异常点检测算法分析与选择
1.1 常见异常点检测算法
在数据库中包含着少数的数据对象,它们与数据的一般行为或特征不一致,这些数据对象叫做异常点 (Outlier) ,也叫做孤立点。异常点的检测和分析是一种十分重要的数据挖掘类型,被称之为异常点挖掘 [28 ] 。
对于异常数据的挖掘主要是使用偏差检测,在数学意义上,偏差是指分类中的反常实例、不满足规则的特例,或者观测结果与模型预测值不一致并随时间的变化的值等等。偏差检测的基本目标是寻找观测结果与参照值之间有意义的差别,主要的偏差技术有聚类、序列异常、最近邻居法、多维数据分析等。除了识别异常数据外,异常数据挖掘还致力于寻找异常数据间隐含模型,用于智能化的分析预测。对于异常数据分析方法的研究是论文的重要内容之一,通过研究异常数据,找到适合出口企业产品质量深入分析和有效监管的方法和策略。
1.1.1 基于统计的异常点检测算法
从 20 世纪 80 年代起,异常检测问题就在统计学领域里得到广泛研究,通常用户用某个统计分布对数据点进行建模,再以假定的模型,根据点的分布来确定是否异常。许许多多针对不同分布的异常测试 (Discordancy Test) 方法发展起来,它们分别适用于不同的情形:①数据分布状况;②数据分布参数是否已知;③异常数据数量;④异常数据类型 ( 高于或低于一般抽样值 ) 。这方面比较有代表性的有 1967 年 Mikey , Dunn & Clark 提出的基于“均数漂移”模型的单点诊断量, 1970 年 Gentleman &Wilk 提出的群组诊断量, 1972 年 Tietjen &Moore 提出的单样本 k 个离群点的统计量 E k , 1985 年 Marasinghe 提出的改进的 E k 统计量 F k , 1989 年 Rosner 提出的单样本多个离群检测算法 ESD(Generalized Extreme Studentized Deviate) 方法, 1991 年 Paul & Fung 改进了 ESD 方法参数 k 选择的主观性,提出了回归分析的 GESR (Generalized Extreme Studentized DeviateResi2dual) 方法。近年来,多样本的离群检测方法也得到了一定的发展,总的思路是先尽量得到一个不含离群点的“干净集”,然后在此基础上对剩余的其他数据点进行逐步离群检测 [29 ] 。
目前利用统计学研究异常点数据有了一些新的方法,如通过分析统计数据的散度情况,即数据变异指标,来对数据的总体特征有更进一步的了解,对数据的分布情况有所了解,进而通过数据变异指标来发现数据中的异常点数据。常用的数据变异指标有极差、四分位数间距、均差、标准差、变异系数等等,变异指标的值大表示变异大、散布广;值小表示离差小,较密集。
基于统计的方法检测出来的离群点很可能被不同的分布模型检测出来,可以说产生这些离群点的机制可能不唯一,解释离群点的意义时经常发生多义性,这是基于统计方法的一个缺陷。其次,基于统计的方法在很大程度上依赖于待挖掘的数据集是否满足某种概率分布模型,模型的参数、离群点的数目等对基于统计的方法都有非常重要的意义,而确定这些参数通常都比较困难。为克服这一问题,一些人提出对数据集进行分布拟合,但分布拟合存在两个问题:①给出的分布可能不适合任一标准分布。②即使存在一个标准分布,分布拟合的过程耗时太长。此外,基于统计的离群检测算法大多只适合于挖掘单变量的数值型数据,目前几乎没有多元的不一致检验,对于大多数的应用来说,例如图像和地理数据,数据集的维数却可能是高维的。实际生活中,以上缺陷都大大限制了基于统计的方法的应用,使得它主要局限于科研计算,算法的可移植性较差。
1.1.2 基于距离的异常点检测算法
用什么标准判定一个数据对象是孤立点呢?即便是对给定的距离量度函数,对孤立点也有不同的定义,以下是使用较多的几个:
