【Tensorflow】Tensorflow构建LeNet实现手写数字识别
前言
【深度学习】经典卷积神经网络结构说明
前面我们介绍了经典的卷积神经网络的结构,本篇主要是通过Tensorflow构建 LeNet ,并应用于手写数字数据集mnist。
大体部分如下:
- 数据的加载
- 相关参数及输入输出维度的设置
- 模型的图构建(数据的占位符、构建LeNet网络、构建损失函数、优化方式、预测)
- 开启会话(初始化变量、模型保存、模型训练、可视化)
本篇代码可见:Github
一、数据的加载
# 导包
import math
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
# 设置一个随机数种子
tf.set_random_seed(28)
# 数据加载
mnist = input_data.read_data_sets("data/mnist", one_hot=True)
# 手写数字识别的数据集主要包含三个部分:训练集(5.5w, mnist.train)、测试集(1w, mnist.test)、验证集(0.5w, mnist.validation)
# 手写数字图片大小是28*28*1像素的图片(黑白),也就是每个图片由784维的特征描述
train_img = mnist.train.images
train_label = mnist.train.labels
test_img = mnist.test.images
test_label = mnist.test.labels
train_sample_number = mnist.train.num_examples
# 打印数据形状
print(train_img.shape)
print(train_img[0].shape)
print(train_label.shape)
print(test_img.shape)
print(test_label.shape)
print(test_label[0])
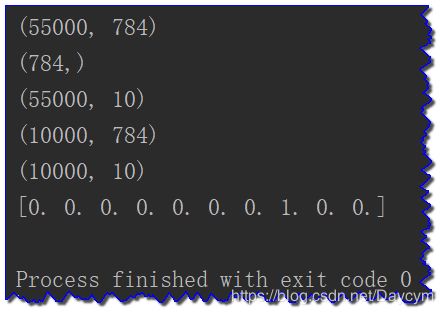
训练集(5.5w, mnist.train)、测试集(1w, mnist.test)
每个手写数字图片大小 28 * 28 * 1 像素的图片(黑白)
二、相关参数及输入输出维度的设置
# 相关的参数、超参数的设置
# 学习率,一般学习率设置的比较小
learn_rate_base = 0.1
# 每次迭代的训练样本数目
batch_size = 64
# 展示信息的间隔大小
display_step = 1
# 输入样本维度大小的信息
input_dim = train_img.shape[1]
# 输出的维度大小
n_classes = train_label.shape[1]
输入样本维度大小为: 28 * 28 = 784
输出的维度大小为分类结果的种类:n_classes,这里是手写数字0到9,10个类别
三、模型的图构建
1、数据的占位符
# 1、设置输入输出数据的占位符
x = tf.placeholder(tf.float32, shape=[None, input_dim], name='x')
# shape第一维设置为None,会根据输入的数据自动给定
y = tf.placeholder(tf.float32, shape=[None, n_classes], name='y')
learn_rate = tf.placeholder(tf.float32, name='learn_rate')
# 根据给定的迭代批次,更新产生一个学习率的值,主要是为了不是使用单一的学习率
def learn_rate_func(epoth):
return max(0.001, learn_rate_base * (0.9 ** int(epoth / 10)))
# 返回一个对应的变量
def get_variable(name, shape=None, dtpye=tf.float32, initializer=tf.random_normal_initializer(mean=0, stddev=0.1)):
return tf.get_variable(name, shape, dtpye, initializer)
2、构建 LeNet 网络
LeNet 网络结构如下:
输入层 -> 卷积层(20个5 * 5 * 1卷积核,28 * 28 * 1) -> 池化层 (2 * 2,14 * 14 * 20)-> 卷积层(50个5 * 5 * 20卷积核,14 * 14 * 50)-> 池化层 (2 * 2,7 * 7 * 50) -> 全连接层(500) -> 全连接层(n_classes)
# 2. 构建网络
def le_net(x, y):
# 1. 输入层
with tf.variable_scope('input1'):
# 将输入的x的格式转换为规定的格式
# [None, input_dim] -> [None, height, weight, channels]
net = tf.reshape(x, shape=[-1, 28, 28, 1])
# 2. 卷积层
with tf.variable_scope('conv2'):
