文章转自:
wind_blast
LDA(Latent dirichlet allocation)[1]是有Blei于2003年提出的三层贝叶斯主题模型,通过无监督的学习方法发现文本中隐含的主题信息,目的是要以无指导学习的方法从文本中发现隐含的语义维度-即“Topic”或者“Concept”。隐性语义分析的实质是要利用文本中词项(term)的共现特征来发现文本的Topic结构,这种方法不需要任何关于文本的背景知识。文本的隐性语义表示可以对“一词多义”和“一义多词”的语言现象进行建模,这使得搜索引擎系统得到的搜索结果与用户的query在语义层次上match,而不是仅仅只是在词汇层次上出现交集。文档、主题以及词可以表示为下图:
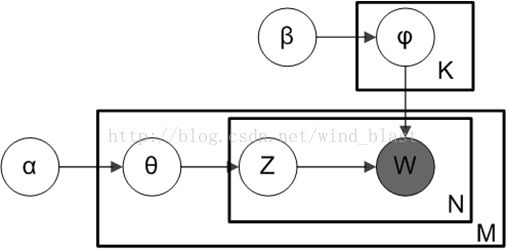
LDA参数:
K为主题个数,M为文档总数, 是第m个文档的单词总数。
是第m个文档的单词总数。 是每个Topic下词的多项分布的Dirichlet先验参数,
是每个Topic下词的多项分布的Dirichlet先验参数,  是每个文档下Topic的多项分布的Dirichlet先验参数。
是每个文档下Topic的多项分布的Dirichlet先验参数。 是第m个文档中第n个词的主题,
是第m个文档中第n个词的主题, 是m个文档中的第n个词。剩下来的两个隐含变量
是m个文档中的第n个词。剩下来的两个隐含变量 和
和 分别表示第m个文档下的Topic分布和第k个Topic下词的分布,前者是k维(k为Topic总数)向量,后者是v维向量(v为词典中term总数)。
分别表示第m个文档下的Topic分布和第k个Topic下词的分布,前者是k维(k为Topic总数)向量,后者是v维向量(v为词典中term总数)。
LDA生成过程:
所谓生成模型,就是说,我们认为一篇文章的每个词都是通过“以一定概率选择了某个主题,并从这个主题中以一定概率选择某个词语”这样一个过程得到。文档到主题服从多项式分布,主题到词服从多项式分布。每一篇文档代表了一些主题所构成的一个概率分布,而每一个主题又代表了很多单词所构成的一个概率分布。

Gibbs Sampling学习LDA:
Gibbs Sampling 是Markov-Chain Monte Carlo算法的一个特例。这个算法的运行方式是每次选取概率向量的一个维度,给定其他维度的变量值Sample当前维度的值。不断迭代,直到收敛输出待估计的参数。初始时随机给文本中的每个单词分配主题}") ,然后统计每个主题z下出现term t的数量以及每个文档m下出现主题z中的词的数量,每一轮计算,即排除当前词的主题分配,根据其他所有词的主题分配估计当前词分配各个主题的概率。当得到当前词属于所有主题z的概率分布后,根据这个概率分布为该词sample一个新的主题
,然后统计每个主题z下出现term t的数量以及每个文档m下出现主题z中的词的数量,每一轮计算,即排除当前词的主题分配,根据其他所有词的主题分配估计当前词分配各个主题的概率。当得到当前词属于所有主题z的概率分布后,根据这个概率分布为该词sample一个新的主题}") 。然后用同样的方法不断更新下一个词的主题,直到发现每个文档下Topic分布和每个Topic下词的分布收敛,算法停止,输出待估计的参数和,最终每个单词的主题也同时得出。实际应用中会设置最大迭代次数。每一次计算的公式称为Gibbs updating rule.下面我们来推导LDA的联合分布和Gibbs updating rule。
。然后用同样的方法不断更新下一个词的主题,直到发现每个文档下Topic分布和每个Topic下词的分布收敛,算法停止,输出待估计的参数和,最终每个单词的主题也同时得出。实际应用中会设置最大迭代次数。每一次计算的公式称为Gibbs updating rule.下面我们来推导LDA的联合分布和Gibbs updating rule。
用Gibbs Sampling 学习LDA参数的算法伪代码如下:

python实现:
- #-*- coding:utf-8 -*-
- import logging
- import logging.config
- import ConfigParser
- import numpy as np
- import random
- import codecs
- import os
- from collections import OrderedDict
- #获取当前路径
- path = os.getcwd()
- #导入日志配置文件
- logging.config.fileConfig("logging.conf")
- #创建日志对象
- logger = logging.getLogger()
- # loggerInfo = logging.getLogger("TimeInfoLogger")
- # Consolelogger = logging.getLogger("ConsoleLogger")
- #导入配置文件
- conf = ConfigParser.ConfigParser()
- conf.read("setting.conf")
- #文件路径
- trainfile = os.path.join(path,os.path.normpath(conf.get("filepath", "trainfile")))
- wordidmapfile = os.path.join(path,os.path.normpath(conf.get("filepath","wordidmapfile")))
- thetafile = os.path.join(path,os.path.normpath(conf.get("filepath","thetafile")))
- phifile = os.path.join(path,os.path.normpath(conf.get("filepath","phifile")))
- paramfile = os.path.join(path,os.path.normpath(conf.get("filepath","paramfile")))
- topNfile = os.path.join(path,os.path.normpath(conf.get("filepath","topNfile")))
- tassginfile = os.path.join(path,os.path.normpath(conf.get("filepath","tassginfile")))
- #模型初始参数
- K = int(conf.get("model_args","K"))
- alpha = float(conf.get("model_args","alpha"))
- beta = float(conf.get("model_args","beta"))
- iter_times = int(conf.get("model_args","iter_times"))
- top_words_num = int(conf.get("model_args","top_words_num"))
- class Document(object):
- def __init__(self):
- self.words = []
- self.length = 0
- #把整个文档及真的单词构成vocabulary(不允许重复)
- class DataPreProcessing(object):