l 基于距离的离群点最早是由 Knorr 和 Ng 提出的,他们把记录看作高维空间中的点,离群点被定义为数据集中与大多数点之间的距离都大于某个阈值的点,通常被描述为 DB ( pct , d min ) ,数据集 T 中一个记录 O 称为离群点,当且仅当数据集 T 中至少有 pct 部分的数据与 O 的距离大于 d min 。换一种角度考虑,记 M =N × (1 - pct) ,离群检测即判断与点 O 距离小于 d min 的点是否多于 M 。若是, 则 O 不是离群点,否则 O 是离群点 [4 ][36 ] 。
l 孤立点是数据集中到第 k 个最近邻居的距离最大的 n 个对象 [37 ] 。
l 孤立点是数据集中与其 k 个最近邻居的平均距离最大的 n 个对象 [38 ] 。
基于距离的离群点定义包含并拓展了基于统计的思想,即使数据集不满足任何特定分布模型,它仍能有效地发现离群点,特别是当空间维数比较高时,算法的效率比基于密度的方法要高得多 [39 ] 。算法具体实现时,首先给出记录间距离的度量,常用的是绝对距离 ( 曼哈顿距离 ) 、欧氏距离和马氏距离 [40 ] 。在给出了距离的度量并对数据进行一定的预处理以后,任意给定参数 pct 和 d min 就可以根据离群的定义来检测离群。 Rastogi 和 Ramaswamy 在上面基于距离的离群点定义的基础上,提出改进的基于距离的 k 最近邻 (k - NN ) 离群检测算法 [37 ][41 ][42 ] 。
基于距离的离群检测方法中,算法需要事先确定参数 pct 和 d min ,对于不同的数据集这往往是一件比较困难的事情,特别是 d min ,不同聚类密度的数据集 d min 会有很大的差异,而这一般没有规律可循,因此,对于给定的不同 d min ,异常检测结果通常具有很大的不稳定性 [43 ] 。另一方面,基于距离的方法理论上能处理任意维任意类型的数据,当属性数据为区间标度等非数值属性时,记录之间的距离不能直接确定,通常需要把属性转换为数值型 [37 ][44 ] ,再按定义计算记录之间的距离。当空间的维数大于三维时,由于空间的稀疏性,距离不再具有常规意义,因此很难为异常给出合理的解释。针对这个问题,一些人通过将高维空间映射转换到子空间的办法来解决数据稀疏的问题,此方法在聚类算法中用得比较多 [45 ][46 ] , Agarwal R.[45 ] 等人曾试着用这种投影变换的方法来挖掘离群。总的来说,基于距离的离群检测方法具有比较直观的意义,算法比较容易理解,因此在实际中应用得比较多。
目前比较成熟的基于距离的异常点检测的算法有:
1 .基于索引的算法 (Index-based) :给定一个数据集合,基于索引的算法采用多维索引结构 R- 树, k-d 树等,来查找每个对象在半径 d 范围内的邻居。假设 M 为异常点数据的 d 领域内的最大对象数目。如果对象 O 的 M+l 个邻居被发现,则对象 O 就不是异常点。这个算法在最坏情况下的复杂度为 O(k*n 2 ) , k 为维数, n 为数据集合中对象的数目。当 k 增加时,基于索引的算法具有良好的扩展性 [44 ] 。
2 .嵌套循环算法 (Nested-loop) :嵌套一循环算法和基于索引的算法有相同的计算复杂度,但是它避免了索引结构的构建,试图最小化 I/O 的次数。它把内存的缓冲空间分为两半,把数据集合分为若干个逻辑块。通过精心选择逻辑块装入每个缓冲区域的顺序, I/O 效率能够改善 [44 ] 。