# 卷积
# conv2d(input, filter, strides, padding, use_cudnn_on_gpu=True, data_format="NHWC", name=None) => 卷积的API
# data_format: 表示的是输入的数据格式,两种:NHWC和NCHW,N=>样本数目,H=>Height, W=>Weight, C=>Channels
# input:输入数据,必须是一个4维格式的图像数据,具体格式和data_format有关,如果data_format是NHWC的时候,input的格式为: [batch_size, height, weight, channels] => [批次中的图片数目,图片的高度,图片的宽度,图片的通道数];如果data_format是NCHW的时候,input的格式为: [batch_size, channels, height, weight] => [批次中的图片数目,图片的通道数,图片的高度,图片的宽度]
# filter: 卷积核,是一个4维格式的数据,shape: [height, weight, in_channels, out_channels] => [窗口的高度,窗口的宽度,输入的channel通道数(上一层图片的深度),输出的通道数(卷积核数目)]
# strides:步长,是一个4维的数据,每一维数据必须和data_format格式匹配,表示的是在data_format每一维上的移动步长,当格式为NHWC的时候,strides的格式为: [batch, in_height, in_weight, in_channels] => [样本上的移动大小,高度的移动大小,宽度的移动大小,深度的移动大小],要求在样本上和在深度通道上的移动必须是1;当格式为NCHW的时候,strides的格式为: [batch,in_channels, in_height, in_weight]
# padding: 只支持两个参数"SAME", "VALID",当取值为SAME的时候,表示进行填充,"在TensorFlow中,如果步长为1,并且padding为SAME的时候,经过卷积之后的图像大小是不变的";当VALID的时候,表示多余的特征会丢弃;
net = tf.nn.conv2d(input=net, filter=get_variable('w', [5, 5, 1, 20]), strides=[1, 1, 1, 1], padding='SAME')
net = tf.nn.bias_add(net, get_variable('b', [20]))
# 激励 ReLu
# tf.nn.relu => max(fetures, 0)
# tf.nn.relu6 => min(max(fetures,0), 6)
net = tf.nn.relu(net)
# 3. 池化
with tf.variable_scope('pool3'):
# 和conv2一样,需要给定窗口大小和步长
# max_pool(value, ksize, strides, padding, data_format="NHWC", name=None)
# avg_pool(value, ksize, strides, padding, data_format="NHWC", name=None)
# 默认格式下:NHWC,value:输入的数据,必须是[batch_size, height, weight, channels]格式
# 默认格式下:NHWC,ksize:指定窗口大小,必须是[batch, in_height, in_weight, in_channels], 其中batch和in_channels必须为1
# 默认格式下:NHWC,strides:指定步长大小,必须是[batch, in_height, in_weight, in_channels],其中batch和in_channels必须为1
# padding: 只支持两个参数"SAME", "VALID",当取值为SAME的时候,表示进行填充,;当VALID的时候,表示多余的特征会丢弃;
net = tf.nn.max_pool(value=net, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')
# 4. 卷积
with tf.variable_scope('conv4'):
net = tf.nn.conv2d(input=net, filter=get_variable('w', [5, 5, 20, 50]), strides=[1, 1, 1, 1], padding='SAME')
net = tf.nn.bias_add(net, get_variable('b', [50]))
net = tf.nn.relu(net)
# 5. 池化
with tf.variable_scope('pool5'):
net = tf.nn.max_pool(value=net, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')
# 6. 全连接
with tf.variable_scope('fc6'):
# 28 -> 14 -> 7(因为此时的卷积不改变图片的大小)
size = 7 * 7 * 50
net = tf.reshape(net, shape=[-1, size])
