论文阅读 --- 小样本学习 --- A CLOSER LOOK AT FEW-SHOT CLASSIFICATION
背景
目前深度学习需要大量的有标签数据,而人类则不需要,能够通过少量的有标签数据样本进行学习分类。在N-shot learning中[1],在训练是有K个类,每个类有N个由标签数据,即一共有N*K个样本来训练,作为 support set S,然后需要对query set Q进行分类,判断属于K类中的哪一类。
N-shot learning有三个子领域,分别是 zero-shot learning,one-shot learning和few-shot learning。
Zero-Shot Learning
没有训练样本,对未看到的样本进行分类。
One-Shot Learning
每个类别仅仅有一个样本进行学习,然后对test set进行分类。
Few-Shot Learning
每个类别有超过一个训练样本 (2-5),进行训练,然后对未知样本进行分类。
该文将Few-Shot Learning分为三类,分为
Model initialization based methods,
metric learning methods以及
hallucination based methods
- 目前方法的问题
1. 各算法实施细节的差异obscures 相对性能提升,对baseline approaches 的方法极大地低估;
2. 训练和预测的类中,即base和novel 类缺少domain shift,使得估计场景不合理
- 本文贡献
1. 为不同的few-shot 分类算法提供统一的testbed,以便于公平的比较。结果表明,当domain difference较小时,增大模型的复杂度(model capacity)使得各algorithm的差别变小;
2. 证明基于距离的分类能够获得competitive performance with the SOTA在mini-ImageNet和CUB数据集上。
3. 对来自不同domains的base 和novel 类进行估计,show目前的few-shot 分类算法不能很好地解决domain shift问题,甚至比baseline method还要差,highlighting 对于domain 差异场景下学习的重要性。
相关工作
给予足够多base classes的训练样本,few-shot目的在于使用有限的有标签数据(a limited number of labeled examples)来识别novel classes。
Initialization based methods
通过 “learning to fine-tune”解决few-shot learning问题,通过学习good model initialization (i.e., the parameters of a network),对于novel classes能够通过有效的有标签数据学习到。另一种通过 “learning an optimizer”(即学习优化器),包括基于LSTM的meta-learner,其使用恶意memory代替随机梯度下降和权重更新机制。
尽管其能通过有限的训练样本获得快速的更新,但该方法处理存在domain shift的base 和novel classes 很大困难。
Distance metric learning based methods
通过“learning to compare”来解决few-shot分类问题,距离测度包括 cosine 相似度,Euclidean distance等。本文比较了三个距离度量方法,表明一个简单的基于距离的模型能够获得competitive performance同其他复杂的算法。
Hallucination based methods
通过“learning to augment”来处理数据缺失,该种方法在base classes中学习一个generator,然后使用这个学习到的generator来hallucinate 新的novel class data for data augmentation。这类方法通过其他few-shot方法结合来学习,如何 metric-based method结合。
overview of few-shot classification algorithm
具有足够的base class labeled data ![]() ,少量有标签的novel class data
,少量有标签的novel class data ![]() ,few-shot的目标是为novel学习分类器。
,few-shot的目标是为novel学习分类器。
(Given abundant base class labeled data ![]() and a small amount of novel class labeled data
and a small amount of novel class labeled data ![]() , the goal of few-shot classification algorithms is to train classifiers for novel classes (unseen during training) with few labeled examples。)
, the goal of few-shot classification algorithms is to train classifiers for novel classes (unseen during training) with few labeled examples。)
预测样本的类别是否一定会在 训练类别中出现??