3 .基于单元的算法 (cell-based)[47 ] :在该方法中,数据空间被划为边长等于 d /(2*k 1/2 ) 的单元。每个单元有两个层围绕着它。第一层的厚度是一个单元,而第二层的厚度是 [2*k 1/2 -1] 。该算法逐个单元地对异常点计数,而不是逐个对象地进行计数。对于一个给定的单元,它累计三个计数:单元中对象的数目 (cell_count) 、单元和第一层中对象的数目 (cell_+_1_layer_count) 单元和两个层次中的对象的数目 (cell_+_2_layers_count) 。该算法将对数据集的每一个元素进行异常点数据的检测改为对每一个单元进行异常点数据的检测,它提高了算法的效率。它的算法复杂度是 O(c k +n ) ,这里的 c 是依赖于单元数目的常数, k 是维数。它是这样进行异常检测的:若 cell_+_1_layer_count>M ,单元中的所有对象都不是异常;若 cell_+_2_layers_count<=M ,单元中的所有对象都是异常;否则,单元中的某一些数据可能是异常。为了检测这些异常点,需要逐个对象加入处理。基于距离的异常点检测方法要求用户设置参数 P 和 d ,而寻找这些参数的合适设置可能涉及多次试探和错误。
基于距离的方法与基于统计的方法相比,不需要用户拥有任何领域知识,与序列异常相比,在概念上更加直观。更重要的是,距离异常接近 Hawkins 的异常本质定义。然而,三种类型的基于距离的离群检测算法中,基于索引的算法和循环——嵌套算法需要 O (k *n 2 ) 的时间开销,因此在大数据集中还有待于改进;而基于单元的算法,虽然与 n 具有线性的时间关系,但是它与 k 成指数关系,这限制了它在高维空间中的应用,此外,基于单元的算法还需要事先确定参数 pct , d min 以及单元的大小,这使得算法的可行性比较差;高维空间中,基于索引的方法由于需要事先建立数据集的索引,建立与维护索引也要花大量的时间。因此三种方法对于高维空间中的大数据集,算法的效率都不高 [44 ] 。
1.1.3 基于密度的异常点检测算法
基于密度的离群检测算法一般都建立在距离的基础上,某种意义上可以说基于密度的方法是基于距离的方法中的一种,但基于密度的异常观点比基于距离的异常观点更贴近 Hawkins 的异常定义,因此能够检测出基于距离的异常算法所不能识别的一类异常数据——局部异常。基于密度的方法主要思想是将记录之间的距离和某一给定范围内记录数这两个参数结合起来,从而得到“密度”的概念,然后根据密度判定记录是否为离群点。
Breunig 等人提出的基于局部离群因子的异常检测算法 LOF 是基于密度方法的一个典型例子。它首先产生所有点的 MinPts 邻域及 MinPts 距离,并计算到其中每个点的距离;对低维数据,利用网格进行 k - NN 查询,计算时间为 O (n ) ;对中维或中高维数据,采用如 X2 树等索引结构,使得进行 k2NN 查询的时间为 O (logn ) ,整个计算时间为 O (nlogn ) ;对特高维数据,索引结构不再有效,时间复杂度提高到 O ( n 2 ) 。然后计算每个点的局部异常因子,最后根据局部异常因子来挖掘离群。 LOF 算法中,离群点被定义为相对于全局的局部离群点,这与传统离群的定义不同,离群不再是一个二值属性 ( 要么是离群点,要么是正常点 ) ,它摈弃了以前所有的异常定义中非此即彼的绝对异常观念,更加符合现实生活中的应用。
LOF 算法中充分体现了“局部”的概念,每个点都给出了一个离群程度,离群程度最强的那几个点被标记为离群点。此外, Aggarwal 也提出了一个结合子空间投影变换的基于密度的高维离群检测算法。
1.1.4 基于深度的异常点检测算法
