MOOC 北京大学 《人工智能实践》 课程笔记(文末有全部代码)
MOOC《人工智能实践》Peking University 笔记
参考资料:https://www.icourse163.org/learn/PKU-1002536002?tid=1002700003#/learn/announce
https://github.com/cj0012/AI-Practice-Tensorflow-Notes
https://tensorflow.google.cn/
第一次自己写博客,结构可能不太好,慢慢改进,加油!!希望大家批评指正,也希望对大家有帮助,谢谢!!!!
2 Linux&Python入门
2.1Linux基本命令
2.1.1进入环境 (Ubuntu18.04 + Python2.7+TensorFlow1.3.0)
- 桌面点击右键 选择Open Terminal
- pwd 打印当前在哪个目录
- ls 列出当前路径下的文件和目录
- mkdir+目录名 新建目录
- cd+目录名 进入到指定的目录
- 输入python 运行Python解释器
- print"Hello World!" 进行测试
2.1.2Python主要语法点(Python2)
- 运算符 + - * / %
- 运算顺序 先乘除 再加减 括号最优先
- 变量 由非数字开头的字母、数字、下划线组成,其内容为数值、字符串、列表、元组、字典
- 数值 即数字 a = 100
- 字符串 用单引号或者双引号引起来的内容
- 转义字符 \t表示tab、\n表示换行、"表示"
- 占位符 用%s占位,用%后的变量进行替换
例如:
a = 100
b = "Hello World!"
print"point = %s\n\"%s\""%(a,b)
应打印出:
point = 100
"Hello World!"
- 列表[]
c = [1,2,3,4,5,6,7]
d = [“张三”,“李四”,“王五”]
e = [1,2,3,“4”,“5”,d] 有数值,有字符串
用列表名[索引号]索引列表中的元素
d[0] = “张三”
用列表名[起:止]表示切片,从列表中切出相应的元素 前闭后开
c[0:2]切出[1,2]
c[:]切出[1,2,3,4,5,6,7] 从头切到尾
用列表名[起:止:步长] 带步长的切片,步长有方向
c = [1,2,3,4,5,6,7]
切出[5,4,3,2]c[4:0:-1]
切出[5,4,3,2,1]c[4::-1]
切出[6,4,2]c[-2::-2]从倒数第二个开始一直到头,步长为-2
修改 列表名[索引号] = 新值
删除 del 列表名[索引号]
插入 列表名.insert(插入位置索引号,新元素)
- 元组() 誓言,一旦定义就不能改变
f=(1,2,3)
- 字典{}
字典里面放着{键:值,键:值,键:值} n个键值对
dic = {1:"123","name":"zhangsan","height":180}
用字典名[键]索引字典中的值
dic["name"] = 'zhangsan'
修改
字典名[键] = 新值
删除
del 字典名[键]
插入
字典名[新键] = 新值
2.3 使用Ubuntu终端中自带编辑器###
- vim文件名 打开或新建文本
- 在vim中 点击i 进入插入格式 可往文本里写内容
- Esc键:q 退出vim
- Esc键:wq 保存更改退出vim
- Esc键:q! 不保存更改退出vim
- 输入中文时一定要在文件开头加上
#coding:utf-8否则出现编码错误
2.3.1 条件语句
- if elif else
- python语句用左对齐表示代码层次
- or 或 不用|
- and 与 不用&
-
= 、<= 、> 、< 、!= 、==
2.4 循环语句
- for 变量 in range(开始值,结束值):
执行某些任务
range 为前闭后开区间 - for 变量 in 列表名:
执行某些任务 - while 条件:
执行某些任务 - 终止循环用break
- 循环嵌套多个for或者while
2.5 turtle模块
import turtle #导入t = turtle.Pen() #用turtle模块中的Pen类,实例化出一个叫做t的对象t.forward(像素点) #让t向前走多少个像素点t.backward(像素点) #让t向后走多少个像素点t.left(角度) #让t左转多少角度t.right(角度) #右转多少角度t.reset() #让t复位
Ubuntu18.04系统一开始没有安装turtle,需要在终端中输入 sudo apt-get install python-tk(python3的话,改为python3即可)
2.6 函数、模块、包
2.6.1 函数
- 函数 执行某些操作的一段代码
input() - 定义函数
def 函数名(参数表):
函数体
- 使用函数: 函数名(参数表)
例子:
定义:def hi_name(yourname):
print "Hello %s"%yourname
使用:hi_name("zhangsan")
输出: Hello zhangsan
- 函数返回值
def add(a,b):
return
c = add(5+6) #c被赋值add的返回值11 - 内建函数(python解释器自带的函数)
abs(-10) #返回10
2.6.2 模块
- 模块:函数的集合,先导入,再使用
使用方法:模块.函数名
import time
time.asctime()
输出:现在的时间
2.6.3 包
- 包:包含有多个模块
from PIL import image
即从PIL包中导入image模块
2.6.4 变量的作用域
- 局部变量 在函数中定义的变量,只在函数中存在,函数执行结果不可再用
- 全局变量 在函数前定义的变量,一般在这个代码最前面定义,全局可用
2.7 类、对象、面向对象的编程
- 类(命名时首字母通常大写)
是函数的集合,可实例化出对象的模具。
具有继承的关系,子类可以使用父类定义的函数与变量。 - 实例化
对象 = 类()
t = turtle.Pen() - 对象
类实例化出的实体,对象实实在在存在,完成具体工作。
例如:上面的t即为对象 - 面向对象
我们反复修改优化类,类实例化出对象,对象调用类里面的函数执行具体的操作。 - 类的定义
class 类名(父类名): #父类名只用写一个父类即可,不用写父类的父类等等
pass - 类里定义函数时,规定第一个参数必须是self
例:
class Animals:
def breathe(self):
print "breathe"
def move(self):
print "moving"
class Mammals(Animals):
def breastfeed(self)
print "feeding young"
class Cats(Mammals):
def __init__(self,spots):
self.spots = spots
-
