels.每一张图片包含28像素X28像素.
因此,在MNIST训练数据集中,mnist.train.images 是一个形状为 [60000, 784] 的张量,第一个维度数字用来索引图片,第二个维度数字用来索引每张图片中的像素点.在此张量里的每一个元素,都表示某张图片里的某个像素的强度值,值介于0和1之间.
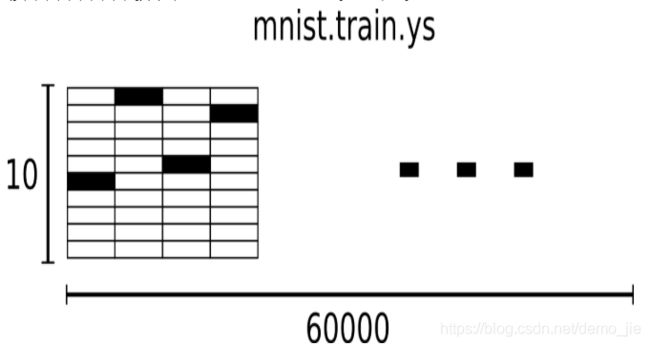
mnist.train.labels 是一个 [60000, 10] 的数字矩阵.
softmax 模型
softmax 模型可以用来给不同的对象分配概率.
第一步
为了得到一张给定图片属于某个特定数字类的证据(evidence),我们对图片像素值进行加权求和.如果这个像素具有很强的证据说明这张图片不属于该类,那么相应的权值为负数,相反如果这个像素拥有有利的证据支持这张图片属于这个类,那么权值是正数.
下面的图片显示了一个模型学习到的图片上每个像素对于特定数字类的权值.红色代表负数权值,蓝色代表正数权值.

需要加入一个额外的偏置量(bias),因为输入往往会带有一些无关的干扰量.因此对于给定的输入图片 x 它代表的是数字 i 的证据可以表示为
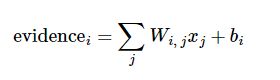
其中 代表权重, 代表数字 i 类的偏置量,j 代表给定图片 x 的像素索引用于像素求和.然后用softmax函数可以把这些证据转换成概率 y:
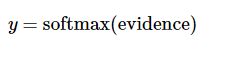
这里的softmax可以看成是一个激励(activation)函数或者链接(link)函数,把我们定义的线性函数的输出转换成我们想要的格式,也就是关于10个数字类的概率分布.因此,给定一张图片,它对于每一个数字的吻合度可以被softmax函数转换成为一个概率值.softmax函数可以定义为:
![]()
展开等式右边的子式,可以得到:
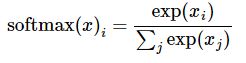
但是更多的时候把 softmax 模型函数定义为前一种形式:把输入值当成幂指数求值,再正则化这些结果值.这个幂运算表示,更大的证据对应更大的假设模型(hypothesis)里面的乘数权重值.反之,拥有更少的证据意味着在假设模型里面拥有更小的乘数系数.假设模型里的权值不可以是0值或者负值.Softmax 然后会正则化这些权重值,使它们的总和等于1,以此构造一个有效的概率分布.
对于 softmax 回归模型可以用下面的图解释,对于输入的 xs 加权求和,再分别加上一个偏置量,最后再输入到 softmax 函数中:

如果把它写成一个等式,可以得到:
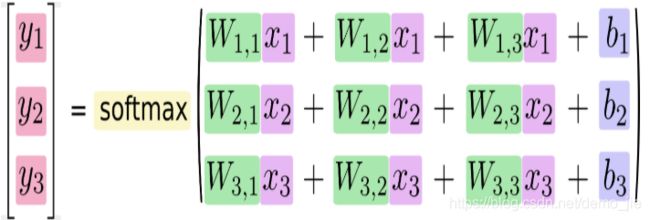
用向量表示这个计算过程:用矩阵乘法和向量相加.这有助于提高计算效率.(也是一种更有效的思考方式)