基于深度的离群点检测算法的主要思想是先把每个记录标记为 k 维空间里的一个点,然后根据深度的定义 ( 常用 Peeling Depth Contours 定义 ) 给每个点赋予一个深度值;再根据深度值按层组织数据集,深度值较小的记录是离群点的可能性比深度值较大的记录大得多,因此算法只需要在深度值较小的层上进行离群检测,不需要在深度值大的记录层进行离群检测。基于深度的方法比较有代表性的有 Struyf 和 Rousseeuw 提出的 DEEPLOC 算法。虽然,理论上基于深度的识别算法可以处理高维数据,然而实际计算时, k 维数据的多层操作中,若数据集记录数为 N ,则操作的时间复杂度为Ω (N [k/2 ] ) 。因此,当维数 k ≤ 3 时处理大数据集时还有可能是高效的,而当 k ≥ 4 时,算法的效率就非常低。也就是说,已有的基于深度的离群点检测算法无法挖掘高维数据,只有当 k ≤ 3 时计算效率才是可接受的。
1.1.5 基于偏移的异常点检测算法
基于偏移的离群检测算法 (Deviation-based Outlier Detection) 通过对测试数据集主要特征的检验来发现离群点。目前,基于偏移的检测算法大多都停留在理论研究上,实际应用比较少。以下三种是比较有代表性的 : ① Arning 采用了系列化技术的方法来挖掘离群,由于算法对异常存在的假设太过理想化,因此并没有得到普遍的认同,对于现实复杂数据,其效果不太好,经常遗漏了不少的异常数据 ; ② Sarawagi 应用 OLAP 数据立方体引进了发现驱动的基于偏移的异常检测算法 ; ③ Jagadish 给出了一个高效的挖掘时间序列中异常的基于偏移的检测算法。虽然,基于偏移的离群检测算法理论上可以挖掘各种类型的数据,但是由于要事先知道数据的主要特征,而现实世界中的数据集一方面由于数据量比较大,另一方面由于属性比较多,因此这方面的特征往往不容易发现,当确定记录之间的相异度函数时,如果选择不合适,则得到的离群挖掘结果很可能不尽人意,所以本方法在实际问题中应用得比较少。
基于偏移的异常点检测不采用统计检验或者基于距离的度量值来确定异常对象,它是模仿人类的思维方式,通过观察一个连续序列后,迅速地发现其中某些数据与其它数据明显的不同来确定异常点对象,即使不清楚数据的规则。基于偏移的异常点检测常用两种技术:序列异常技术和 OLAP 数据立方体技术。我们简单介绍序列异常的异常点检测技术。序列异常技术模仿了人类从一系列推测类似的对象中识别异常对象的方式。它利用隐含的数据冗余。给定 n 个对象的集合 S ,它建立一个子集合的序列, {S 1 , S 2 , … , Sm} ,这里 2<= m <=n ,由此,求出子集间的偏离程度,即“相异度”。该算法从集合中选择一个子集合的序列来分析。对于每个子集合,它确定其与序列中前一个子集合的相异度差异。光滑因子最大的子集就是异常数据集。这里对几个相关概念进行解释:
1 .异常集:它是偏离或异常点的集合,被定义为某类对象的最小子集,这些对象的去除会产生剩余集合的相异度的最大减少。
2 .相异度函数:已知一个数据集,如果两个对象相似,相异函数返回值较小,反之,相异函数返回值较大;一个数据子集的计算依赖于前个子集的计算。
3 .基数函数:数据集、数据子集中数据对象的个数。
4 .光滑因子:从原始数据集中去除子集,相异度减小的两度,光滑因子最大的子集就是异常点数据集。
基于偏差的异常点数据的检测方法的时间复杂度通常为 O(n ) , n 为对象个数。基于偏差的异常点检测方法计算性能优异,但由于事先并不知道数据的特性,异常存在的假设太过理想化,因而相异函数的定义较为复杂,对现实复杂数据的效果不太理想。
1.1.6 高维数据的异常点检测算法
以上几种异常检测算法一般都是在低维数据上进行的,对于高维数据的效果并不是很好。与低维空间不同,高维空间中的数据分布得比较稀疏,这使得高维空间中数据之间的距离尺度及区域密度不再具有直观的意义 [48 ] 。基于这个原因, Aggarwal 和 Yu 提出一个高维数据异常检测的方法。它把高维数据集映射到低维子空间,根据子空间映射数据的稀疏程度来确定异常数据是否存在。
|
(4‑ 1 ) |
