数据处理之异常值分析、处理
异常值的分析方法
1、简单统计量分析
做一个描述性统计,进而查看哪些数据不合理。最常用的是最大值和最小值,如年龄的最大值199,则存在异常。
2、3σ原则
针对服从正态分布的数据,
![]()
3、箱形图分析(R语言)
首先,读取数据集,用sum(),mean()函数来分别获取缺失样本数、缺失比例。
saledata <- read.csv(file="catering_sale.csv",header = TRUE)
sum(complete.cases(saledata)) #TRUE为1,FALSE为0。结果为非缺失样本数
sum(!complete.cases(saledata)) #结果为缺失样本数
mean(!complete.cases(saledata)) #缺失比例
saledata[!complete.cases(saledata),] #获取缺失值记录然后,进行箱形图分析
sp <- boxplot(saledata$销量,boxwex = 0.7) #画出箱形图,boxwex参数控制箱形的宽度
sd.s <- sd(saledata[complete.cases(saledata),]$销量) #结果是完整样本的标准差
mn.s <- mean(saledata[complete.cases(saledata),]$销量) #结果是完整样本的均值
points(1.1,mn.s,col="red",pch=18) #标出均值点,其中1.1为x轴坐标
arrows(xi,mn.s-sd.s,xi,mn.s+sd.s,code=3,col="pink",angle=75,length=.1) #画出箭头,从均值点到上、下标准差的距离
text(rep(c(1.05,0.95),length(sp$out)/2),sp$out,sp$out,col="red") #标出异常点的值,在点的左边、右边(1.05,0.95)各标示一半。其中sp$out是所有异常值点
最后,结合具体业务,判定哪些点为正常值,哪些点为异常值。
3、箱行图分析(Python)
首先,识别缺失值:
import pandas as pd
data = pd.read_excel('catering_sale.xls',index_col = u'日期') #指定日期列为索引列
data.describe() #查看数据的基本情况输出结果为:
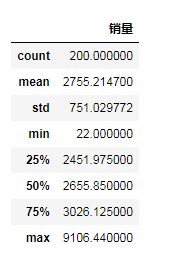
count是非空值数,通过len(data)得到201,所以缺失值数为1。
然后,进行箱形图分析
import pandas as pd
data = pd.read_excel('catering_sale.xls',index_col = u'日期')
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] #正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False #正常显示负号
plt.figure() #建立图像
p = data.boxplot(return_type='dict') #画箱形图,指定返回类型为字典
x = p['fliers'][0].get_xdata() #‘fliers’为异常值的标签
y = p['fliers'][0].get_ydata()
y.sort() #从小到大排序
#用annotate函数添加注释
#其中有些相近的点,注释会出现重叠,需要调试、控制注释的位置
for i in range(len(x)):
if i > 0:
plt.annotate(y[i],xy=(x[i],y[i]),xytext=(x[i]+0.05-0.8/(y[i]-y[i-1]),y[i]))
else:
plt.annotate(y[i],xy=(x[i],y[i]),xytext=(x[i]+0.08,y[i]))
plt.show() #展示箱形图输出结果为:
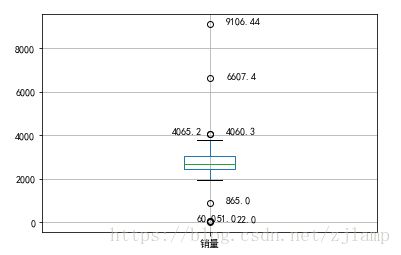
最后,结合具体业务,判定哪些点为正常值,哪些点为异常值。
异常值的处理方法:
1、删除
2、视为缺失值,进行补数
3、平均值修正,可用前后两个观测的平均值修正。
4、不处理