** __ init __函数,在新对象实例化时会自动运行,用于给新对象赋初值**
例:
kitty = Cats(10) #实例化时默认自动运行__init__函数,给spots赋值,告知kitty有10个斑点
print kitty.spot #打印出10 -
对象调用类里的函数,用对象.函数名;对象调用类里的变量,用对象.变量名
-
类内定义函数时,如调用自身或父类的函数与变量,须用self.引导,应写为self.函数名或self.变量名
例:
class Animals:
def breathe(self):
print "breathe"
def move(self):
print "moving"
class Mammals(Animals):
def breastfeed(self)
print "feeding young"
class Cats(Mammals):
def __init__(self,spots):
self.spots = spots
def catch_mouse(self):
print "catch mouse"
def left_foot_forward(self):
print "left foot forward"
def left_foot_backward(self):
print "left foot backward"
def dance(self):
self.left_foot_forward()
self.left_foot_backward()
运行:
kitty = Cat(10) #首先应该实例化
print kitty.spots
kitty.dance() #自己类的函数
kitty.breastfeed() #父类的函数
kitty.move() #父类继承其父类的函数
2.8 文件操作(import pickle)
2.8.1 文件写操作
1. 开:文件变量 = open(“文件路径文件名”,“wb”)
2. 存:pickle.dump(代写入的变量,文件变量)
3. 关:文件变量.close()
例:game_data = {"position":"N2 E3","pocket":["keys","knife"],"money":160}
save_file = open("save.dat","wb") #写入二进制文件
pickle.dump(game_data,save_file)
save_file.close()
2.8.2 文件读操作
例:
load_file = open("save.dat","rb") #读出二进制文件
load_game_data=pickle.load(load_file)
load_file.close()
结果:load_game_data = {"position":"N2 E3","pocket":["keys","knife"],"money":160}
3 TensorFlow框架
3.1 张量、计算图、会话
基于TensorFlow的NN:用张量表示数据,用计算图搭建神经网络,用会话执行计算图,优化线上的权重(参数),得到模型。
3.1.1 张量(tensor)
- 张量(tensor) 多维数组(列表)
张量可以表示0阶到n阶数组(列表) - 阶 张量的维数
| 维数 | 阶 | 名字 | 例子 |
|---|---|---|---|
| 0-D | 0 | 标量scalar | s = 123 |
| 1-D | 1 | 向量vector | v = [1,2,3] |
| 2-D | 2 | 矩阵matrix | m = [[1,2,3],[4,5,6],[7,8,9]] |
| n-D | n | 张量tensor | t =[[[…]]] n个 |
在命令行中写入:·vim ~/.vimrc
进入编辑界面后写入:set ts = 4
set nu #按Tab键缩进4个字符,并显示行号
- 数据类型:tf.float32 tf.int32
例子:import tensorflow as tf
a = tf.constant([1.0,2.0]) #定义张量常数a
b = tf.constant([3.0,4.0]) #定义张量常数b
result = a + b
print result
显示:Tensor(“add:0”,shape=(2,),dtype=float32) 结果是一个张量
add:节点名
0:第0个输出
shape:维度,2行0列
2:2维数组
dtype:数据类型
其只描述了运算过程,没有显示运算结果
3.1.2 计算图(graph)
- 计算图: 搭建神经网络的计算过程,只搭建,不运算
例子:y = XW = x1w1 + x2w2
import tensorflow as tf
x = tf.constant([[1.0,2.0]]) #定义张量常数x
w = tf.constant([[3.0],[4.0]]) #定义张量常数w
y = tf.matmul(x,w)
print y
显示:Tensor(“matmul:0”,shape(1,1),dtype=float32)
即y为张量 且为1行1列的张量
####3.1.3 会话(session)####
- 会话: 执行计算图中的节点运算
with tf.Session() as sess:
print sess.run(y) #1.0*3.0+2.0*4.0 = 11.0
显示:[[11.]]
3.2 前向传播
- 参数:线上的权重W,用变量表示,随机给初值
w = tf.Variable(tf.random_normal([2,3],stddev=2,mean=0,seed=1))
其中的tf.random_normal():正态分布,tf.truncated_normal()去掉过大偏离点的正态分布,tf.random_uniform()平均分布。
[2,3]产生2*3矩阵,stddev标准差为2,mean均值为0,seed随机种子- tf.zeros 全0数组
tf.zeros([3,2],int32)生成[[0,0],[0,0],[0,0]] - tf.ones 全1数组
tf.ones([3,2],int32)生成[[1,1],[1,1],[1,1]] - tf.fill 全定值数组
tf.fill([3,2],6)生成[[6,6],[6,6],[6,6]] - tf.constant 直接给值
tf.constant([3,2,1])生成[3,2,1]
3.2.1 神经网络的实现过程
- 准备数据集,提取特征,作为输入喂给神经网络(Neural Network,NN)
- 搭建NN结构,从输入到输出(先搭建计算图,再用会话执行)
(NN前向传播算法–>计算输出) - 大量特征数据喂给NN,迭代优化NN参数
(NN反向传播算法–>优化参数训练模型 ) - 使用训练好的模型预测和分类
3.2.2 前向传播
- 搭建模型,实现推理
- 例如:生产一批零件将体积x1和重量x2为特征输入NN,通过NN后输出一个数值(如下图)
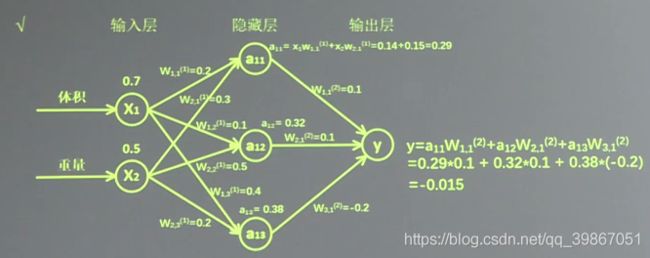

