TensorFlow笔记(2)-搭建神经网络
内容概要:
搭建一个简单的神经网络,总结搭建八股。
张量、计算图、会话
- 基于TensorFlow的NN:用张量表示数据集,用计算图搭建神经网络,再用会话执行计算图,优化线上的权重(参数),得到优化后的模型。
- 张量(tensor):可以简单理解为多为数组(列表)
- 阶:张量的维度
如果说TensorFlow的第一个词Tensor表明了它的数据结构,那么Flow则体现了它的计算模型。TensorFlow是一个通过计算图的形式来表述计算的编程系统。TensorFlow中每一个计算都是计算图的一个节点,而节点之间的边描述了计算之间的依赖关系。

- 0阶张量称作标量,表示一个单独的数;举例S=123
- 1阶张量称作向量,表示一个一维数组;举例V=[1,2,3]
- 2阶张量称作矩阵,表示一个二维数组,它可以有i行j列个元素,每个元素可以用行号和列号共同索引到;举例m=[[1, 2, 3], [4, 5, 6], [7, 8,9]]
- 判断张量是几阶的,就通过张量右边的方括号数,0个是0阶,n个是n阶,张量可以表示0阶到n阶数组(列表);举例t=[ [ […] ] ]为3阶。
- 一个张量Tensor中保存了三个属性:名字(Name)、维度(Shape)和类型(Type):
如:Tensor("add:0",shape=(2,),dtype=float32)
- 张量的第一个属性名字不仅是一个张量的唯一标识符,它同样也给出了这个张量是如何计算出来的。
- 张量的第二个属性维度,描述了一个张量的维度信息,如上面所示,shape=(2,),就表示了这是一个1维数组,且长度为2.
- 张量的第三个属性类型,每一个张量都会有一个唯一的类型,TensorFlow编译系统会对参与运算的所有张量进行类型检查,当发现类型不匹配时会报错。
- TensorFlow支持14种不同的类型,主要包含了实数(tf.float32、tf.float64)、整数(tf.int8、tf.int16、tf.int32、tf.int64、tf.uint8)、布尔型(tf.bool)和复数(tf.complex64,tf.complex128)
张量使用主要有两大类:
第一类用途是对中间计算结果的引用。当一个计算包含多个中间结果时,使用张量就可以大大提升代码的可读性。
第二类用途是当计算图构造完成之后,张量可以用来获得计算结果,也就是得到真实的计算数值。
#!/usr/bin/env python
# -*- coding: utf-8 -*
# @Software: PyCharm
import tensorflow as tf
a = tf.constant([1.0, 2.0])
b = tf.constant([3.0, 4.0])
result = a + b
#tensorflow中不能直接使用print()函数,需要使用会话函数session()
sess = tf.Session()
#声明并定义sess为tf.Session()
print(sess.run(result))
【Hint】vim
vim ~/.vimrc #vim 编写python文件设置
set ts=4 #设置tab制表符为4个空格长度
set nu #设置shell命令行显示行号
- 数据类型 TensorFlow的数据类型有tf.float32 、tf.int32等
计算图(Graph):搭建神经网络的计算过程,是承载一个或者多个计算节点的一张图,只搭建网络不进行计算。
我们实现上述计算图:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2019/1/14 4:15 PM
# @Author : HaoWang
# @Site :
# @File : _commit_tf.py
# @Software: PyCharm
import tensorflow as tf #引入模块
x = tf.constant([[1.0, 2.0]]) #定义一个2阶张量等于[[1.0,2.0]]
w = tf.constant([[3.0], [4.0]]) #定义一个2阶张量等于[[3.0],[4.0]]
y = tf.matmul(x, w) #实现矩阵乘法
with tf.Session() as sess: #调用会话,执行计算图中的节点运算
print(sess.run(y))
#运行结果[[11.]]会话(Session)
TensorFlow使用会话来执行定义好的运算,会话拥有并管理TensorFlow程序运行时的所有资源,所有计算完成之后需要关闭会话 来帮助系统回收资源,否则就可能出现内存泄漏等资源泄漏问题。TensorFlow中使用会话的模式一般由两种:
第一种需要明确调用会话生成函数和关闭会话函数,这种模式的代码流程如下:
#创建一个会话Session
sess = tf.Session()
#使用这个创建好的会话来得到关心得运算结果,例如使用sess.run(result)
sess.run(pass)
#关闭会话函数以释放系统资源
sess.close()#或者使用Python 中的with语法创建一个会话
with tf.Session() as sess:
pass如上述代码所示,TensorFlow可以通过Python的上下文管理器来使用会话,当上下文管理器退出时会话也随之关闭,资源释放任务也随之完成,因此使用Python with上下文管理器可以不需要再调用Session.close()函数来关闭会话。
Python 的with上下文管理器用法,请进传送门:https://www.ibm.com/developerworks/cn/opensource/os-cn-pythonwith/index.html
神经网络的参数:
神经网络参数:是指神经元线上的权重W,用变量表示,一般会先随机生成这些参数,生成参数的方法是让W等于tf.Variable,先把生成的方式写在括号内,神经网络中常用的生成随机数or数组的函数有:
- tf.random_normal() 生成正态分布随机数
- tf.truncated_normal() 生成去掉过大偏离点的正太分布随机数
- tf.random_uniform() 生成均匀分布随机数
- tf.zeros 生成全0数组
- tf.ones 生成全1数组
- tf.fill 生成全定值数组
- tf.constant 表示生成直接给定数值的数组
举例
① w=tf.Variable(tf.random_normal([2,3],stddev=2, mean=0, seed=1)),
表示生成正态分布随机数,形状两行三列,标准差是 2,均值是 0,随机种子是 1。
② w=tf.Variable(tf.Truncated_normal([2,3],stddev=2, mean=0, seed=1)),
表示去掉偏离过大的正态分布,也就是如果随机出来的数据偏离平均值超过两个
标准差,这个数据将重新生成。
③ w=random_uniform(shape=7,minval=0,maxval=1,dtype=tf.int32,seed=1),
表示从一个均匀分布[minval maxval)中随机采样,注意定义域是左闭右开,即
包含 minval,不包含 maxval。
