Keras R语言接口正式发布,同时公开20个完整示例
关于keras的介绍
Keras是一个高层神经网络API,为支持快速实验而生,目前主要功能如下:
-
支持相同的代码无缝跑在CPU或GPU上
-
对用户友好,易于快速prototype深度学习模型
-
支持计算机视觉中的卷积网络、序列处理中的循环网络,也支持两种网络的任意组合
-
支持任意网络架构:多段输入或多段输出模型、层共享、模型共享等。这意味着Keras 本质上适合用于构建任意深度学习模型(从记忆网络到神经图灵机)
-
兼容多种运行后端,例如TensorFlow、CNTK和 Theano
如果你已经很熟悉Keras了,并且想要立刻体验最新发布的R语言接口,请点击如下网址:https://keras.rstudio.com,这里有超过20个完整示例,相信有你需要的东西。
接下来是更多关于Keras的信息,以及发布Keras的R语言接口的意义。
Keras和深度学习
在过去的几年间,人们对深度学习的兴趣增长迅速,同时期出现了几个深度学习的框架。在所有的框架中,Keras因为在生产力、灵活性以及对用户友好性方面的优势脱颖而出。同时期,tensorflow作为下一代机器学习平台,非常灵活,很适合产品部署。
毫不惊讶地说,Keras和tensorflow正在逐渐超过其他深度学习框架。

现在,你不需要纠结该选tensorflow或是Keras了。Keras的默认后端支持通过tensorflow工作流,实现tensorflow和Keras的无缝集成。今年晚些时候,可以通过更深的集成,让Keras完全实现与tensorflow的无缝衔接。
Keras和tensorflow目前都是最顶尖的深度学习框架,有了新发布的Keras包,利用R接口现在可以同时接入两个框架。
使用说明
安装
首先,从CRAN的Keras R包中按照如下步骤安装:
install.packages("keras")
Keras R接口默认使用 TensorFlow后端引擎。使用如下install_keras()函数安装核心Keras库和 TensorFlow后端:
library(keras)
install_keras()()
这个函数默认基于CPU安装Keras和TensorFlow。如果你想要自定义安装,比如说想要利用英伟达GPU,可以查看install_keras()函数的详细文档。
MNIST样例
可以通过实现一个简单的例子来学习Keras的基本知识:识别来自MNIST数据集的手写数字。MNIST由手写数字的28x 28灰度图像组成,如下图所示:

数据集中包含每个图像的标签,来告诉我们这是哪个数字。例如,上面图像中的标签分别是5,0,4,1。
准备数据
MNIST数据集包含在Keras中,可以通过使用dataset_mnist() 函数得到。这个例子中我们先下载数据集,然后为测试和训练数据创造出变量。
library(keras)
mnist <- dataset_mnist()
x_train <- mnist$train$x
y_train <- mnist$train$y
x_test <- mnist$test$x
y_test <- mnist$test$y
x数据是灰度值的3-d数组(图像、宽度、高度)。为了准备训练数据,通过将宽度和高度转换为一维(28x28的图像被简化成长为784的向量),从而把三维数组转换为矩阵。然后,我们将值为0到255的整数之间的灰度值转换成0到1之间的浮点值。
# reshape
dim(x_train) <- c(nrow(x_train), 784)
dim(x_test) <- c(nrow(x_test), 784)
# rescale
x_train <- x_train / 255
x_test <- x_test / 255
y数据是一个整型向量,其值从0到9。为了准备训练数据,我们利用 Keras to_categorical()函数,用one-hot编码方法将向量转化为二进制类矩阵(binary class matrices ):
y_train <- to_categorical(y_train, 10)
y_test <- to_categorical(y_test, 10)
定义模型
我们首先创建一个序贯模型(sequential model),然后使用pipe(%-%)运算符添加层。
model <- keras_model_sequential()
model %>%layer_dense(units = 256, activation = 'relu', input_shape = c(784)) %>%
layer_dropout(rate = 0.4) %>%
layer_dense(units = 128, activation = 'relu') %>%
layer_dropout(rate = 0.3) %>%
layer_dense(units = 10, activation = 'softmax')
使用summary()函数打印出模型的细节:

接下来,用适当的损失函数、优化器和指标来编译模型:
model %>% compile(
loss = 'categorical_crossentropy',
optimizer = optimizer_rmsprop(),
metrics = c('accuracy')
)
训练和评估
使用fit() 函数来训练模型,epochs为30,batch_size为128:
history <- model %>% fit(
x_train, y_train,
epochs = 30, batch_size = 128,
validation_split = 0.2)
可以通过plot(history)绘制出每一步epoch下loss和acc的值:
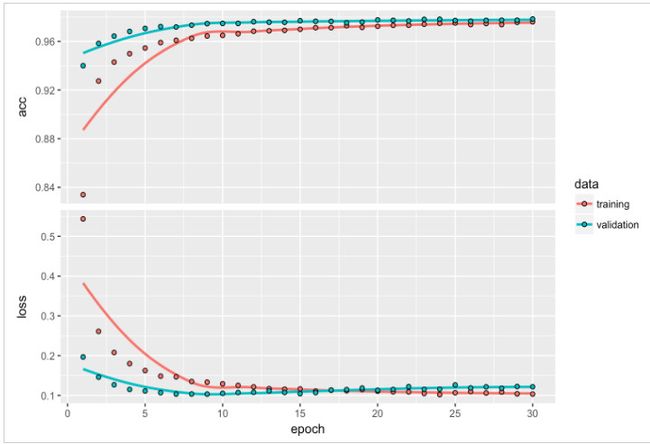
通过测试数据评估模型表现:
model %>% evaluate(x_test, y_test)
$loss
[1] 0.1149
$acc
[1] 0.9807
通过新的数据生成预测值:
model %>% predict_classes(x_test)