net = tf.add(tf.matmul(net, get_variable('w', [size, 500])), get_variable('b', [500]))
net = tf.nn.relu(net)
# 7. 全连接
with tf.variable_scope('fc7'):
net = tf.add(tf.matmul(net, get_variable('w', [500, n_classes])), get_variable('b', [n_classes]))
return net
# 构建网络
act = le_net(x, y)
# 构建模型的损失函数
# softmax_cross_entropy_with_logits: 计算softmax中的每个样本的交叉熵,logits指定预测值,labels指定实际值
cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=act, labels=y))
# 使用Adam优化方式比较多
# learning_rate: 要注意,不要过大,过大可能不收敛,也不要过小,过小收敛速度比较慢
train = tf.train.AdadeltaOptimizer(learning_rate=learn_rate).minimize(cost)
# 得到预测的类别是那一个
# tf.argmax:对矩阵按行或列计算最大值对应的下标,和numpy中的一样
# tf.equal:是对比这两个矩阵或者向量的相等的元素,如果是相等的那就返回True,反正返回False,返回的值的矩阵维度和A是一样的
pred = tf.equal(tf.argmax(act, axis=1), tf.argmax(y, axis=1))
# 正确率(True转换为1,False转换为0)
acc = tf.reduce_mean(tf.cast(pred, tf.float32))
四、开启会话
# 初始化
init = tf.global_variables_initializer()
with tf.Session() as sess:
# 进行数据初始化
sess.run(init)
# 模型保存、持久化
saver = tf.train.Saver()
epoch = 0
while True:
avg_cost = 0
# 计算出总的批次
total_batch = int(train_sample_number / batch_size)
# 迭代更新
for i in range(total_batch):
# 获取x和y
batch_xs, batch_ys = mnist.train.next_batch(batch_size)
feeds = {x: batch_xs, y: batch_ys, learn_rate: learn_rate_func(epoch)}
# 模型训练
sess.run(train, feed_dict=feeds)
# 获取损失函数值
avg_cost += sess.run(cost, feed_dict=feeds)
# 重新计算平均损失(相当于计算每个样本的损失值)
avg_cost = avg_cost / total_batch
# DISPLAY 显示误差率和训练集的正确率以此测试集的正确率
if (epoch + 1) % display_step == 0:
print("批次: %03d 损失函数值: %.9f" % (epoch, avg_cost))
# 这里之所以使用batch_xs和batch_ys,是因为我使用train_img会出现内存不够的情况,直接就会退出
feeds = {x: train_img[:1000], y: train_label[:1000], learn_rate: learn_rate_func(epoch)}
train_acc = sess.run(acc, feed_dict=feeds)
print("训练集准确率: %.3f" % train_acc)
feeds = {x: test_img, y: test_label, learn_rate: learn_rate_func(epoch)}
test_acc = sess.run(acc, feed_dict=feeds)
print("测试准确率: %.3f" % test_acc)
# 如果训练准确率和测试准确率大于等于0.99停止迭代,并保存模型
if train_acc >= 0.99 and test_acc >= 0.99:
saver.save(sess, './mnist/model_{}_{}'.format(train_acc, test_acc), global_step=epoch)
break
epoch += 1
# 模型可视化输出
writer = tf.summary.FileWriter('./mnist/graph', tf.get_default_graph())
writer.close()
print("end....")

由图可知,模型迭代了98次达到了停止迭代的条件
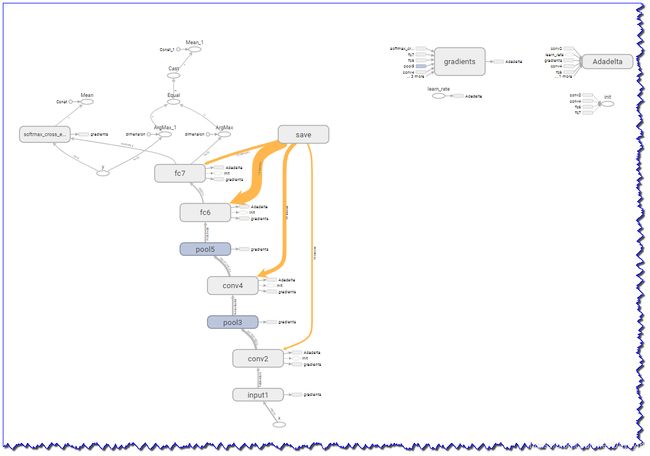
五、模型可视化结果

浏览器输入:http://用户名:6006