经典论文复现 | ICML 2017大热论文:Wasserstein GAN

过去几年发表于各大 AI 顶会论文提出的 400 多种算法中,公开算法代码的仅占 6%,其中三分之一的论文作者分享了测试数据,约 54% 的分享包含“伪代码”。这是今年 AAAI 会议上一个严峻的报告。 人工智能这个蓬勃发展的领域正面临着实验重现的危机,就像实验重现问题过去十年来一直困扰着心理学、医学以及其他领域一样。最根本的问题是研究人员通常不共享他们的源代码。
可验证的知识是科学的基础,它事关理解。随着人工智能领域的发展,打破不可复现性将是必要的。为此,PaperWeekly 联手百度 PaddlePaddle 共同发起了本次论文有奖复现,我们希望和来自学界、工业界的研究者一起接力,为 AI 行业带来良性循环。
作者丨文永明
学校丨中山大学
研究方向丨计算机视觉,模式识别
最近笔者复现了 Wasserstein GAN,简称 WGAN。Wasserstein GAN 这篇论文来自 Martin Arjovsky 等人,发表于 2017 年 1 月。


论文作者用了两篇论文来阐述 Goodfellow 提出的原始 GAN 所存在的问题,第一篇是 WGAN 前作 Towards Principled Methods for Training Generative Adversarial Networks,从根本上分析 GAN 存在的问题。随后,作者又在 Wasserstein GAN 中引入了 Wasserstein 距离,提出改进的方向,并且给出了改进的算法实现流程。
原始GAN存在的问题
原始的 GAN 很难训练,训练过程通常是启发式的,需要精心设计的网络架构,不具有通用性,并且生成器和判别器的 loss 无法指示训练进程,还存在生成样本缺乏多样性等问题。
在 WGAN 前作中,论文作者分析出原始 GAN 两种形式各自存在的问题,其中一种形式等价于在最优判别器下,最小化生成分布与真实分布之间的 JS 散度。但是对于两个分布:真实分布 Pr 和生成分布 Pg,如果它们不重合,或者重合的部分可以忽略,则它们的 JS 距离![]() 是常数,梯度下降时,会产生的梯度消失。
是常数,梯度下降时,会产生的梯度消失。
而在 GAN 的训练中,两个分布不重合,或者重合可忽略的情况几乎总是出现,交叉熵(JS 散度)不适合衡量具有不相交部分的分布之间的距离,因此导致 GAN 的训练困难。
另一种形式等价于在最优判别器下,既要最小化生成分布与真实分布之间的 KL 散度,又要最大化其 JS 散度,优化目标不合理,导致出现梯度不稳定现象,而且 KL 散度的不对称性也使得出现了 collapse mode 现象,也就是生成器宁可丧失多样性也不愿丧失准确性,生成样本因此缺失多样性。
在 WGAN 前作中,论文作者提出过渡解决方案,通过对真实分布和生成分布增加噪声使得两个分布存在不可忽略的重叠,从理论上解决训练不稳定的问题,但是没有改变本质,治标不治本。
Wasserstein距离
在 WGAN 中论文作者引入了 Wasserstein 距离来替代 JS 散度和 KL 散度,并将其作为优化目标。基于 Wasserstein 距离相对于 KL 散度与 JS 散度具有优越的平滑特性,从根本上解决了原始 GAN 的梯度消失问题。
Wasserstein 距离又叫 Earth-Mover(EM)距离,论文中定义如下:

其中 是指 Pr 和 Pg 组合所有可能的联合分布 γ 的集合,中的每个分布的边缘分布都是 Pr 和 Pg。具体直观地来讲,就是 γ(x,y) 指出需要多少“质量”才能把分布 Pg 挪向 Pr 分布,EM 距离就是路线规划的最优消耗。
是指 Pr 和 Pg 组合所有可能的联合分布 γ 的集合,中的每个分布的边缘分布都是 Pr 和 Pg。具体直观地来讲,就是 γ(x,y) 指出需要多少“质量”才能把分布 Pg 挪向 Pr 分布,EM 距离就是路线规划的最优消耗。
论文作者提出一个简单直观的例子,在这种情况下使用 EM 距离可以收敛但是其他距离下无法收敛,体现出 Wasserstein 距离的优越性。
考虑如下二维空间中 ,令 Z~U[0,1] ,存在两个分布 P0 和 Pθ,在通过原点垂直于 x 轴的线段 α 上均匀分布即 (0,Z),令 Pθ 在线段 β 上均匀分布且垂直于 x 轴,即 (θ,Z),通过控制参数 θ 可以控制着两个分布的距离远近,但是两个分布没有重叠的部分。

