Attention机制学习笔记
Attention机制学习笔记
在这里主要介绍三种attention机制:hard attention、soft attention和self attention。
一、注意力机制
注意力机制(attention mechanism)是机器学习中的一种处理数据的方法,广泛应用于多种单模态、多模态任务中,比如:计算机视觉领域中的目标检测,图像分割等任务,自然语言处理领域中的机器翻译,语义标注等任务,多模态领域中的image captioning、visual question answering等…
在实际生活中,注意力机制和人类的视觉注意力十分相似,在看到一张图片或是一篇文章时,会有选择性的关注场景中最为显眼或者比较重要的部分,也就是说人们对一个场景中的每一个部分给予的注意力是不同的,机器学习中的注意力机制也可以这样解释。
那么attention机制的基本模型是如何进行工作的呢?
实际上attention机智的本质思想是将输入看作是一个
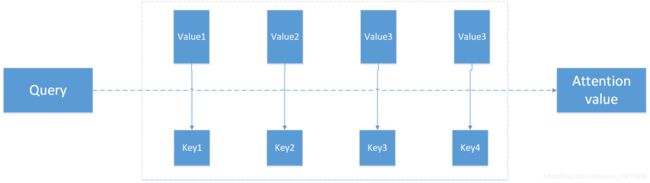
整个attention的过程可大致分为三个步骤:
- 信息输入
- 权重注意力分布计算
- 信息加权和/加权平均计算
第一步:定义输入序列X=[x1,x2,…,xn]
第二步:根据上述对attention机制的描述,我们令key=value=X,计算query和key之间的相似度,经过softmax归一化得到每一个key对应value的权重
![]()
第三步:求出每部分的权值后,对value进行加权和/加权平均得到最终附加了注意力分布的值