④ 除了生成随机数,还可以生成常量。
tf.zeros([3,2],int32)
表示生成[[0,0],[0,0],[0,0]];
tf.ones([3,2],int32)
表示生成[[1,1],[1,1],[1,1];
tf.fill([3,2],6)
表示生成[[6,6],[6,6],[6,6]];
tf.constant([3,2,1])
表示生成[3,2,1]。
注意:①随机种子如果去掉每次生成的随机数将不一致。
②如果没有特殊要求标准差、均值、随机种子是可以不写的。
神经网络的搭建:
当我们知道张量、计算图、会话和参数后,我们可以研究学习神经网络的搭建和实现过程。
实现过程:
- 准备数据集,提取特征,作为输入喂给神经网路(Neural Network,NN);
- 搭建NN结构,从输入到输出(端到端),先搭建计算图再用会话Session()执行计算
(NN前向传播算法———>计算输出);
- 大量的特征数据喂给NN,迭代优化参数
(反向传播算法--------->优化参数训练模型);
- 使用训练好的模型预测和分类。
由此可见,基于神经网络的机器学习主要分为两个过程,即训练过程和使用过程。训练过程是第一步、第二步、第三步的循环迭代过程,使用过程是第四步,一旦参数优化完成就可以固定这些参数,实现特定的应用了。
很多实际的项目中,我们会使用现有的成熟的神经网络结构,喂入数据,训练相应的模型,判断是否能对喂入的从未见过的新的数据做出正确响应,再适当更改网络结构,反复迭代,让机器自动训练参数找出最优结构和最优解,以固定专用模型。
前向传播
前向传播就是搭建模型的计算过程,让模型具有推理能力,可以针对一组输入给出相应的输出。
如:
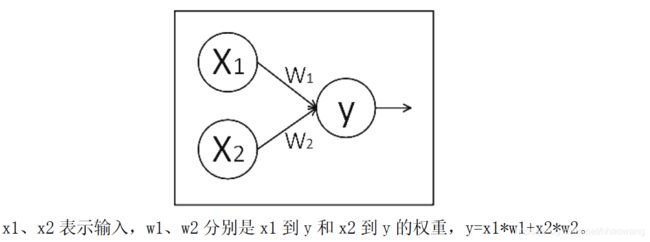
假如生产一批零件,体积为 x1,重量为 x2,体积和重量就是我们选择的特征,把它们喂入神经网络,当体积和重量这组数据走过神经网络后会得到一个输出。
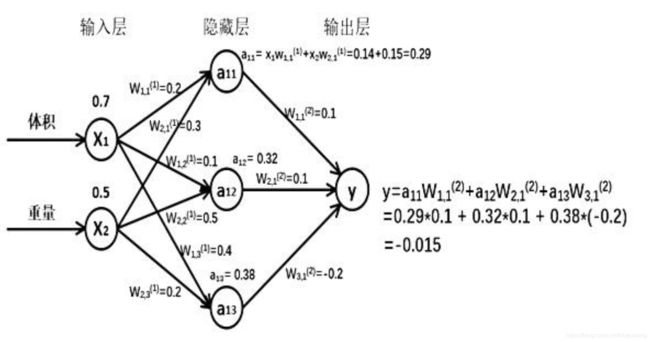
- 第一层:



![]()
【特别提醒】:
- 假设输入层有m个参数,即输入张量维度为2维,矩阵形式表示为1行m列,X=[x1,x2,x3,....xm];
- 假设隐藏层只有一层,该层与输入层之间的权重参数有n个,那么隐藏层的参数的权重W=[[w11,w12,w13,.....w1n],[w21,w22,w23,....w2n],,,,,[wm1,wm2,wm3,.....wmn]]
- 计算得到隐藏层的参数有n个,用一个1行n列的矩阵表示为a[]=X[] * W[]= [a11,a12,a13,....a1n];
- 输出层参数个数等于1,而隐藏层的参数a是1行n列的向量,有n个列分量;第二层(隐藏层到输出层)的权重W`表示为一个1列n行的向量,因此,a[] * W[] = Y


前向传播过程:


#coding:utf-8
#0导入模块,生成模拟数据集。
import tensorflow as tf
import numpy as np
BATCH_SIZE = 8
SEED = 23455
#基于seed产生随机数
rdm = np.random.RandomState(SEED)
#随机数返回32行2列的矩阵 表示32组 体积和重量 作为输入数据集
X = rdm.rand(32,2)
#从X这个32行2列的矩阵中 取出一行 判断如果和小于1 给Y赋值1 如果和不小于1 给Y赋值0
#作为输入数据集的标签(正确答案)
Y_ = [[int(x0 + x1 < 1)] for (x0, x1) in X]
print("X:\n",X)
print("Y_:\n",Y_)
#1定义神经网络的输入、参数和输出,定义前向传播过程。
x = tf.placeholder(tf.float32, shape=(None, 2))
y_= tf.placeholder(tf.float32, shape=(None, 1))
w1= tf.Variable(tf.random_normal([2, 3], stddev=1, seed=1))
w2= tf.Variable(tf.random_normal([3, 1], stddev=1, seed=1))
a = tf.matmul(x, w1)
y = tf.matmul(a, w2)
#2定义损失函数及反向传播方法。
loss_mse = tf.reduce_mean(tf.square(y-y_))
train_step = tf.train.GradientDescentOptimizer(0.001).minimize(loss_mse)
#train_step = tf.train.MomentumOptimizer(0.001,0.9).minimize(loss_mse)
#train_step = tf.train.AdamOptimizer(0.001).minimize(loss_mse)
#3生成会话,训练STEPS轮
with tf.Session() as sess:
init_op = tf.global_variables_initializer()
sess.run(init_op)
# 输出目前(未经训练)的参数取值。
print("w1:\n", sess.run(w1))
print("w2:\n", sess.run(w2))
print("\n")
# 训练模型。
STEPS = 100000
for i in range(STEPS):
start = (i*BATCH_SIZE) % 32
end = start + BATCH_SIZE
sess.run(train_step, feed_dict={x: X[start:end], y_: Y_[start:end]})
if i % 500 == 0:
total_loss = sess.run(loss_mse, feed_dict={x: X, y_: Y_})
print("After %d training step(s), loss_mse on all data is %g" % (i, total_loss))
# 输出训练后的参数取值。
print("\n")
print("w1:\n", sess.run(w1))
print("w2:\n", sess.run(w2))
#
After 0 training step(s), loss_mse on all data is 5.13118
After 500 training step(s), loss_mse on all data is 0.429111
After 1000 training step(s), loss_mse on all data is 0.409789
After 1500 training step(s), loss_mse on all data is 0.399923
After 2000 training step(s), loss_mse on all data is 0.394146
After 2500 training step(s), loss_mse on all data is 0.390597
After 3000 training step(s), loss_mse on all data is 0.388336