-变量初始化、计算图节点运算都要用会话(with结构)实现
with tf.Session() as sess:
sess.run()
- 变量初始化
init_op = tf.global_variables_initializer()
sess.run(init_op) - 计算图节点运算(在sess.run函数中写入带运算的节点)
sess.run(y) - 用tf.placeholder占位,在sess.run函数中用feed_dict喂数据
喂一组数据(shape = (1,2) 1代表一组数据,2代表两个特征):
x = tf.placeholder(tf.float32,shape=(1,2))
sess.run(y,feed_dict={x:[[0.5,0.6]]})
喂多组数据(None表示不知道几组数据):
x = tf.placeholder(tf.float32,shape=(None,2))
sess.run(y,feed_dict={x:[[0.1,0.2],[0.2,0.3],[0.3,0.4],[0.4,0.5]]})
示例代码:
#coding:utf-8
#两层简单的神经网络(全连接)
import tensorflow as tf
#定义输入和参数
x = tf.constant([[0.7,0.5]])
w1 = tf.Variable(tf.random_normal([2,3],stddev=1,seed=1))
w2 = tf.Variable(tf.random_normal([3,1],stddev=1,seed=1))
#定义前向传播过程
a = tf.matmul(x,w1)
y = tf.matmul(a,w2)
#y用会话计算结果
with tf.Session() as sess:
init_op = tf.global_variables_initializer()
sess.run(init_op)
print "y is:\n",sess.run(y)
结果:[[3.0904665]]
示例代码:
#coding:utf-8
#两层简单的神经网络(全连接)
import tensorflow as tf
#定义输入和参数
#用placeholder实现输入定义(sess.run中喂一组数据)
x = tf.placeholder(tf.float32,shape=(1,2))
w1 = tf.Variable(tf.random_normal([2,3],stddev=1,seed=1))
w2 = tf.Variable(tf.random_normal([3,1],stddev=1,seed=1))
#定义前向传播过程
a = tf.matmul(x,w1)
y = tf.matmul(a,w2)
#y用会话计算结果
with tf.Session() as sess:
init_op = tf.global_variables_initializer()
sess.run(init_op)
print "y is:\n",sess.run(y,feed_dict={x:[[0.7,0.5]]})
结果:[[3.0904665]]
示例代码:
#coding:utf-8
#两层简单的神经网络(全连接)
import tensorflow as tf
#定义输入和参数
#用placeholder实现输入定义(sess.run中喂一组数据)
x = tf.placeholder(tf.float32,shape=(None,2))
w1 = tf.Variable(tf.random_normal([2,3],stddev=1,seed=1))
w2 = tf.Variable(tf.random_normal([3,1],stddev=1,seed=1))
#定义前向传播过程
a = tf.matmul(x,w1)
y = tf.matmul(a,w2)
#y用会话计算结果
with tf.Session() as sess:
init_op = tf.global_variables_initializer()
sess.run(init_op)
print "y is:\n",sess.run(y,feed_dict={x:[[0.7,0.5],[0.2,0.3],[0.3,0.4],[0.4,0.5]]})
print "w1:\n",sess.run(w1)
print "w2:\n",sess.run(w2)
结果:y is:
[[3.0904665]
[1.2236414]
[1.7270732]
[2.2305048]]
w1:
[[-0.8113182 1.4845988 0.06532937]
[-2.4427042 0.0992484 0.5912243 ]]
w2:
[[-0.8113182 ]
[ 1.4845988 ]
[ 0.06532937]]
3.3 反向传播
-
反向传播:训练模型参数,在所有参数上用梯度下降,使NN模型在训练数据上的损失函数最小
-
损失函数(loss):预测值(y)与已知答案(y_)的差距
-
均方误差MSE:

-
反向传播训练方法: 以减小loss值为优化目标(给出优化器的例子)
train_step = tf.train.GradientDescentOptimizer(learning_rate).minimize(loss)
train_step = tf.train.MomentumOptimizer(learning_rate,momentum).minimize(loss)
train_step = tf.train.AdamOptimizer(learning_rate).minimize(loss) -
学习率:决定参数每次更新的幅度(初始化为0.001左右)
示例代码:
#coding:uddf-8
#导入模块,生成模拟数据集
import tensorflow as tf
import numpy as np
BATCH_SIZE = 8
seed = 23455 #真正编程时不用定义这个
#基于seed产生随机数
rng = np.random.RandomState(seed)
#随机数返回32行2列的矩阵 表示32组 体积和重量 作为输入数据集
X = rng.rand(32,2)
#从X这个32行2列的矩阵中 取出1行 判断如果和小于1 给Y赋值 如果和不小于1 给Y赋值0
#作为输入数据集的标签(正确答案)
Y = [[int(x0 + x1 <1)] for (x0,x1) in X]
print "X:\n",X
print "Y:\n",Y
#定义神经网络的输入、参数和输出,定义前向传播过程
x = tf.placeholder(tf.float32,shape=(None,2))
y_ = tf.placeholder(tf.float32,shape=(None,1))
w1 = tf.Variable(tf.random_normal([2,3],stddev=1,seed=1))
w2 = tf.Variable(tf.random_normal([3,1],stddev=1,seed=1))
#定义前向传播过程
a = tf.matmul(x,w1)
y = tf.matmul(a,w2)
#定义损失函数及反向传播方法
loss = tf.reduce_mean(tf.square(y-y_))
train_step = tf.train.GradientDescentOptimizer(0.001).minimize(loss)
#y生成会话,训练STEPS轮
with tf.Session() as sess:
init_op = tf.global_variables_initializer()
sess_run(init_op)
#输出目前(未经训练)的参数取值
print "w1:\n",sess.run(w1)
print "w2:\n",sess.run(w2)
print "\n"
#训练模型
STEPS = 3000
for i in range(STEPS):
start=(i*BATCH_SIZE)%32
end=start + BATCH_SIZE
sess.run(train_step,feed_dict = {x:X[start:end],y_:Y[start:end]})
if i % 500 == 0
total_loss = sess.run(loss ,feed_dict={x:X,y_:Y})
print("After %d training step(s) , loss on all data is %g" %(i,total_loss))
#输出训练后的参数取值
print "\n"
print "w1:\n",sess.run(w1)
print "w2:\n",sess.run(w2)
搭建神经网络的八股:准备、前传、反传、迭代
- 准备: import、常量定义、生成数据集
- 前向传播:定义输入、参数和输出
(x=、y_=、W1=、W2=、a=、y=) - 反向传播:定义损失函数、反向传播方法
(loss=、train_step=) - 生成会话,训练STEPS轮
with tf.session() as sess
init_op = tf.global_variables_initializer()
sess_run(init_op)
STEPS = 3000
for i in range(STEPS):
start=
end=
sess.run(train_step,feed_dict:)
4 神经网络优化
4.1 损失函数
- 今后所使用的神经元模型(如下图)

