深度学习文章阅读(二)——VGG
VERY DEEP CONVOLUTIONAL NETWORKS FOR LARGE-SCALE IMAGE CLASSIFICATION
与之前的Alexnet和ZFnet最大的不同是,VGG使用了非常小的卷积核(3x3)。
1 模型结构
模型输入:224x224RGB图像
模型中使用的滤波器具有小的感受野:3x3。
3x3卷积核作用:我们可以发现两个堆叠的3x3(中间不含pooling操作)有着5x5大小的感受野,三个堆叠的3x3卷积核有着7x7大小的感受野。
使用三个堆叠的3x3卷积核相对7x7卷积核的优势:
- 我们执行了三次非线性操作,使得网络判别性更强。
- 参数数量减少,假设输入输出均为C个通道。堆叠的卷积核参数为 3 ( 3 2 C 2 ) = 27 C 2 3(3^{2}C^{2})=27C^{2} 3(32C2)=27C2,7X7卷积核参数为 7 2 C 2 = 49 C 2 7^{2}C^{2}=49C^{2} 72C2=49C2。
我们还使用了1x1的卷积核,这可以看作输入channel的线性组合。
关于1x1卷积核:提高非线性,通过卷积后的激活函数实现。特征降维和升维(本文中没有涉及)。
卷积核stride: 1。
通过空间padding操作保证了在卷积后分辨率不变。
在一系列卷积层后是三个全连接层(Fully-Connected, FC):前两个全连接层均含有4096个通道,第三个全连接层针对1000类分类任务,因此有1000个通道。最后一层为softmax层。
每一层均使用ReLU非线性激活。
2 网络配置
VGG建立了A-E五种网络配置,区别在于1)卷积层的数目,2)是否使用1x1卷积核和3)是否使用LRN操作(Local Response Normalisation)。

各种网络结构包含的参数数目

3 训练
通过最优化多项logistic回归目标函数进行训练。
batch size: 256
SGD+momentum(0.9)。
使用 L 2 L_{2} L2损失函数,乘子为 5 × 1 0 − 4 5\times10^{-4} 5×10−4。
前两层FC使用dropout(ratio: 0.5)。
学习率 1 0 − 2 10^{-2} 10−2。
执行了370次迭代(74个epoch)后停止训练。
模型的初始化:
我们先使用随机初始化训练了配置A。然后用A的前四层卷积层和最后三层FC层进行初始化来训练更深的网络,其他层随机初始化。对于随机初始化,权重初始化为0均值, 1 0 − 2 10^{-2} 10−2的高斯分布,偏置项初始化为0。
训练图片的尺寸:设 S S S为被裁剪图片的最短边。我们考虑两种方法来设置训练scale S S S。第一是固定 S S S,这对应单尺度训练。本文中使用了两种固定的 S S S: s = 256 s=256 s=256和 s = 384 s=384 s=384。第二种设置 S S S的方法被称作多尺度训练。训练图片的S从固定范围 [ S m i n , S m a x ] [S_{min}, S_{max}] [Smin,Smax]中选择。这样的效果是模型可以识别多尺度的目标。
测试图片被裁剪的最短边为Q。
使用多GPU,并且在全尺度图片上进行训练和评估。
4 分类实验
使用ILSVRC-2012数据集,包含130万训练图片,5万张验证图片,10万张测试图片。使用top-1错误率和top-5错误率进行性能评估。
单尺度评估
测试图片的大小:对于固定的S, Q = S Q=S Q=S,对于 S ∈ [ S m i n , S m a x ] S\in[S_{min},S_{max}] S∈[Smin,Smax], Q = 0.5 ( S m i n + S m a x ) Q=0.5(S_{min}+S_{max}) Q=0.5(Smin+Smax)

C比B好,说明增加非线性项对性能确有提升。D比C好,说明通过非平凡的感受野(non-trivial receptive fields)可以获得空间信息。变化的S比固定的S效果好。
多尺度评估
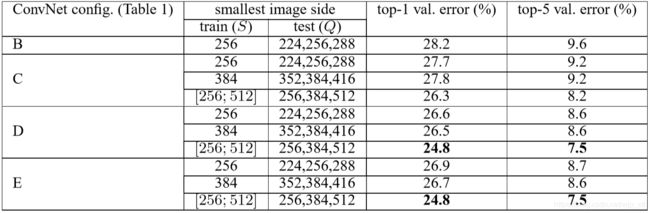
选择测试的尺度 Q = { S m i n , 0.5 ( S m i n + S m a x ) , S m a x } Q=\left \{ S_{min}, 0.5(S_{min}+S_{max}), S_{max}\right \} Q={Smin,0.5(Smin+Smax),Smax}。
使用多尺度的深度配置表现得最好。
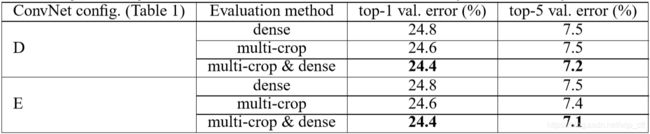
多裁剪方式评估
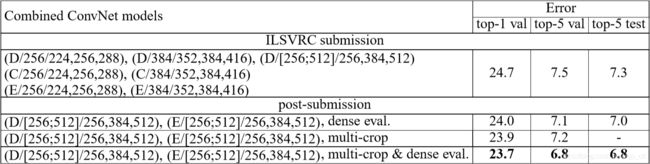
网络融合
我们通过求多个模型的softmax类别后验的平均值将模型结合起来。我们结合两个最好的模型,错误率为7.0%(使用dense)和6.8%(使用dense和multi-crop)。
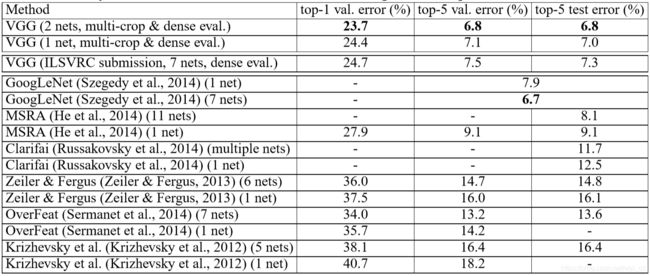
与其他方法的对比
5 附录
定位
定位可以看作是对象检测的一种特殊情况,为每个top-5类别预测一个对象边界框,而不管该类的实际对象数。
我们将VGG的最后一个全连接层预测bounding box的位置,而不再是类别分数。每个bounding box包含一个存储中心坐标,宽度和高度的4维向量组成。bounding box可以在所有的类别中进行预测,也可以只针对一个类别,前者的最后一层为4000维,后者的最后一层为4维。
我们将目标函数由原来的logistic回归目标变为一个欧式距离目标。我们用预训练的分类模型初始化定位模型。
VGG特征的泛化
我们去除最后的全连接层,使用4096维特征作为提取得到的图像特征,我们使用该特征结合L2距离训练SVM分类器。