After 3500 training step(s), loss_mse on all data is 0.386855
After 4000 training step(s), loss_mse on all data is 0.385863
After 4500 training step(s), loss_mse on all data is 0.385187
After 5000 training step(s), loss_mse on all data is 0.384719
After 5500 training step(s), loss_mse on all data is 0.384391
After 6000 training step(s), loss_mse on all data is 0.38416
After 6500 training step(s), loss_mse on all data is 0.383995
After 7000 training step(s), loss_mse on all data is 0.383877
After 7500 training step(s), loss_mse on all data is 0.383791
After 8000 training step(s), loss_mse on all data is 0.383729
After 8500 training step(s), loss_mse on all data is 0.383684
After 9000 training step(s), loss_mse on all data is 0.383652
After 9500 training step(s), loss_mse on all data is 0.383628
After 10000 training step(s), loss_mse on all data is 0.38361
After 10500 training step(s), loss_mse on all data is 0.383597
After 11000 training step(s), loss_mse on all data is 0.383587
After 11500 training step(s), loss_mse on all data is 0.38358
After 12000 training step(s), loss_mse on all data is 0.383575
After 12500 training step(s), loss_mse on all data is 0.383571
After 13000 training step(s), loss_mse on all data is 0.383568
After 13500 training step(s), loss_mse on all data is 0.383566
After 14000 training step(s), loss_mse on all data is 0.383565
After 14500 training step(s), loss_mse on all data is 0.383564
After 15000 training step(s), loss_mse on all data is 0.383563
After 15500 training step(s), loss_mse on all data is 0.383562
After 16000 training step(s), loss_mse on all data is 0.383562
After 16500 training step(s), loss_mse on all data is 0.383561
After 17000 training step(s), loss_mse on all data is 0.383561
After 17500 training step(s), loss_mse on all data is 0.383561
After 18000 training step(s), loss_mse on all data is 0.383561
After 18500 training step(s), loss_mse on all data is 0.383561
After 19000 training step(s), loss_mse on all data is 0.383561
After 19500 training step(s), loss_mse on all data is 0.383561
After 20000 training step(s), loss_mse on all data is 0.383561
After 20500 training step(s), loss_mse on all data is 0.383561
After 21000 training step(s), loss_mse on all data is 0.383561
After 21500 training step(s), loss_mse on all data is 0.383561
After 22000 training step(s), loss_mse on all data is 0.383561
After 22500 training step(s), loss_mse on all data is 0.383561
After 23000 training step(s), loss_mse on all data is 0.383561
After 23500 training step(s), loss_mse on all data is 0.383561
After 24000 training step(s), loss_mse on all data is 0.383561
After 24500 training step(s), loss_mse on all data is 0.383561
After 25000 training step(s), loss_mse on all data is 0.383561
After 25500 training step(s), loss_mse on all data is 0.383561
After 26000 training step(s), loss_mse on all data is 0.383561
After 26500 training step(s), loss_mse on all data is 0.383561
After 27000 training step(s), loss_mse on all data is 0.383561
After 27500 training step(s), loss_mse on all data is 0.383561
After 28000 training step(s), loss_mse on all data is 0.383561