很容易得到以下结论:
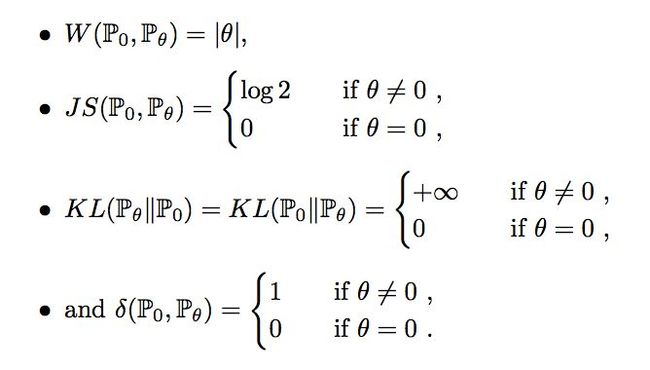
作者用下图详细表达了在上面这个简单例子下的 EM 距离(左图)和 JS 散度(右图)。
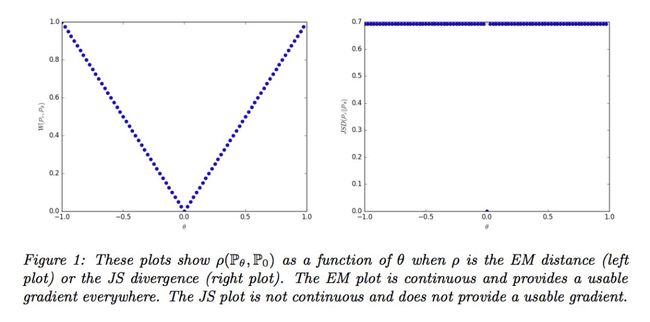
当![]() ,只有 EM 距离是平滑连续的,
,只有 EM 距离是平滑连续的,![]() 在 EM 距离下收敛于 P0,而其他距离是突变的,无法收敛。因此 EM 距离可以在两个分布没有重叠部分的情况下提供有意义的梯度,而其他距离不可以。
在 EM 距离下收敛于 P0,而其他距离是突变的,无法收敛。因此 EM 距离可以在两个分布没有重叠部分的情况下提供有意义的梯度,而其他距离不可以。
Wasserstein GAN算法流程
论文作者写到,可以把 EM 距离用一个式子表示出来:

其中公式 1-Lipschitz 表示函数集。当 f 是一个 Lipschitz 函数时,满足![]() 。当 K=1 时,这个函数就是 1-Lipschitz 函数。
。当 K=1 时,这个函数就是 1-Lipschitz 函数。
特别地,我们用一组参数 ω 来定义一系列可能的 f,通过训练神经网络来优化 ω 拟合逼近在一系列可能的 f 组成函数集,其中![]() 符合 K-Lipschitz 只取决于所有权重参数 ω 的取值范围空间 W,不取决于某个单独的权重参数ω。
符合 K-Lipschitz 只取决于所有权重参数 ω 的取值范围空间 W,不取决于某个单独的权重参数ω。
所以论文作者使用简单粗暴的方法,对每次更新后的神经网络内的权重的绝对值限制在一个固定的常数内,即例如![]() ,就能满足 Lipschitz 条件了。
,就能满足 Lipschitz 条件了。
所以问题转化为,构造一个含参数 ω 判别器神经网络![]() ,为了回归拟合所有可能的 f 最后一层不能是线性激活层,并且限制 ω 在一定常数范围内,最大化
,为了回归拟合所有可能的 f 最后一层不能是线性激活层,并且限制 ω 在一定常数范围内,最大化 ,同时生成器最小化 EM 距离,考虑第一项与生成器无关,所以生成器的损失函数是
,同时生成器最小化 EM 距离,考虑第一项与生成器无关,所以生成器的损失函数是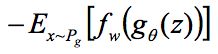 。
。
下面按照笔者的理解来解释一下为什么需要使用 1-Lipschitz 条件,考虑一个简单直观的情况,假设我们现在有两个一维的分布,x1 和 x2 的距离是 d,显然他们之间的 EM 距离也是 d:
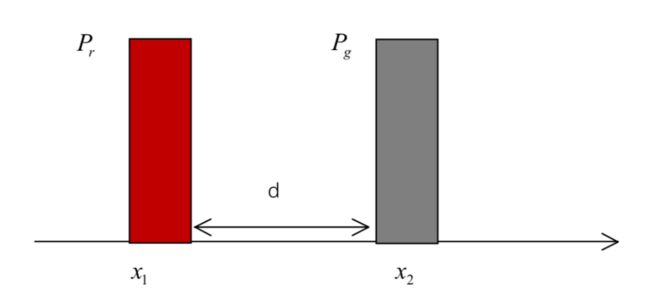
此时按照问题的转化,我们需要最大化 ,只需要让
,只需要让![]() ,且
,且![]() 就可以了,也就是说不使用 1-Lipschitz 限制,只需要让判别器判断 Pr 为正无穷,Pg 为负无穷就可以了。
就可以了,也就是说不使用 1-Lipschitz 限制,只需要让判别器判断 Pr 为正无穷,Pg 为负无穷就可以了。
但是这样的话判别器分类能力太强,生成器很难训练得动,很难使得生成分布向真实分布靠近。而加上了 1-Lipschitz 限制的话,即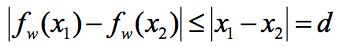 ,最大化 EM 距离,可以让
,最大化 EM 距离,可以让![]() ,且
,且![]() ,这样就把判别器在生成分布和真实分布上的结果限制在了一定范围内,得到一个不太好也不太坏的判别器,继续驱动生成器的生成样本。
,这样就把判别器在生成分布和真实分布上的结果限制在了一定范围内,得到一个不太好也不太坏的判别器,继续驱动生成器的生成样本。
论文中提到加了限制的好处,原始的 GAN 是最终经过 sigmoid 输出的神经网络,在靠近真实分布的附近,函数变化平缓,存在梯度消失现象,而使用了限制的 WGAN 在训练过程可以无差别地提供有意义的梯度。

论文作者给出了如下的完整的 WGAN 算法流程,一方面优化含参数 ω 判别器![]() ,使用梯度上升的方法更新权重参数 ω,并且更新完 ω 后截断在 (-c,c) 的范围内,另一方面优化由参数 θ 控制生成样本的生成器,其中作者发现梯度更新存在不稳定现象,所以不建议使用 Adam 这类基于动量的优化算法,推荐选择 RMSProp、SGD 等优化方法。
,使用梯度上升的方法更新权重参数 ω,并且更新完 ω 后截断在 (-c,c) 的范围内,另一方面优化由参数 θ 控制生成样本的生成器,其中作者发现梯度更新存在不稳定现象,所以不建议使用 Adam 这类基于动量的优化算法,推荐选择 RMSProp、SGD 等优化方法。

实验结果和分析
论文作者认为使用 WGAN 主要有两个优势:
训练过程中有一个有意义的 loss 值来指示生成器收敛,并且这个数值越小代表 GAN 训练得越好,代表生成器产生的图像质量越高;
改善了优化过程的稳定性,解决梯度消失等问题,并且未发现存在生成样本缺乏多样性的问题。
作者指出我们可以清晰地发现 Wasserstein 距离越小,错误率越低,生成质量越高,因此存在指示训练过程的意义。
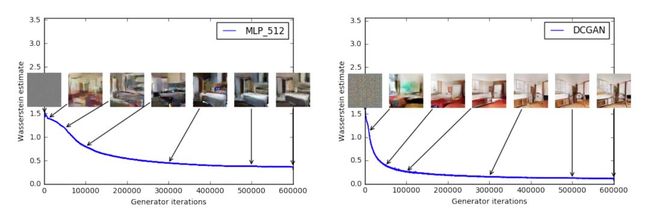
对比与 JS 散度,当模型训练得越好,JS 散度或高或低,与生成样本质量之间无关联,没有意义。