- def __init__(self):
- self.docs_count = 0
- self.words_count = 0
- #保存每个文档d的信息(单词序列,以及length)
- self.docs = []
- #建立vocabulary表,照片文档的单词
- self.word2id = OrderedDict()
- def cachewordidmap(self):
- with codecs.open(wordidmapfile, 'w','utf-8') as f:
- for word,id in self.word2id.items():
- f.write(word +"\t"+str(id)+"\n")
- class LDAModel(object):
- def __init__(self,dpre):
- self.dpre = dpre #获取预处理参数
- #
- #模型参数
- #聚类个数K,迭代次数iter_times,每个类特征词个数top_words_num,超参数α(alpha) β(beta)
- #
- self.K = K
- self.beta = beta
- self.alpha = alpha
- self.iter_times = iter_times
- self.top_words_num = top_words_num
- #
- #文件变量
- #分好词的文件trainfile
- #词对应id文件wordidmapfile
- #文章-主题分布文件thetafile
- #词-主题分布文件phifile
- #每个主题topN词文件topNfile
- #最后分派结果文件tassginfile
- #模型训练选择的参数文件paramfile
- #
- self.wordidmapfile = wordidmapfile
- self.trainfile = trainfile
- self.thetafile = thetafile
- self.phifile = phifile
- self.topNfile = topNfile
- self.tassginfile = tassginfile
- self.paramfile = paramfile
- # p,概率向量 double类型,存储采样的临时变量
- # nw,词word在主题topic上的分布
- # nwsum,每各topic的词的总数
- # nd,每个doc中各个topic的词的总数
- # ndsum,每各doc中词的总数
- self.p = np.zeros(self.K)
- # nw,词word在主题topic上的分布
- self.nw = np.zeros((self.dpre.words_count,self.K),dtype="int")
- # nwsum,每各topic的词的总数
- self.nwsum = np.zeros(self.K,dtype="int")
- # nd,每个doc中各个topic的词的总数
- self.nd = np.zeros((self.dpre.docs_count,self.K),dtype="int")
- # ndsum,每各doc中词的总数
- self.ndsum = np.zeros(dpre.docs_count,dtype="int")
- self.Z = np.array([ [0 for y in xrange(dpre.docs[x].length)] for x in xrange(dpre.docs_count)]) # M*doc.size(),文档中词的主题分布
- #随机先分配类型,为每个文档中的各个单词分配主题
- for x in xrange(len(self.Z)):
- self.ndsum[x] = self.dpre.docs[x].length
- for y in xrange(self.dpre.docs[x].length):
- topic = random.randint(0,self.K-1)#随机取一个主题
- self.Z[x][y] = topic#文档中词的主题分布
- self.nw[self.dpre.docs[x].words[y]][topic] += 1
- self.nd[x][topic] += 1
- self.nwsum[topic] += 1
- self.theta = np.array([ [0.0 for y in xrange(self.K)] for x in xrange(self.dpre.docs_count) ])
- self.phi = np.array([ [ 0.0 for y in xrange(self.dpre.words_count) ] for x in xrange(self.K)])
- def sampling(self,i,j):
- #换主题
- topic = self.Z[i][j]
- #只是单词的编号,都是从0开始word就是等于j
- word = self.dpre.docs[i].words[j]
- #if word==j:
- # print 'true'
- self.nw[word][topic] -= 1
- self.nd[i][topic] -= 1
- self.nwsum[topic] -= 1
- self.ndsum[i] -= 1
- Vbeta = self.dpre.words_count * self.beta
- Kalpha = self.K * self.alpha
- self.p = (self.nw[word] + self.beta)/(self.nwsum + Vbeta) * \
- (self.nd[i] + self.alpha) / (self.ndsum[i] + Kalpha)
- #随机更新主题的吗
- # for k in xrange(1,self.K):
- # self.p[k] += self.p[k-1]
- # u = random.uniform(0,self.p[self.K-1])
- # for topic in xrange(self.K):
- # if self.p[topic]>u:
- # break
- #按这个更新主题更好理解,这个效果还不错
- p = np.squeeze(np.asarray(self.p/np.sum(self.p)))
- topic = np.argmax(np.random.multinomial(1, p))
- self.nw[word][topic] +=1
- self.nwsum[topic] +=1
- self.nd[i][topic] +=1
- self.ndsum[i] +=1
- return topic
- def est(self):
- # Consolelogger.info(u"迭代次数为%s 次" % self.iter_times)
- for x in xrange(self.iter_times):
- for i in xrange(self.dpre.docs_count):
- for j in xrange(self.dpre.docs[i].length):
- topic = self.sampling(i,j)
- self.Z[i][j] = topic
- logger.info(u"迭代完成。")