After 28500 training step(s), loss_mse on all data is 0.383561
After 29000 training step(s), loss_mse on all data is 0.383561
After 29500 training step(s), loss_mse on all data is 0.383561
After 30000 training step(s), loss_mse on all data is 0.383561
After 30500 training step(s), loss_mse on all data is 0.383561
After 31000 training step(s), loss_mse on all data is 0.383561
After 31500 training step(s), loss_mse on all data is 0.383561
After 32000 training step(s), loss_mse on all data is 0.383561
After 32500 training step(s), loss_mse on all data is 0.383561
After 33000 training step(s), loss_mse on all data is 0.383561
After 33500 training step(s), loss_mse on all data is 0.383561
After 34000 training step(s), loss_mse on all data is 0.383561
After 34500 training step(s), loss_mse on all data is 0.383561
After 35000 training step(s), loss_mse on all data is 0.383561
After 35500 training step(s), loss_mse on all data is 0.383561
After 36000 training step(s), loss_mse on all data is 0.383561
After 36500 training step(s), loss_mse on all data is 0.383561
After 37000 training step(s), loss_mse on all data is 0.383561
After 37500 training step(s), loss_mse on all data is 0.383561
After 38000 training step(s), loss_mse on all data is 0.383561
After 38500 training step(s), loss_mse on all data is 0.383561
After 39000 training step(s), loss_mse on all data is 0.383561
After 39500 training step(s), loss_mse on all data is 0.383561
After 40000 training step(s), loss_mse on all data is 0.383561
After 40500 training step(s), loss_mse on all data is 0.383561
After 41000 training step(s), loss_mse on all data is 0.383561
After 41500 training step(s), loss_mse on all data is 0.383561
After 42000 training step(s), loss_mse on all data is 0.383561
After 42500 training step(s), loss_mse on all data is 0.383561
After 43000 training step(s), loss_mse on all data is 0.383561
After 43500 training step(s), loss_mse on all data is 0.383561
After 44000 training step(s), loss_mse on all data is 0.383561
After 44500 training step(s), loss_mse on all data is 0.383561
After 45000 training step(s), loss_mse on all data is 0.383561
After 45500 training step(s), loss_mse on all data is 0.383561
After 46000 training step(s), loss_mse on all data is 0.383561
After 46500 training step(s), loss_mse on all data is 0.383561
After 47000 training step(s), loss_mse on all data is 0.383561
After 47500 training step(s), loss_mse on all data is 0.383561
After 48000 training step(s), loss_mse on all data is 0.383561
After 48500 training step(s), loss_mse on all data is 0.383561
After 49000 training step(s), loss_mse on all data is 0.383561
After 49500 training step(s), loss_mse on all data is 0.383561
After 50000 training step(s), loss_mse on all data is 0.383561
After 50500 training step(s), loss_mse on all data is 0.383561
After 51000 training step(s), loss_mse on all data is 0.383561
After 51500 training step(s), loss_mse on all data is 0.383561
After 52000 training step(s), loss_mse on all data is 0.383561
After 52500 training step(s), loss_mse on all data is 0.383561
After 53000 training step(s), loss_mse on all data is 0.383561