- 其中的激活函数(activation function)
常见的激活函数:relu、sigmoid、tanh等

- NN复杂度:多用NN层数和NN参数的个数表示
其中层数(有计算能力的层) = 隐藏层的层数 + 1个输出层
总参数 = 总w + 总b

4.1.1 损失函数(loss)
- 预测值(y)与已知答案(y_
- )的差距
NN优化目标:loss最小。
三种方法:mse(均方误差) (Mean Squared Error)、自定义、ce(交叉熵)(Cross Entropy)
4.1.1.1 均方误差

4.1.1.2自定义损失函数

4.1.1.3交叉熵ce(Cross Entropy)
- 表征两个概率分布之间的距离


其中第二章图片的cem值即为损失函数
4.2 学习率
-
学习率 learning_rate: 每次参数更新的幅度

-
重要问题:学习率设置为多少比较合适?
学习率大了振荡不收敛,学习率笑了收敛速度很慢。 -
提出:指数衰减学习率

其中,staircase为false则为平滑下降的曲线,为true
为阶梯型的曲线。
4.3 滑动平均
- 滑动平均(影子值):记录了每个参数一段时间内过往值的平均,增加了模型的泛化性。
- 其针对所有的参数:w和b
- (像是给了参数加了影子,参数变化,影子缓慢追随)