- logger.debug(u"计算文章-主题分布")
- self._theta()
- logger.debug(u"计算词-主题分布")
- self._phi()
- logger.debug(u"保存模型")
- self.save()
- def _theta(self):
- for i in xrange(self.dpre.docs_count):#遍历文档的个数词
- self.theta[i] = (self.nd[i]+self.alpha)/(self.ndsum[i]+self.K * self.alpha)
- def _phi(self):
- for i in xrange(self.K):
- self.phi[i] = (self.nw.T[i] + self.beta)/(self.nwsum[i]+self.dpre.words_count * self.beta)
- def save(self):
- # 保存theta文章-主题分布
- logger.info(u"文章-主题分布已保存到%s" % self.thetafile)
- with codecs.open(self.thetafile,'w') as f:
- for x in xrange(self.dpre.docs_count):
- for y in xrange(self.K):
- f.write(str(self.theta[x][y]) + '\t')
- f.write('\n')
- # 保存phi词-主题分布
- logger.info(u"词-主题分布已保存到%s" % self.phifile)
- with codecs.open(self.phifile,'w') as f:
- for x in xrange(self.K):
- for y in xrange(self.dpre.words_count):
- f.write(str(self.phi[x][y]) + '\t')
- f.write('\n')
- # 保存参数设置
- logger.info(u"参数设置已保存到%s" % self.paramfile)
- with codecs.open(self.paramfile,'w','utf-8') as f:
- f.write('K=' + str(self.K) + '\n')
- f.write('alpha=' + str(self.alpha) + '\n')
- f.write('beta=' + str(self.beta) + '\n')
- f.write(u'迭代次数 iter_times=' + str(self.iter_times) + '\n')
- f.write(u'每个类的高频词显示个数 top_words_num=' + str(self.top_words_num) + '\n')
- # 保存每个主题topic的词
- logger.info(u"主题topN词已保存到%s" % self.topNfile)
- with codecs.open(self.topNfile,'w','utf-8') as f:
- self.top_words_num = min(self.top_words_num,self.dpre.words_count)
- for x in xrange(self.K):
- f.write(u'第' + str(x) + u'类:' + '\n')
- twords = []
- twords = [(n,self.phi[x][n]) for n in xrange(self.dpre.words_count)]
- twords.sort(key = lambda i:i[1], reverse= True)
- for y in xrange(self.top_words_num):
- word = OrderedDict({value:key for key, value in self.dpre.word2id.items()})[twords[y][0]]
- f.write('\t'*2+ word +'\t' + str(twords[y][1])+ '\n')
- # 保存最后退出时,文章的词分派的主题的结果
- logger.info(u"文章-词-主题分派结果已保存到%s" % self.tassginfile)
- with codecs.open(self.tassginfile,'w') as f:
- for x in xrange(self.dpre.docs_count):
- for y in xrange(self.dpre.docs[x].length):
- f.write(str(self.dpre.docs[x].words[y])+':'+str(self.Z[x][y])+ '\t')
- f.write('\n')
- logger.info(u"模型训练完成。")
- # 数据预处理,即:生成d()单词序列,以及词汇表
- def preprocessing():
- logger.info(u'载入数据......')
- with codecs.open(trainfile, 'r','utf-8') as f:
- docs = f.readlines()
- logger.debug(u"载入完成,准备生成字典对象和统计文本数据...")
- # 大的文档集
- dpre = DataPreProcessing()
- items_idx = 0
- for line in docs:
- if line != "":
- tmp = line.strip().split()
- # 生成一个文档对象:包含单词序列(w1,w2,w3,,,,,wn)可以重复的
- doc = Document()
- for item in tmp:
- if dpre.word2id.has_key(item):# 已有的话,只是当前文档追加
- doc.words.append(dpre.word2id[item])
- else: # 没有的话,要更新vocabulary中的单词词典及wordidmap
- dpre.word2id[item] = items_idx
- doc.words.append(items_idx)
- items_idx += 1
- doc.length = len(tmp)
- dpre.docs.append(doc)
- else:
- pass
- dpre.docs_count = len(dpre.docs) # 文档数
- dpre.words_count = len(dpre.word2id) # 词汇数
- logger.info(u"共有%s个文档" % dpre.docs_count)
- dpre.cachewordidmap()
- logger.info(u"词与序号对应关系已保存到%s" % wordidmapfile)
- return dpre
- def run():
- # 处理文档集,及计算文档数,以及vocabulary词的总个数,以及每个文档的单词序列
- dpre = preprocessing()
- lda = LDAModel(dpre)
- lda.est()
- if __name__ == '__main__':
- run()
参考资料:
lda主题模型
概率语言模型及其变形系列
lda八卦