CIFAR-10数据集可视化
内容
1.下载数据集
2.可视化数据集
3.ConvnetJS-demo
1.下载数据集
学习深度学习时,需要大量的样本作为支撑,自己找既费时有费精力,搜集的图片还需要进一步做处理,这个工作量也是非常大的。因此,直接使用专门团队做到的数据集,是一个不错的选择。CIFAR的具体由来请参照:https://www.cnblogs.com/neopenx/p/4480701.html.改研究团队提供了10分类的cifar10和4分类的cifar4,大家可以根据自己需要自行下载。
CIFAR的数据集官网提供了不同系统Python、metlab等不同语言的的版本可供下载,连接如下:http://www.cs.toronto.edu/~kriz/cifar.html
从网上下载该数据集,如下载cifar10-python.tar.gz文件,解压包含如下文件:
文件名称 文件大小
data_batch_1.bin 30010KB
data_batch_2.bin 30010KB
data_batch_3.bin 30010KB
data_batch_4.bin 30010KB
data_batch_5.bin 30010KB
test_batch.bin 30010KB
其中 data_batch_1.bin、data_batch_2.bin、data_batch_3.bin、data_batch_4.bin、data_batch_5.bin是训练集,test_batch.bin是测试集。
2.可视化数据集
下载解压后的数据集是通过pickle模块进行处理的,是无法看到里面的图片长什么样的,如图1所示。为了能够看到数据集长什么样的,满足初学者的好奇心,需要反pickle操作,在做可视化处理。
图1
操作系统:WIN7+Pycharm+Python
(1)在Pycharm中新建工程,并将刚才解压后的数据集放入同一目录当中
(2)参看数据集标签代码
新建Python文件,命名cifar,代码1如下
import pickle def load_file(file): with open(file, 'rb') as fo: dict = pickle.load(fo) return dict data = load_file('test_batch') print("test_batch",data.keys())
pickle是一个模块,更多操作请单独查看pickle的操作,在这里只使用到pickle.load函数,该段代码可以显示数据集test_batch中的内容。需要说明的是提供的所有数据集都是以字典形式有CIFAR团队处理好了的。显示结果如下:
![]()
如需要查看其它数据集的内容,可用同样的方法,代码2如下:
import pickle def load_file(file): with open(file, 'rb') as fo: dict = pickle.load(fo) return dict data = load_file('test_batch') print("test_batch",data.keys()) data = load_file('data_batch_1') print("data_batch_1",data.keys()) data = load_file('data_batch_2') print("data_batch_2",data.keys()) data = load_file('data_batch_3') print("data_batch_3",data.keys()) data = load_file('data_batch_4') print("data_batch_4",data.keys()) data = load_file('batches.meta') print("batches.meta",data.keys())
显示结果如下:
('test_batch', ['data', 'labels', 'batch_label', 'filenames'])
('data_batch_1', ['data', 'labels', 'batch_label', 'filenames'])
('data_batch_2', ['data', 'labels', 'batch_label', 'filenames'])
('data_batch_3', ['data', 'labels', 'batch_label', 'filenames'])
('data_batch_4', ['data', 'labels', 'batch_label', 'filenames'])
('batches.meta', ['num_cases_per_batch', 'label_names', 'num_vis'])
(3)可视化操作
上面的代码实现了查看每个训练集和测试集的内容,接下来将实现显示每张图片,更加直观的看到CIFAR团队为我们提供什么的图片。
新建文件,命名cifar_vision,代码3如下:
# -*- coding:utf-8 -*- import pickle as p import numpy as np import matplotlib.pyplot as plt import matplotlib.image as plimg from PIL import Image def load_CIFAR_batch(filename): """ load single batch of cifar """ with open(filename, 'rb')as f: datadict = p.load(f) X = datadict['data'] Y = datadict['labels'] X = X.reshape(10000, 3, 32, 32) Y = np.array(Y) return X, Y def load_CIFAR_Labels(filename): with open(filename, 'rb') as f: lines = [x for x in f.readlines()] print(lines) if __name__ == "__main__": load_CIFAR_Labels("batches.meta") imgX, imgY = load_CIFAR_batch("data_batch_1") print imgX.shape print "正在保存图片:" for i in xrange(imgX.shape[0]): imgs = imgX[i - 1] if i < 100:#只循环100张图片,这句注释掉可以便利出所有的图片,图片较多,可能要一定的时间 img0 = imgs[0] img1 = imgs[1] img2 = imgs[2] i0 = Image.fromarray(img0) i1 = Image.fromarray(img1) i2 = Image.fromarray(img2) img = Image.merge("RGB",(i0,i1,i2)) name = "img" + str(i) plimg.imsave("F://ML/cifar/data/images/" + name +".png", img) # 文件夹下是RGB分离的图像 #img.save("F://ML/cifar/data/images/"+name,"png")#文件夹下是RGB融合后的图像 for j in xrange(imgs.shape[0]): img = imgs[j - 1] name = "img" + str(i) + str(j) + ".png" print "正在保存图片" + name plimg.imsave("F://ML/cifar/data/image/" + name, img)#文件夹下是RGB分离的图像 print "保存完毕."
几点说明:
首先,是自己的文件保存目录,根据自己情况进行修改
其次,data/image和data/images这几个文件夹是自行建立的
代码三运行结束后再image和images分别看到保存的图片,分别如图2和如3所示
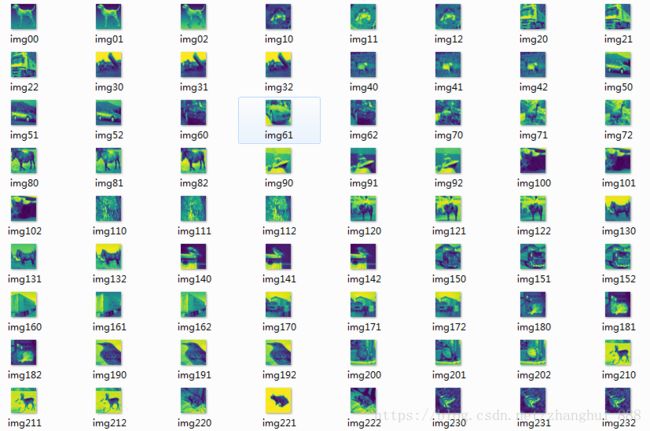
图2 image文件夹中部分图片

图3 images文件夹中部分图片
4.ConvNetJS CIFAR-10 demo
在这里再提供一个可视化的CNN网络,同样是利用cifar10数据集,大家只需要更肥学习率、分类大小就可以自行运行,同时能够下载看到误差以及学习进度。操作界面如图4所示,网址如下:
https://cs.stanford.edu/people/karpathy/convnetjs/demo/cifar10.html

图4 操作界面
在此非常感谢网上大咖提供专业知识,同时非常感谢提供CIFAR数据集的团队。