高维数据的异常点检测的主要思想是:首先它将数据空间的每一维分成小 个等深度区间。所谓等深度区间是指将数据映射到此一维空间上后,每一区间包含相等的 f = 1/ 的数据点。然后在数据集的 k 维子空间中的每一维上各取一个 等深度区间,组成一个 k 维立方体,则立方体中的数据映射点数为一个随机数毛。设 n(D) 为 k 维立方体 D 所包含点数, N 为总的点数。定义稀疏系数 s(D) 如 ( 4‑1 所示:
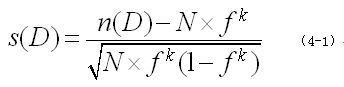
s(D) 为负数时,说明立方体 D 中数据点低于期望值, s(D) 越小,说明该立 方体中数据越稀疏。
数据空间的任一模式可以用 ml m2 … mi … 表示。 mi 指此数据在第 i 维子空间映射区间,可以取值 1 到 ,或者 *( 牢表示可以为任意映射值 ) 。异常检 测问题可以转化成为寻找映射在 k(k 作为参数输入 ) 维子空间上的异常模式以及符合这些异常模式的数据。如 4 维空间中一个映射在 2 维子空间上的模式 ( = 10 ) *3*90 高维数据中寻找异常模式是非常困难的。一个简单办法是对所有数据维进 行组合,来搜索可能异常模式,但是效率极其低下。
1.2 出口产品质量异常检测的思路和算法分析
检疫检疫局监管出口企业生产批质量数据的过程是:首先检验检疫局下发给企业产品出口标准和参数,企业的质量控制人员可以参考此标准和参数组织生产活动,同时将出口产品的某一批次定位生产批,在产品的生产过程,将生产批的质量监控数据上报到检疫检疫局。此生产批将与后期在检验检验局出口报检产品建立对应关系,这样如果出口产品出现问题,检疫检疫执法机构可以通过此种模式的回溯机制定位到此产品生产过程的质量参数。目前企业上报的生产批数据主要是企业自身的质量控制人员手工录入的,数据录入过程中人为因素很大。出口电子监管系统中建立了一套复杂的基于规则标准的监管体系,检疫检疫局认可通过出口电子监管系统综合评定的企业上报的生产批数据,但是对于一些有意钻漏洞的企业,如果其一旦掌握了电子监管系统的评定规则,将对出口产品的质量安全带来新的危险。出口产品质量的异常检测就是在此问题的背景下,借助文中阐述的 OLAM 模型,通过时间序列的相似度查询,找到异常序列。
企业在生产过程中是存在某些时间序列的,其时间序列可能存在一些规律性的变换,例如季节变化产生的植物类食品的周期性变换,企业的生产工艺加工方法造成的周期性变化等等。有些异常点检测的研究主要集中于数据集内单数据点,这一方法在进行欺诈检测、金融监管、可疑交易监控等实际应用过程中出现了误报率高、真正的异常行为模式被掩盖的问题,产生问题的原因是现实生活中各种波动周期的存在 [19 ] 。例如,一个账户连续 11 个月每月存入 5 千元,到第 12 月突然存入 5 万元,基于单数据点比较的离群判别模式将认为该月数据显著异常而报告为离群点,而这 5 万元实际可能是一笔正常的年终奖金。基于时间序列相似度分析的方法则将多个数据点通过时间轴连接成曲线,由点扩展到线,对线与线之间的相似度或差异度进行分析,由此可将孤立事件串联而成有规律的行为模式理解,更能够反映出人们在现实生活中的活动规律。由此可见,电子监管中的出口企业也同样存在这个规律,尤其食品的出口跟时间有着密切的联系。论文中的通过研究不同的异常点检测算法,找到了一种基于时间序列相似度的离群点检测模式。
1.2.1 时间序列相关背景
时间序列由两个基本因素构成:一个是被研究现象所属时间,另一个是反映该现象一定时间条件下数量特征的指标值。
从统计意义上来讲,所谓时间序列就是将某一指标在不同时间上的不同数值,按照时间的先后顺序排序而成的数列。这种数列由于受到各种偶然因素的影响,往往表现出某种随机性,彼此之间存在这统计上的依赖关系。虽然每一个时刻上的取之或数据点的位置具有一定的随机性,不可能完全准确地用历史值来预测将来,但是前后时刻的数值或数据点的相关性往往呈现某种趋势性或周期性变化,这是时间序列挖掘的可行性之所在。时间序列挖掘通过对过去历史行为的客观记录分析,揭示其内在的规律(如波动的周期、振幅、趋势的种类等),进而完成预测未来行为等决策性工作 [30 ] 。