下面我们会以encoder-decoder结构为载体对几种注意力机制进行讨论
二、encoder-decoder结构
encoder-decoder框架是一个端到端的学习模型,简单来说就是使用encoder对模型的输入进行编码,得到想要得到的信息作为encoder的输出,之后将encoder的输入传入decoder端进行解码,得到最终结果,下图为一般的encoder-decoder框架图,一个典型的end-to-end模型
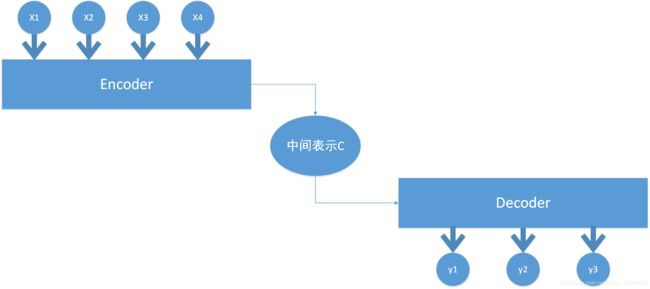
假设输入序列为[x1,x2,x3,x4],经过该框架之后输出为另外一个序列[y1,y2,y3]。encoder端将输入序列编码,通过非线性变换转化为中间语义表示C,而decoder端的任务是根据中间语义表示C以及之前时刻生成的历史信息进行对下一时刻内容的预测并生成
从图中也可以看出无论生成的是y1,y2还是y3,它们都使用的是相同的中间语义表示,没有任何区别。我们以“猫抓老鼠”为例,要输出"Cat catches mouse.",显然在生成Cat这个单词时,输入序列中的“猫”贡献是最大的,但在上图的模型中,生成Cat时输入序列中的每个词的贡献都是相同的,这样显然并不合理,而且在具体的任务中也很可能会影响到整体的性能,尤其是在序列较长时,这个缺点会体现的更加明显
因此我们将注意力机制添加到框架中,使得在生成每一时间步的内容时能够有选择的关注输入序列中的相关部分,而不是一概而论,那么增加了attention机智的框架图如下所示
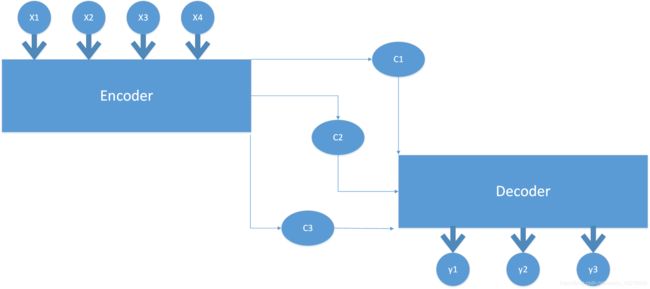
从图中可以看出加入attention机制后通过encoder编码之后的中间表示变成了根据当前生成单词不断变化的Ci,decoder端生成的每个单词都学会其对应的原输入序列中单词的注意力概率分布信息,依旧以“猫抓老鼠”为例,每个Ci对应了原语句中不同单词的注意力分布
C1=g(0.6∗f(′Cat′),0.2∗f(′catches′),0.2∗f(′mouse′))
C2=g(0.2∗f(′Cat′),0.7∗f(′catches′),0.1∗f(′mouse′))
C3=g(0.3∗f(′Cat′),0.2∗f(′catches′),0.5∗f(′mouse′))
以上是encoder-decoder框架中加入attention机制的比对
三、hard attention & soft attention
1.软注意力
在前两个部分介绍的注意力机制属于soft attention,在第一部分中列出了计算过程的注意力机制属于普通模式的软注意力机制,即key=value=X,还有另外一种键值对模式的软注意力机制,即key!=value,这两者之间的区别如下图所示。第二部分中便是将前者融入到了encoder-decoder框架中
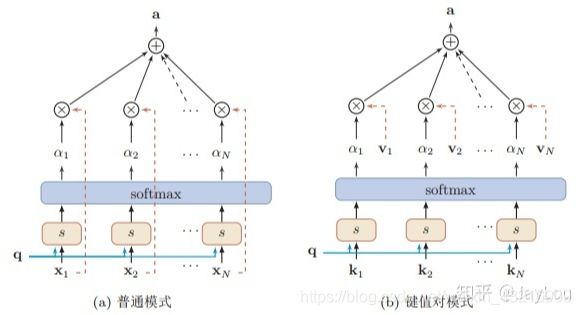
(上图截取自该博客)
2.硬注意力
不同于soft attention对所有信息做注意力分布,hard attention只是关注所有信息中的某一个位置上的信息,它通过对输入序列中的每一部分计算权重以此作为一个抽样率来选择其中的某一个部分作为模型的输入。硬注意力的实现方式有两种:一种是选择拥有最高概率的输入信息;另一种是在注意力分布上做随机采样。
因此不难想到,如果使用hard attention机制实现任务,那么其任务精确度将会受到采样的数量以及质量的影响,而且以采样的方式选择信息会导致最终的损失函数与注意力分布之间的函数关系不可导,无法进行反向传播来训练更新参数
基于以上提出的hard attention的缺点,我们通常为了使用反向传播算法,会采用soft attention来代替hard attention,因此当前阶段soft attention的使用更为普遍。
四、自注意力机制
自注意力机制(self attention)也被称为内部注意力机制,它主要是一个计算单个序列中不同位置之间的相关性的注意力机制。该注意力机制更容易捕获同一个句子中单词之间的一些句法特征或者语义特征,且更容易捕获句子中长距离依赖的特征。它在计算过程中会直接将句子中任意两个单词的联系通过一个计算步骤直接联系起来,所以远距离依赖特征之间的距离被极大缩短,更有利于有效的利用这些特征。
Google 2017年论文Attention is All you need中,为Attention做了一个抽象定义
Self-attention, sometimes called intra-attention is an attention mechanism relating different positions of a single sequence in order to compute a representation of the sequence. Self-attention has been used successfully in a variety of tasks including reading comprehension, abstractive summarization, textual entailment and learning task-independent sentence representations.
自我关注,有时称为内部关注是关联机制,其关联单个序列的不同位置以计算序列的表示。自我关注已经成功地用于各种任务,包括阅读理解,抽象概括,文本蕴涵和学习任务独立的句子表示。
End- to-end memory networks are based on a recurrent attention mechanism instead of sequencealigned recurrence and have been shown to perform well on simple- language question answering and language modeling tasks.
端到端存储器网络基于循环注意机制而不是序列对齐重复,并且已经证明在简单语言问答和语言建模任务上表现良好。
To the best of our knowledge, however, the Transformer is the first transduction model relying entirely on self-attention to compute representations of its input and output without using sequence aligned RNNs or convolution.
然而,据我们所知,变压器是第一个完全依靠自我关注的转换模型来计算其输入和输出的表示,而不使用序列对齐的RNN或卷积。
该文章有两个contribution,其一提出了一个encoder-decoder框架,这个框架仅仅只基于一个周期性的注意力机制堆叠,而不是使用序列对齐循环模型;其二提出了多头注意力机制(Multi-head attention mechanism)的概念,在编解码框架中大量使用多头自注意力机制(Multi-head self-attention mechanism)
下图为文章中提出的encoder-decoder模型结构
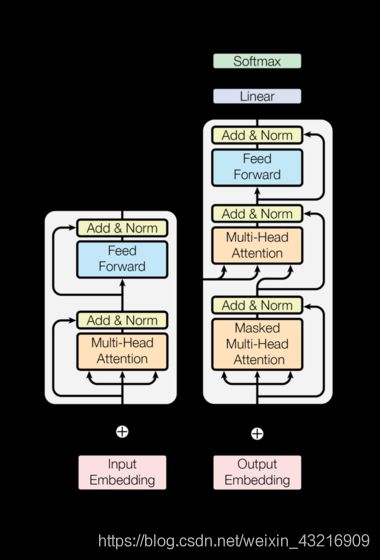
本人就该结构中的各个部分做了理解与分析,有任何问题希望大家指正,欢迎讨论
encoder-decoder结构中的encoder端和decoder端都是由6个相同的层堆叠在一起构建的
encoder端的每一层都包含两个子层,分别是Multi-head self-attention层(多头自注意力机制)和feed-forward层(前馈网络),子层与子层之间通过residual network(残差网络)和normalization(正则化)连接