baseline
baseline模型包含标注的迁移学习过程,pre-training和fine-tuning。
1. 训练阶段

模型比较简单,分为两部分,分别为特征提取![]() (由参数
(由参数 的神经网络构成)和分类器
的神经网络构成)和分类器![]() (由权重矩阵
(由权重矩阵![]() 参数化)组成,其中分类器由线性层
参数化)组成,其中分类器由线性层![]() 和softmax构成
和softmax构成
2. fine-tuning stage
在fine-tuning阶段,固定预训练的网络参数,使用少量的novel classes标签数据训练一个新的分类器。
baseline++
在训练中,减少类内特征提取的方差至关重要,因此,本文改进了baseline模型,引入减少特征中intra-class variations 的方法,得到baseline++。
该方法中,只有分类部分和baseline不一致,具体而言,在预训练和fine-tuning阶段,仍然得到权重矩阵![]() 和
和![]() ,但在分类阶段,重写权重矩阵
,但在分类阶段,重写权重矩阵![]() 为
为![]() ,每个类有d维的权重矢量。在训练阶段,对于每个样本提取特征
,每个类有d维的权重矢量。在训练阶段,对于每个样本提取特征![]() ,分别计算其与每个
,分别计算其与每个![]() 的cos距离,得到相似度分值
的cos距离,得到相似度分值![]() ,其中
,其中![]() ,然后使用softmax归一化相似度分值,得到预测概率。
,然后使用softmax归一化相似度分值,得到预测概率。
这些学习到的权重可认为是prototypes for each class,分类器就是要学习这些prototype。
meta-learning algorithms
分为meta-training 和meta-testing 阶段。
在meta-training阶段,首先随机选择N个类,并且分别从这些类中采样得到小的base support set ![]() 和base query set
和base query set ![]() 。目标是训练一个分类模型M,其能对于
。目标是训练一个分类模型M,其能对于![]() 的样本最小化N-way 预测损失
的样本最小化N-way 预测损失![]() ,分类器M是取决于(is conditioned on )支撑集合
,分类器M是取决于(is conditioned on )支撑集合![]() ,通过从一系列tasks(episodes)中学习,meta-learning能够学习怎么从有限的标签数据学习。
,通过从一系列tasks(episodes)中学习,meta-learning能够学习怎么从有限的标签数据学习。
在meta-testting阶段,所有的novel class 数据![]() 作为novel classes的
作为novel classes的![]() ,分类器M能够适应地预测
,分类器M能够适应地预测![]() 中novel classes。
中novel classes。
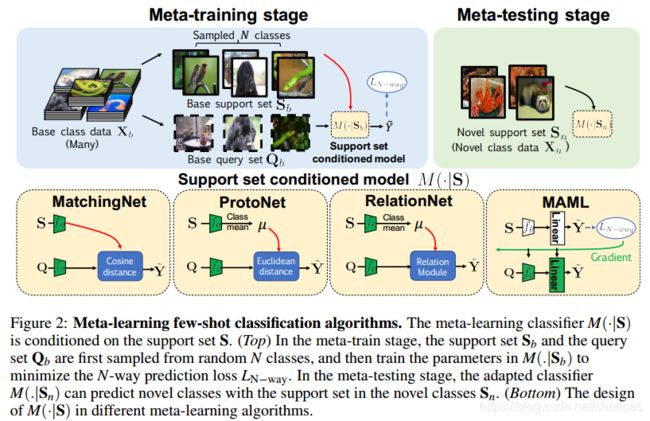
不同的meta-learning学习方法不同,对matchingNet 和protoNet,在query setQ的预测是基于从相同类中的 query feature 和support feature的距离。 matchingNet比较cosine距离,各个类的cosine距离的平均。protoNet比较的是Euclidean 距离。
RelationNet 使用的是一个相关的模块learningable ralation modeule代替distance。
MAML方法是一种基于initialization based的meta-learning的学习算法。首先模型有一个初始化参数initial model,每对support set和query set用其进行更新,具体而言,就是使用support set训练时,更新初始化的参数,得到adapted model,然后利用该模型和query set的label 数据得到loss,次数利用该loss更新initial model,而不是 adapted model。
Ref:
1. https://blog.floydhub.com/n-shot-learning/