在统计分析中,对时间序列还采取一种简化、直接的分析方法,它没有具体描述被研究现象与其影响因素之间的关系,而是把各影响因素分别看作一种作用力,被研究对象的时间序列则看成合力;然后按作用特点和影响效果将影响因素规为 4 类,即趋势变动( T )、季节变动( S )、循环变动( C )和随机变动( I )。这四种类项的变动叠加在一起,形成了实际观测到的时间序列,因而可以通过对这四种变动形式的考察来研究时间系列的变动
[31 ] 。
在时间序列序列挖掘的研究中,目前比较集中的问题之一是时间序列的快速查询以及相应的存取结构设计。早期的工作着重与精确查找。但是,大多数新型的数据库应用,特别是数据挖掘应用需要数据库具备相似( Similarity )查找能力。对于在几兆,甚至几十兆的时间序列数据库中发现两个模式相似的序列,手工处理很难胜任这样的工作,传统的数据库查找方法也难以完成此类任务,因此时间序列相似性查找成为目前数据挖掘领域的一个新的研究课题。目前国际和国内对时间序列相似度的研究提出了许多种解决方法,这些方法主要包括基于直接距离、傅立叶变换、 ARMA 模型参数法、规范变换、时间弯曲模型、界标模型、神经网络、小波变换、规则推导等。
从理论上来看,基于统计特性描述(如一阶统计量和高阶统计量)或参数建模(如 AR 建模和 ARMA 建模)的传统时间序列分析方法有可能用来解决相似性问题,但实际上并不能得到很好的结果,其主要困难在于相似性度量的定义和算法的时间复杂度,而这两者都依赖于时间序列的近似表示方法。因此,寻求某种鲁棒性强且计算复杂度低的时间序列近似表示方法,一直是解决相似性搜索问题的关键。迄今为止,时间序列相似性搜索问题已经提出了 10 年左右的时间,在这段时间内,先后出现了许多面向相似性搜索的时间序列近似表示方法,如 Agrawal 采用的离散傅立叶变换( DFT , Discrete Fourier Transform) 、 Chan 等人采用的 Haar 小波变换方法、 Last 等人提出的关键特征(如斜率和信噪比)法、 Guralnik 等人提出的字符表方法、 Korn 等人提出的奇异值分解( SVD , Singular Value Decomposition )法、 Keogh 等人先后提出的分段累积近似法( PAA , Piecewise Aggregate Approximation )、分段线性表示( PLR , Piecewise Linear Representation )和适应性分段常数近似法( APCA , Adaptive Piecewise Constant )等分段方法,以及 Perng 等人提出的界标模型( Landmark Model )等。这些表示方法各有所长,为时间序列相似性研究提供了诸多可以借鉴与参考的方向 [32 ] 。本论文通过 OLAM 模型,实现了在 Weka 中基于离散傅里叶变换的时间序列相似性查找方法,通过此异常检查策略的实际应用来展示 OLAM 模型的实用性。
1.2.2 基于离散傅立叶变换的时间序列相似性查找
傅立叶变换是一种重要的积分变换,早已被广泛应用。在时间序列分析方面,离散傅立叶变换具有独特的优点。例如,给定一个时间序列,可以用离散傅立叶变换把其从时域空间变换到频域空间。根据 Parseval 的理论,时域能量函数与频域能量谱函数是等价的。这样就可以把比较时域空间的序列相似性问题转化为比较频域空间的频谱相似性问题。另外,因为频域空间的大部分能量集中前几个系数上,因此可以不考虑离散傅立叶变换得到的其他系数。把这些被保留系数看作从时间序列上提取的特征,这样就可以从每个序列中获得若干(记为 k )特征,进而可以进一步把它们映射到 k 维空间上。这样就可以用一些目前被广泛采用多维索引方法(如 R* 数、 k-D- 树、线性四叉树( Linear Quad tree )、网格文件( Grid - File )),来存储和检索这些多维空间的点 [33 ][34 ] 。