After 53500 training step(s), loss_mse on all data is 0.383561
After 54000 training step(s), loss_mse on all data is 0.383561
After 54500 training step(s), loss_mse on all data is 0.383561
After 55000 training step(s), loss_mse on all data is 0.383561
After 55500 training step(s), loss_mse on all data is 0.383561
After 56000 training step(s), loss_mse on all data is 0.383561
After 56500 training step(s), loss_mse on all data is 0.383561
After 57000 training step(s), loss_mse on all data is 0.383561
After 57500 training step(s), loss_mse on all data is 0.383561
After 58000 training step(s), loss_mse on all data is 0.383561
After 58500 training step(s), loss_mse on all data is 0.383561
After 59000 training step(s), loss_mse on all data is 0.383561
After 59500 training step(s), loss_mse on all data is 0.383561
After 60000 training step(s), loss_mse on all data is 0.383561
After 60500 training step(s), loss_mse on all data is 0.383561
After 61000 training step(s), loss_mse on all data is 0.383561
After 61500 training step(s), loss_mse on all data is 0.383561
After 62000 training step(s), loss_mse on all data is 0.383561
After 62500 training step(s), loss_mse on all data is 0.383561
After 63000 training step(s), loss_mse on all data is 0.383561
After 63500 training step(s), loss_mse on all data is 0.383561
After 64000 training step(s), loss_mse on all data is 0.383561
After 64500 training step(s), loss_mse on all data is 0.383561
After 65000 training step(s), loss_mse on all data is 0.383561
After 65500 training step(s), loss_mse on all data is 0.383561
After 66000 training step(s), loss_mse on all data is 0.383561
After 66500 training step(s), loss_mse on all data is 0.383561
After 67000 training step(s), loss_mse on all data is 0.383561
After 67500 training step(s), loss_mse on all data is 0.383561
After 68000 training step(s), loss_mse on all data is 0.383561
After 68500 training step(s), loss_mse on all data is 0.383561
After 69000 training step(s), loss_mse on all data is 0.383561
After 69500 training step(s), loss_mse on all data is 0.383561
After 70000 training step(s), loss_mse on all data is 0.383561
After 70500 training step(s), loss_mse on all data is 0.383561
After 71000 training step(s), loss_mse on all data is 0.383561
After 71500 training step(s), loss_mse on all data is 0.383561
After 72000 training step(s), loss_mse on all data is 0.383561
After 72500 training step(s), loss_mse on all data is 0.383561
After 73000 training step(s), loss_mse on all data is 0.383561
After 73500 training step(s), loss_mse on all data is 0.383561
After 74000 training step(s), loss_mse on all data is 0.383561
After 74500 training step(s), loss_mse on all data is 0.383561
After 75000 training step(s), loss_mse on all data is 0.383561
After 75500 training step(s), loss_mse on all data is 0.383561
After 76000 training step(s), loss_mse on all data is 0.383561
After 76500 training step(s), loss_mse on all data is 0.383561
After 77000 training step(s), loss_mse on all data is 0.383561
After 77500 training step(s), loss_mse on all data is 0.383561
After 78000 training step(s), loss_mse on all data is 0.383561