4.4 正则化
- 正则化缓解过拟合
正则化在损失函数中引入模型复杂度指标,利用给W加权值,弱化了训练数据的噪声(一般不正则化偏差b)。

- 代码实现

4.4.1 matplotlib可视化工具
sudo pip install matplotlib
plt.scatter(x坐标,y坐标,c="颜色")
plt.show()xx,yy = np.mgrid[起:止:步长,起:止:步长]``grid = np.c_[xx.rave(),yy.ravel()] #np.c_组成矩阵,ravel降维拉直
grid是网格范围内所有的坐标点
probs = sess.run(y,feed_dict={x:grid})
probs即为目标点的量化值
probs = probs.reshape(xx.shape) #整形,让probs的shape和xx的一样plt.contour(x轴坐标值,y轴坐标值,该点的高度,levels=[等高线的高度])
plt.show()
示例代码:
#coding:utf-8
#0导入模块 ,生成模拟数据集
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
BATCH_SIZE = 30
seed = 2
#基于seed产生随机数
rdm = np.random.RandomState(seed)
#随机数返回300行2列的矩阵,表示300组坐标点(x0,x1)作为输入数据集
X = rdm.randn(300,2)
#从X这个300行2列的矩阵中取出一行,判断如果两个坐标的平方和小于2,给Y赋值1,其余赋值0
#作为输入数据集的标签(正确答案)
Y_ = [int(x0*x0 + x1*x1 <2) for (x0,x1) in X]
#遍历Y中的每个元素,1赋值'red'其余赋值'blue',这样可视化显示时人可以直观区分
Y_c = [['red' if y else 'blue'] for y in Y_]
#对数据集X和标签Y进行shape整理,第一个元素为-1表示,随第二个参数计算得到,第二个元素表示多少列,把X整理为n行2列,把Y整理为n行1列
X = np.vstack(X).reshape(-1,2)
Y_ = np.vstack(Y_).reshape(-1,1)
print X
print Y_
print Y_c
#用plt.scatter画出数据集X各行中第0列元素和第1列元素的点即各行的(x0,x1),用各行Y_c对应的值表示颜色(c是color的缩写)
plt.scatter(X[:,0], X[:,1], c=np.squeeze(Y_c))
plt.show()
#定义神经网络的输入、参数和输出,定义前向传播过程
def get_weight(shape, regularizer):
w=tf.Variable(tf.random_normal(shape), dtype=tf.float32)
tf.add_to_collection('losses', tf.contrib.layers.l2_regularizer(regularizer)(w))
return w
def get_bias(shape):
b = tf.Variable(tf.constant(0.01, shape=shape))
return b
x = tf.placeholder(tf.float32, shape=(None, 2))
y_ = tf.placeholder(tf.float32, shape=(None, 1))
w1 = get_weight([2,11], 0.01)
b1 = get_bias([11])
y1 = tf.nn.relu(tf.matmul(x, w1)+b1)
w2 = get_weight([11,1], 0.01)
b2 = get_bias([1])
y = tf.matmul(y1, w2)+b2
#定义损失函数
loss_mse = tf.reduce_mean(tf.square(y-y_))
loss_total = loss_mse + tf.add_n(tf.get_collection('losses'))
#定义反向传播方法:不含正则化
train_step = tf.train.AdamOptimizer(0.0001).minimize(loss_mse)
with tf.Session() as sess:
init_op = tf.global_variables_initializer()
sess.run(init_op)
STEPS = 40000
for i in range(STEPS):
start = (i*BATCH_SIZE) % 300
end = start + BATCH_SIZE
sess.run(train_step, feed_dict={x:X [start:end], y_:Y_[start:end]})
if i % 2000 == 0:
loss_mse_v = sess.run(loss_mse, feed_dict={x:X, y_:Y_})
print("After %d steps, loss is: %f" %(i, loss_mse_v))
#xx在-3到3之间以步长为0.01,yy在-3到3之间以步长0.01,生成二维网格坐标点
xx, yy = np.mgrid[-3:3:.01, -3:3:.01]
#将xx , yy拉直,并合并成一个2列的矩阵,得到一个网格坐标点的集合
grid = np.c_[xx.ravel(), yy.ravel()]
#将网格坐标点喂入神经网络 ,probs为输出
probs = sess.run(y, feed_dict={x:grid})
#probs的shape调整成xx的样子
probs = probs.reshape(xx.shape)
print "w1:\n",sess.run(w1)
print "b1:\n",sess.run(b1)
print "w2:\n",sess.run(w2)
print "b2:\n",sess.run(b2)
plt.scatter(X[:,0], X[:,1], c=np.squeeze(Y_c))
plt.contour(xx, yy, probs, levels=[.5])
plt.show()
#定义反向传播方法:包含正则化
train_step = tf.train.AdamOptimizer(0.0001).minimize(loss_total)
with tf.Session() as sess:
init_op = tf.global_variables_initializer()
sess.run(init_op)
STEPS = 40000
for i in range(STEPS):
start = (i*BATCH_SIZE) % 300
end = start + BATCH_SIZE
sess.run(train_step, feed_dict={x: X[start:end], y_:Y_[start:end]})
if i % 2000 == 0:
loss_v = sess.run(loss_total, feed_dict={x:X,y_:Y_})
print("After %d steps, loss is: %f" %(i, loss_v))
xx, yy = np.mgrid[-3:3:.01, -3:3:.01]
grid = np.c_[xx.ravel(), yy.ravel()]
probs = sess.run(y, feed_dict={x:grid})
probs = probs.reshape(xx.shape)
print "w1:\n",sess.run(w1)
print "b1:\n",sess.run(b1)
print "w2:\n",sess.run(w2)
print "b2:\n",sess.run(b2)
plt.scatter(X[:,0], X[:,1], c=np.squeeze(Y_c))
plt.contour(xx, yy, probs, levels=[.5])
plt.show()
4.5 神经网络的搭建的总结
模块化搭建思想(多个py文件,方便扩展)
- 生成数据集(generate.py)
- 前向传播就是搭建网络,设计网络结构(forward.py)
- 反向传播就是训练网络,优化网络参数(backward.py)
5 全连接网络
-
全连接NN:每个神经元与前后相邻层的每一个神经元都有链接关系,输入时特征,输出为预测的结果。
-
参数个数为:前层*后层+后层
5.1 MNIST数据集
-
提供6W张28*28像素点的0-9手写数字图片和标签,用于训练。
-
提供1W张28*28像素点的0-9手写数字图片和标签,用于测试。
-
每张图片的784个像素点组成长度为783的一维数组,作为输入特征。
-
图片的标签以一位数组的形式给出,每个元素表示对应分类出现的概率。
-
有用的函数
tf.get_collection("") #从集合中取全部变量,生成一个列表
tf.add_n([]) #列表内对应元素相加
tf.cast(x,dtype) #把x转化为dtpye类型
tf.argmax(x,axis) #返回最大值所在索引号 如:tf.argmax([1,0,0],1)sve返回0
os.path.join("home","name") #返回home/name这种路径的形式
字符串.split() #按指定拆分符对字符串切片,返回分隔后的列表,这个可以从一个路径名中截取一个文件名,例:'./model/mnist_model-1001'.split('/')[-1].split('-')[-1] 返回1001
with tf.Graph().as_default() as g: #其内定义的节点在计算图g -
保存模型
saver = tf.train.Saver() #实例化saver对象
with tf.Session() as sess: #在with结构for循环中一定轮数时保存模型到当前会话
for i in range(STEPS):
if i % 轮数 == 0:
saver.save(sess,os.path.join(MODEL_SAVE_PATH,MODEL_NAME),global_step = global_step) -
加载模型
with tf.Session() as sess:
ckpt = tf.train.get_checkpoint_state(存储路径)
if ckpt and ckpt.model_checkpoint_path:
saver.restore(sess,ckpt.model_checkpoint_path)
5.2 应用小窍门
加入代码:
ckpt = tf.train.get_checkpoint_state(MODEL_SAVE_PATH)
if ckpt and ckpt.model_checkpoint_path:
saver.restore(sess, ckpt.model_checkpoint_path)
实现关闭中断后,再次运行,是从上一次的节点处运行,不需要再从头训练了。
5.3 如何制作数据集
-
使用tfrecords文件
tfrecords是一种二进制文件,可先将图片和标签制作成该格式的文件。使用tfrecoreds进行数据读取,会提高内存利用率。
用 tf.train.Example的协议存储训练数据。训练数据的特征用键值对的形式表示。
如:‘img_raw’:值 ‘label’:值 值是Byteslist/FloatList/int64List用SerializeToString()把数据序列化成字符串存储。
-
生成tfrecords文件(见代码)
-
解析tfrecprds文件(见代码)
6 卷积神经网络(CNN)
- 如果直接输入的是三通道的RGB彩色图片,待优化的参数过多容易导致模型过拟合,而且计算量过大。所以**实际应用中会先对原始图像进行特征提取再把提取到的特征喂给全连接网络,**再让全连接网络进行参数优化,得到分类评估。这样可以减小计算量等。
6.1 卷积(Convolution)
6.1.1 卷积的基本概念
- 卷积是一种有效的提取图片特征的方法。
- 一般会用一个正方形卷积核,遍历图片上的每一个点。图片区域内,相对应的每一个像素值,乘以卷积核内相对应点的权重,求和,(再加上偏置)。
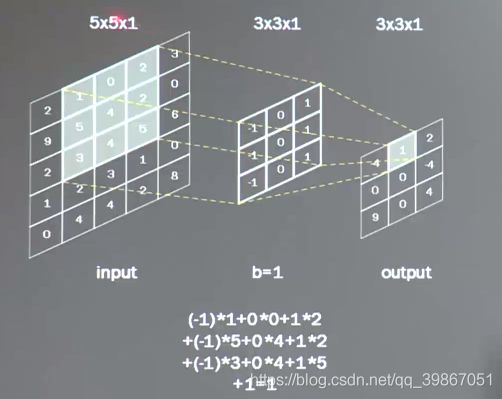
- 输出的图片的边长 = (输入图片边长 - 卷积核长 + 1) / 步长
- 用几个卷积核,输出的深度就是几。
- 为了保证输出图片的尺寸与输入图片的大小一致,需要在输入图片处进行全零填充(padding)