因此:
![]()
实现回归模型
使用 TensorFlow 之前,首先导入它:
import tensorflow as tf
通过操作符号变量来描述这些可交互的操作单元,可以用下面的方式创建一个:
x = tf.placeholder("float", [None, 784])
x 不是一个特定的值,而是一个占位符 placeholder,我们在 TensorFlow 运行计算时输入这个值.我们希望能够输入任意数量的 MNIST 图像,每一张图展平成784维的向量.我们用2维的浮点数张量来表示这些图,这个张量的形状是 [None,784 ].(这里的 None 表示此张量的第一个维度可以是任何长度的.)
我们的模型也需要权重值和偏置量,当然我们可以把它们当做是另外的输入(使用占位符),但 TensorFlow 有一个更好的方法来表示它们:Variable . 一个 Variable 代表一个可修改的张量,存在在 TensorFlow 的用于描述交互性操作的图中.它们可以用于计算输入值,也可以在计算中被修改.对于各种机器学习应用,一般都会有模型参数,可以用 Variable 表示.
W = tf.Variable(tf.zeros([784,10]))
b = tf.Variable(tf.zeros([10]))
我们赋予tf.Variable不同的初值来创建不同的Variable:在这里,我们都用全为零的张量来初始化W和b.因为我们要学习W和b的值,它们的初值可以随意设置.
注意,W的维度是[784,10],因为我们想要用784维的图片向量乘以它以得到一个10维的证据值向量,每一位对应不同数字类.b的形状是[10],所以我们可以直接把它加到输出上面.
现在,我们可以实现我们的模型啦.只需要一行代码!
y = tf.nn.softmax(tf.matmul(x,W) + b)
首先,我们用tf.matmul(X,W)表示x乘以W,对应之前等式里面的,这里x是一个2维张量拥有多个输入.然后再加上b,把和输入到tf.nn.softmax函数里面.
训练模型
为了训练我们的模型,我们首先需要定义一个指标来评估这个模型是好的.其实,在机器学习,我们通常定义指标来表示一个模型是坏的,这个指标称为成本(cost)或损失(loss),然后尽量最小化这个指标.但是,这两种方式是相同的.
一个非常常见的,非常漂亮的成本函数是“交叉熵”(cross-entropy).定义如下:
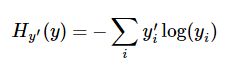
y 是我们预测的概率分布, y’ 是实际的分布(我们输入的 one-hot vector).比较粗糙的理解是,交叉熵是用来衡量我们的预测用于描述真相的低效性.
为了计算交叉熵,我们首先需要添加一个新的占位符用于输入正确值:
y_ = tf.placeholder("float", [None,10])
然后我们可以用 计算交叉熵:
cross_entropy = -tf.reduce_sum(y_*tf.log(y))
首先,用 tf.log 计算 y 的每个元素的对数.接下来,我们把 y_ 的每一个元素和 tf.log(y_) 的对应元素相乘.最后,用 tf.reduce_sum 计算张量的所有元素的总和.(注意,这里的交叉熵不仅仅用来衡量单一的一对预测和真实值,而是所有100幅图片的交叉熵的总和.对于100个数据点的预测表现比单一数据点的表现能更好地描述我们的模型的性能.
现在我们知道我们需要我们的模型做什么啦,用TensorFlow来训练它是非常容易的.因为 TensorFlow 拥有一张描述你各个计算单元的图,它可以自动地使用反向传播算法(backpropagation algorithm)来有效地确定你的变量是如何影响你想要最小化的那个成本值的.然后,TensorFlow 会用你选择的优化算法来不断地修改变量以降低成本.
train_step = tf.train.GradientDescentOptimizer(0.01).minimize(cross_entropy)
在这里,我们要求 TensorFlow 用梯度下降算法(gradient descent algorithm)以0.01的学习速率最小化交叉熵.梯度下降算法(gradient descent algorithm)是一个简单的学习过程,TensorFlow 只需将每个变量一点点地往使成本不断降低的方向移动.
TensorFlow 在这里实际上所做的是,它会在后台给描述你的计算的那张图里面增加一系列新的计算操作单元用于实现反向传播算法和梯度下降算法.然后,它返回给你的只是一个单一的操作,当运行这个操作时,它用梯度下降算法训练你的模型,微调你的变量,不断减少成本.
设置好模型后,在运行计算之前,需要添加一个操作来初始化创建的变量:
init = tf.initialize_all_variables()
现在可以在一个 Session 里面启动模型,并且初始化变量:
sess = tf.Session()
sess.run(init)
然后开始训练模型,这里让模型循环训练1000次!
for i in range(1000):
batch_xs, batch_ys = mnist.train.next_batch(100)
sess.run(train_step, feed_dict={x: batch_xs, y_: batch_ys})
该循环的每个步骤中,我们都会随机抓取训练数据中的100个批处理数据点,然后我们用这些数据点作为参数替换之前的占位符来运行 train_step.
使用一小部分的随机数据来进行训练被称为随机训练(stochastic training)- 在这里更确切的说是随机梯度下降训练.在理想情况下,我们希望用我们所有的数据来进行每一步的训练,因为这能给我们更好的训练结果,但显然这需要很大的计算开销.所以,每一次训练我们可以使用不同的数据子集,这样做既可以减少计算开销,又可以最大化地学习到数据集的总体特性.
评估模型
首先找出那些预测正确的标签.tf.argmax 是一个非常有用的函数,它能给出某个 tensor 对象在某一维上的其数据最大值所在的索引值.由于标签向量是由0,1组成,因此最大值1所在的索引位置就是类别标签,比如 tf.argmax(y,1) 返回的是模型对于任一输入x预测到的标签值,而 tf.argmax(y_,1) 代表正确的标签,我们可以用 tf.equal 来检测我们的预测是否真实标签匹配(索引位置一样表示匹配).
correct_prediction = tf.equal(tf.argmax(y,1), tf.argmax(y_,1))
这行代码会给我们一组布尔值.为了确定正确预测项的比例,我们可以把布尔值转换成浮点数,然后取平均值.例如,[True, False, True, True] 会变成 [1,0,1,1] ,取平均值后得到 0.75.
accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float"))
最后计算所学习到的模型在测试数据集上面的正确率.
print sess.run(accuracy, feed_dict={x: mnist.test.images, y_: mnist.test.labels})
最终结果值应该大约是91%.