下面描述一下如何进行基于离散傅立叶变换的完全匹配。所谓完全匹配必须保证被查找的序列与给出的序列有相同的长度。因此,与子序列匹配相比,工作就相对简单一些。
1.1.1 完全匹配查找算法
给定一个时间序列 X = {xt|t = 0 , 1 , ... , n-1} ,对 X 进行离散傅立叶变换,得到 ( 4‑2)
这里, X 与 xt 代表时域信息,而 与 Xf 代表频域信息, = {Xf| f = 0 , 1 ,, n - 1} , Xf 为傅立叶系数。
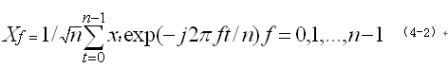
根据 Parserval 的理论,时域能量谱函数与频域能量谱函数相同,得到 4‑ 3 )
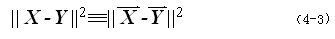
衡量两个序列是否相似的一般方法是用欧氏距离。如果两个序列的欧氏距离小于 的话,则认为这两个序列相似,即满足如下公式:
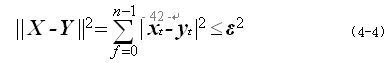
按照 Parserval 的理论,如下式子也应该成立:
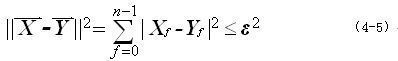
对大多数序列来说,能量集中在傅立叶变换后的前几个系数,也就是说一个信号的高频部分相对来说并不重要。因此我们只取前面 fc
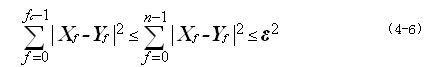
因此

首次筛选所做的工作就是,从提出特征后的频域空间中找出满足上面式子的序列。这样就滤掉一大批与给定序列的距离大于的序列。
在首次筛选后,已经滤掉了一大批与给定序列的距离大于的序列。但是,由于只考虑了前面几个傅立叶系数,所以并不能保证剩余的序列相似。因此,还需要进行最终验证工作,即计算每个首次被选中的序列与给定序列在时域空间的欧氏距离,如果两个序列的欧氏距离小于或等于,则接受该序列。
实践证明,上述完全匹配查找方法非常有效,而且只取 1 ~ 3 个系数就可以达到很好的效果,随着序列数目的增加和序列长度的增加执行效果更好。
1.3 小结
做为论文的一个重要章节,其主要内容是综述和分析异常点检测算法,目的是找到适合检验检验出口产品质量分析的方法和策略。论文综述了目前异常点检测在各个方法领域的发展和其针对的问题域,其中包括了统计的异常点检测、距离的异常点检测、密度的异常点检测、深度的异常点检测、偏离的异常点检测、高维数据的异常点检测。由此可以看出,对于异常点的研究有多种手段和方法,本论文选择电子监管数据中的时间序列做为研究对象。时间序列是一种重要的高维数据类型,它是按照时间顺序观察所得到的一串数据。时间序列的应用日益广泛,其涉及天文、地理、生物、物理、化学等自然科学领域,图像识别、语音处理、声纳技术、遥感技术、机械工程等工程技术领域,以及市场经济、金融分析、人口统计、地震检测等社会经济领域,当前对于时间序列挖掘的研究正得到越来越多的重视。本论文提出对时间序列进行离散傅立叶变换 DFT(Discrete Fourier Transform) ,用 DFT 的前 k 个系数作为原时间序列的表示,其底层的理论依据是数字信号处理领域的 Parseval 定理,该定理保证了时间序列数据的 DFT 变换前几个系数中保存了序列中大部分能量。在实际应用中, DFT 变换对于自然产生的时间序列信号较为适合,但是对于其他来源的时间序列数据则效果不佳。