论文实验表明 WGAN 和 DCGAN 都能生成的高质量的样本,左图 WGAN,右图 DCGAN。

而如果都不使用批标准化,左图的 WGAN 生成质量很好,而右图的 DCGAN 生成的质量很差。

如果 WGAN 和 GAN 都是用 MLP,WGAN 生成质量较好,而 GAN 出现样本缺乏多样性的问题。

总结
相比于原始 GAN,WGAN 只需要修改以下四点,就能使得训练更稳定,生成质量更高:
1. 因为这里的判别器相当于做回归任务,所以判别器最后一层去掉 sigmoid;
2. 生成器和判别器的 loss 不取 log;
3. 每次更新判别器的参数之后把它们的绝对值截断到不超过一个固定常数 c;
4. 论文作者推荐使用 RMSProp 等非基于动量的优化算法。
不过,WGAN 还是存在一些问题的:训练困难、收敛速度慢。这源于 weight clipping 的方法太简单粗暴了,导致判别器的参数几乎都集中在最大值和最小值上,相当于一个二值神经网络了,没有发挥深度神经网络的强大拟合能力。不过论文作者在后续 WGAN-GP 中提出梯度惩罚的方法克服了这一缺点。

模型复现
论文复现代码:
http://aistudio.baidu.com/aistudio/#/projectdetail/29022
注:这里笔者使用 MNIST 手写数字数据集进行训练对比。
# 生成器 Generator
def G(z, name="G"):
with fluid.unique_name.guard(name + "/"):
y = z
y = fluid.layers.fc(y, size=1024, act='tanh')
y = fluid.layers.fc(y, size=128 * 7 * 7)
y = fluid.layers.batch_norm(y, act='tanh')
y = fluid.layers.reshape(y, shape=(-1, 128, 7, 7))
y = fluid.layers.image_resize(y, scale=2)
y = fluid.layers.conv2d(y, num_filters=64, filter_size=5, padding=2, act='tanh')
y = fluid.layers.image_resize(y, scale=2)
y = fluid.layers.conv2d(y, num_filters=1, filter_size=5, padding=2, act='tanh')
return y
def D(images, name="D"):
# define parameters of discriminators
def conv_bn(input, num_filters, filter_size):
# w_param_attrs=fluid.ParamAttr(gradient_clip=fluid.clip.GradientClipByValue(CLIP[0], CLIP[1]))
y = fluid.layers.conv2d(
input,
num_filters=num_filters,
filter_size=filter_size,
padding=0,
stride=1,
bias_attr=False)
y = fluid.layers.batch_norm(y)
y = fluid.layers.leaky_relu(y)
return y
with fluid.unique_name.guard(name + "/"):
y = images
y = conv_bn(y, num_filters=32, filter_size=3)
y = fluid.layers.pool2d(y, pool_size=2, pool_stride=2)
y = conv_bn(y, num_filters=64, filter_size=3)
y = fluid.layers.pool2d(y, pool_size=2, pool_stride=2)
y = conv_bn(y, num_filters=128, filter_size=3)
y = fluid.layers.pool2d(y, pool_size=2, pool_stride=2)
y = fluid.layers.fc(y, size=1)
return y
▲ 生成器和判别器代码展示
# 方便显示结果
def printimg(images, epoch=None): # images.shape = (64, 1, 28, 28)
fig = plt.figure(figsize=(5, 5))
fig.suptitle("Epoch {}".format(epoch))
gs = plt.GridSpec(8, 8)
gs.update(wspace=0.05, hspace=0.05)
for i, image in enumerate(images[:64]):
ax = plt.subplot(gs[i])
plt.axis('off')
ax.set_xticklabels([])
ax.set_yticklabels([])
ax.set_aspect('equal')
plt.imshow(image[0], cmap='Greys_r')
plt.show()
batch_size = 128
# MNIST数据集,不使用label
def mnist_reader(reader):
def r():
for img, label in reader():
yield img.reshape(1, 28, 28)
return r
# 噪声生成
def z_g():
while True:
yield np.random.normal(0.0, 1.0, (z_dim, 1, 1)).astype('float32')
mnist_generator = paddle.batch(
paddle.reader.shuffle(mnist_reader(paddle.dataset.mnist.train()), 1024), batch_size=batch_size)
z_generator = paddle.batch(z_g, batch_size=batch_size)()
place = fluid.CUDAPlace(0) if fluid.core.is_compiled_with_cuda() else fluid.CPUPlace()
exe = fluid.Executor(place)
exe.run(startup)
# 测试噪声z
np.random.seed(0)
noise_z = np.array(next(z_generator))
for epoch in range(10):
epoch_fake_loss = []
epoch_real_loss = []
epoch_g_loss = []
for i, real_image in enumerate(mnist_generator()):
# 训练D识别G生成的图片为假图片
r_fake = exe.run(train_d_fake, fetch_list=[fake_loss], feed={
'z': np.array(next(z_generator))
})
epoch_fake_loss.append(np.mean(r_fake))
# 训练D识别真实图片
r_real = exe.run(train_d_real, fetch_list=[real_loss], feed={
'img': np.array(real_image)
})
epoch_real_loss.append(np.mean(r_real))
d_params = get_params(train_d_real, "D")
min_var = fluid.layers.tensor.fill_constant(shape=[1], dtype='float32', value=CLIP[0])
max_var = fluid.layers.tensor.fill_constant(shape=[1], dtype='float32', value=CLIP[1])
# 每次更新判别器的参数之后把它们的绝对值截断到不超过一个固定常数
for pr in d_params:
fluid.layers.elementwise_max(x=train_d_real.global_block().var(pr),y=min_var,axis=0)
fluid.layers.elementwise_min(x=train_d_real.global_block().var(pr),y=max_var,axis=0)
## 训练G生成符合D标准的“真实”图片
r_g = exe.run(train_g, fetch_list=[g_loss], feed={
'z': np.array(next(z_generator))
})
epoch_g_loss.append(np.mean(r_g))
if i % 10 == 0:
print("Epoch {} batch {} fake {} real {} g {}".format(
epoch, i, np.mean(epoch_fake_loss), np.mean(epoch_real_loss), np.mean(epoch_g_loss)
))
# 测试
r_i = exe.run(infer_program, fetch_list=[fake], feed={
'z': noise_z
})
printimg(r_i[0], epoch)
▲ 模型训练代码展示
原始 GAN:

Wasserstein GAN:
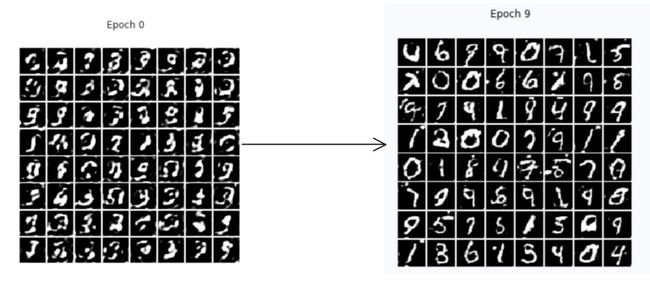
可以看出,WGAN 比原始 GAN 效果稍微好一些,生成质量稍微好一些,更稳定。
关于PaddlePaddle
这是笔者第一次使用 PaddlePaddle 这个开源深度学习框架,框架本身具有易学、易用、安全、高效四大特性,很适合作为学习工具,笔者通过平台的深度学习的视频课程就很快地轻松上手了。
不过,笔者在使用过程中发现 PaddlePaddle 的使用文档比较简单,很多 API 没有详细解释用法,更多的时候需要查看 Github 上的源码来一层一层地了解学习,希望官方的使用文档中能给到更多简单使用例子来帮助我们学习理解,也希望 PaddlePaddle 能越来越好,功能越来越强大。
参考文献
[1] Martin Arjovsky and L´eon Bottou. Towards principled methods for training generative adversarial networks. In International Conference on Learning Representations, 2017. Under review.
[2] M. Arjovsky, S. Chintala, and L. Bottou. Wasserstein gan. arXiv preprint arXiv:1701.07875, 2017.
[3] IshaanGulrajani, FarukAhmed1, MartinArjovsky, VincentDumoulin, AaronCourville. Improved Training of Wasserstein GANs. arXiv preprint arXiv:1704.00028, 2017.
[4] https://zhuanlan.zhihu.com/p/25071913

点击标题查看更多论文复现:
经典论文复现 | 基于深度学习的图像超分辨率重建
经典论文复现 | LSGAN:最小二乘生成对抗网络
PyraNet:基于特征金字塔网络的人体姿态估计
经典论文复现 | InfoGAN:一种无监督生成方法
 #投 稿 通 道#
#投 稿 通 道#
让你的论文被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢? 答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
? 来稿标准:
• 稿件确系个人原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
? 投稿邮箱:
• 投稿邮箱:[email protected]
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
?
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。

▽ 点击 | 阅读原文 | 收藏复现代码