- 在TensorFlow中,用参数padding = ‘SAME’ 或 padding = ‘VALID’表示
6.1.2 TensorFlow计算卷积
-
例如:单通道的灰度图片
tf.nn.conv2d(输入描述,eg.[batch,5,5,1]) #batch是一次喂入图片的个数,(5,5)为分辨率,1为通道数(灰度图为1,彩色图为3)
卷积核描述,eg.[3,3,1,16] #(3,3)为行列分辨率,1为通道数(由输入图片的通道数决定),16为核个数(即输出图片的深度为16(输出为16通道))
核滑动步长,eg.[1,1,1,1] #第二个‘1’为行步长和第三个‘1’为列步长,第一个和第四个参数都固定是1
padding = 'VALID' #不使用padding填充) -
例如:多通道的彩色图片:
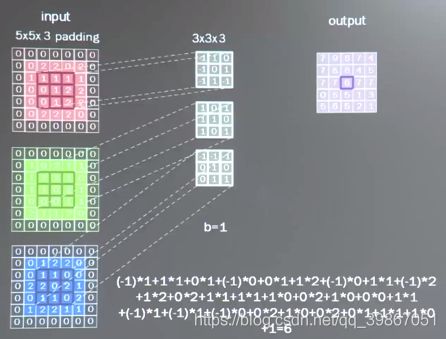
-
格式:
tf.nn.conv2d(输入描述,eg.[batch,5,5,3]) #batch是一次喂入图片的个数,(5,5)为分辨率,3为通道数(灰度图为1,彩色图为3)
卷积核描述,eg.[3,3,1,16] #(3,3)为行列分辨率,1为通道数(由输入图片的通道数决定),16为核个数(即输出图片的深度为16(输出为16通道))
核滑动步长,eg.[1,1,1,1] #第二个‘1’为行步长和第三个‘1’为列步长,第一个和第四个参数都固定是1
padding = 'SAME' #使用padding填充)
6.1.3 池化(pooling)
- 卷积(特征提取)以后的特征数量仍然巨大,可以使用池化来进一步减少特征数量。
- 种类:最大池化(只提取步长中的原图片的最大值,作为输出的一项):提取图片纹理,均值池化(提取步长中的原图片对应像素点的平均值):保留背景特征。
- TensorFlow计算池化:(tf.nn.max_pool是最大池化;tf.nn.avg_pool是均值池化)
pool = tf.nn.max_pool(输入描述,eg.[batch,28,28,6]) #batch是一次喂入图片的个数,(28,28)为分辨率,6为通道数
池化核描述(仅大小),eg.[1,2,2,1] #(2,2)为行列分辨率,第一个和第四个参数都固定是1
池化核滑动步长,eg.[1,2,2,1] #第二个‘2’为行步长和第三个‘2’为列步长,第一个和第四个参数都固定是1
padding = 'SAME'
6.1.4 舍弃(Dropout)
- 在神经网络的训练过程中,将一部分的神经元按照一定的概率从神经网络中暂时舍弃。使用时被舍弃的神经元恢复链接。一般放在全连接网络中,其可以有效解决过拟合的问题,加快模型的训练速度。