而decoder端的每一层则包含三个子层,分别是Masked multi-head self-attention、multi-head self-attention和feed-forward network,与encoder端相同,子层与子层之间的连接是通过residual层和norm层来实现的,其中multi-head self-attention层处理encoder端的所有输出

Multi-head attention机制是encoder和decoder端的主要结构,文中展示出的结构图为

其实现过程以及公式如下图所示

Scaled dot-product attention是多头注意力机制中的重要组件,文中展示的结构图为
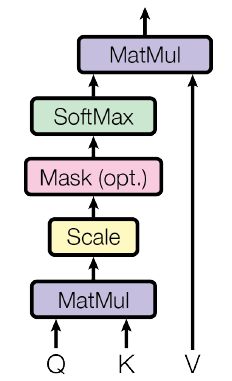
相较于普通的注意力机制,该机制多了一个放缩因子

上述中提到在encoder和decoder中的每一层都包含有多个子层,除了注意力层之外,还包含一层feed-forward network层,该层是有两个线性转换以及一个ReLU激活函数实现
由于文章提出的框架结构中并没有使用任何循环网络和卷积网络,模型无法使用序列的位置信息,即输入序列中每个token之间都是相互独立的,因此作者提出了一种"position encoding",将其与input embedding结合,即最终的embedding包含两部分,input embedding和position encoding

参考博客:
attention 机制
目前主流的attention机制有哪些
Soft/Hard Attention
The Annotated Transformer
self-attention----Attention is all you need论文解读