After 78500 training step(s), loss_mse on all data is 0.383561
After 79000 training step(s), loss_mse on all data is 0.383561
After 79500 training step(s), loss_mse on all data is 0.383561
After 80000 training step(s), loss_mse on all data is 0.383561
After 80500 training step(s), loss_mse on all data is 0.383561
After 81000 training step(s), loss_mse on all data is 0.383561
After 81500 training step(s), loss_mse on all data is 0.383561
After 82000 training step(s), loss_mse on all data is 0.383561
After 82500 training step(s), loss_mse on all data is 0.383561
After 83000 training step(s), loss_mse on all data is 0.383561
After 83500 training step(s), loss_mse on all data is 0.383561
After 84000 training step(s), loss_mse on all data is 0.383561
After 84500 training step(s), loss_mse on all data is 0.383561
After 85000 training step(s), loss_mse on all data is 0.383561
After 85500 training step(s), loss_mse on all data is 0.383561
After 86000 training step(s), loss_mse on all data is 0.383561
After 86500 training step(s), loss_mse on all data is 0.383561
After 87000 training step(s), loss_mse on all data is 0.383561
After 87500 training step(s), loss_mse on all data is 0.383561
After 88000 training step(s), loss_mse on all data is 0.383561
After 88500 training step(s), loss_mse on all data is 0.383561
After 89000 training step(s), loss_mse on all data is 0.383561
After 89500 training step(s), loss_mse on all data is 0.383561
After 90000 training step(s), loss_mse on all data is 0.383561
After 90500 training step(s), loss_mse on all data is 0.383561
After 91000 training step(s), loss_mse on all data is 0.383561
After 91500 training step(s), loss_mse on all data is 0.383561
After 92000 training step(s), loss_mse on all data is 0.383561
After 92500 training step(s), loss_mse on all data is 0.383561
After 93000 training step(s), loss_mse on all data is 0.383561
After 93500 training step(s), loss_mse on all data is 0.383561
After 94000 training step(s), loss_mse on all data is 0.383561
After 94500 training step(s), loss_mse on all data is 0.383561
After 95000 training step(s), loss_mse on all data is 0.383561
After 95500 training step(s), loss_mse on all data is 0.383561
After 96000 training step(s), loss_mse on all data is 0.383561
After 96500 training step(s), loss_mse on all data is 0.383561
After 97000 training step(s), loss_mse on all data is 0.383561
After 97500 training step(s), loss_mse on all data is 0.383561
After 98000 training step(s), loss_mse on all data is 0.383561
After 98500 training step(s), loss_mse on all data is 0.383561
After 99000 training step(s), loss_mse on all data is 0.383561
After 99500 training step(s), loss_mse on all data is 0.383561
w1:
[[-0.6899801 0.8040343 0.09685706]
[-2.343718 -0.10300428 0.58508235]]
w2:
[[-0.09029248]
[ 0.8035888 ]
[-0.05029974]]反向传播
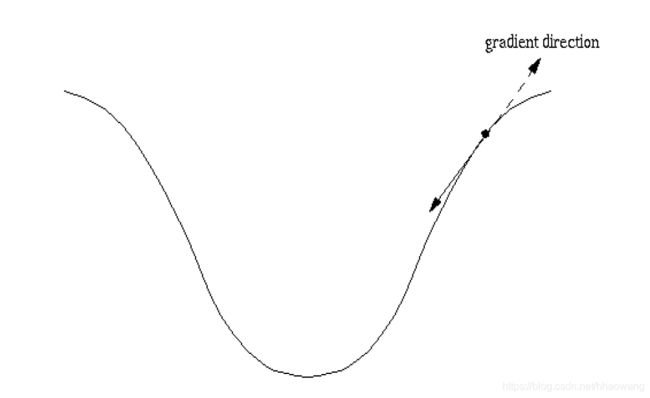
反向传播:训练模型参数,在所有参数上用梯度下降,使NN模型在训练数据上的损失函数最小。
损失函数(loss):计算得到的预测值y与已知答案y_的差距。损失函数的计算有很多方法,均方误差MSE是比较常用的方法之一。
均方误差MSE:求前向传播计算结果与已知答案之差的平方再求平均。

在TensorFlow用函数表示MSE均方误差计算过程:
loss_mse = tf.reduce_mean(tf.square(y_-y))反向传播训练方法:以减小loss值为优化目标,有梯度下降、momentum优化器、adam优化器等优化方法。