- 例子:
tf.nn.dropout(上层输出,暂时舍弃的概率)
if train: 输出 = tf.nn.dropout(上层输出,暂时舍弃的概率)
6.1.5 卷积NN-总结
- 卷积NN:借助卷积核(kernel)提取特征后,送入全连接网络。
- 特征提取(卷积+激活+池化)(高层次抽象特征 精简特征点) + 全连接网络。

6.2 lenet5(1998年提出的最早的CNN代码) 讲解
- 经典的lenet5算法

[ 5 * 5 * 16]即为卷积神经网络提取的特征,将其作为输入喂给全连接网络。
- 使用MNIST数据集的lenet5算法

[7 * 7 * 64]即为卷积神经网络提取的特征,将其作为输入喂给全连接网络。
7 利用已有的网络,实现特定应用
7.1 基本函数以及可视化功能
x = tf.placeholder(tf.float32,shape = [BATCH,IMAGE_PIXELS]) #shape = [1,224,224,3] 1:表示一次喂入一个图片;224,224,3是图片的分辨率和通道数
-
tf.placeholder用于传入真实的训练样本、测试、真实特征、待处理特征,仅占位,不必给初值,用sess.run的feed_dict参数以字典的形式喂入x:sess.run(求分类评估值的节点,feed_dict{x: })
-
np.load/save将数组以二进制格式 读出/写入磁盘,扩展名为.npy。
np.save("名.npy",某数组)
某变量 = np.load("名.mpy",encoding = '').item() #.item()为遍历(键值对)
如:
data_dict = np.load(vgg.npy,encoding = 'latin1').item() #读vgg16.npy文件,遍历其内键值对,导出模型参数赋给data_dict -
tf.shape(a) 返回a的维度(a可以为tensor、list、array)

-
tf.nn.bias_add(乘加和,bias)
把bias加到乘加和上 -
tf.reshape(tensor,[n行,n列])(将张量变为需要的维度)
[-1,m列]:-1表示行跟随m列自动调整 -
np.argsort(列表)
对列表从小到大排序,返回索引值 -
os.getcwd()
返回当前的工作目录 -
os.path.join( , ,…)
拼接出整个文件路径,可引导到特定的文件
例子:
vgg16_path = os.path.join(os.getcwd(),"vgg16.npy") #当前目录为/vgg16.npy 索引到文件vgg16.npy -
tf.split(切谁,怎么切,在哪个维度切)
例如:value是一个[5,30]的张量。
split0,split1,split2 = tf.split(value,[4,5,11],1)
输出:tf.shape(split0) ==>[5,4];
tf.shape(split1) ==>[5,5];
tf.shape(split2) ==>[5,11];
再如:value是一个[5,30]的张量。
split0,split1,split2 = tf.split(value,num_or_size_splits=3,axis = 1) #均分
输出:tf.shape(split0) ==>[5,10];
tf.shape(split1) ==>[5,10;
tf.shape(split2) ==>[5,10]; -
tf.concat(值,在哪个维) 实现粘贴

-
fig = plt.figure(“图名字”) #实例化图对象
img = io.imread(图片路径) #读入图片
ax = fig.add_subplot(数,数,数) #数数数分别是:包含几行、包含几列、当前是第几个
ax.bar(bar的个数,bar的值,每个bar的名字,bar宽,bar色)
ax.set_ylabel(" ") #y轴名字 ,如果使用中文,应该这样子使用:u“中文”
ax.set_title("") #子图名字
ax.text(文字x坐标,文字y坐标,ha = 'center',va = 'bottom',fontsize = 7) -
ax = imshow(图) 画子图
7.2 VGGNET 源码包含的文件
- app.py:应用程序,实现图像识别
- vgg16.py: 读模型参数,搭建模型
- utils.py: 读入图片,概率显示
- Nclasses.py: 含识别类型(labels)的字典
- vgg16.npy: 网络参数
- 其中的data_dict保存了网络参数,可以使用
print self.data_dict看一下具体的参数。

- 具体的参数设计请看https://www.icourse163.org/learn/PKU-1002536002?tid=1002700003#/learn/content?type=detail&id=1004116044&cid=1005074145&replay=true
- vgg算法py文件内容讲解https://www.icourse163.org/learn/PKU-1002536002?tid=1002700003#/learn/content?type=detail&id=1004116044&cid=1005074145&replay=true
全部代码见我github:https://github.com/yyysjz1997/Introduction-to-Artificial-Intelligence
我的github中有更多的好玩的小东西哦!
https://github.com/yyysjz1997