flink+pyflink+alink笔记
系列文档参见这里。
1. 背景与原理
1.1 背景
其实就是数据处理流水线。可以参考https://zhuanlan.zhihu.com/p/114717285
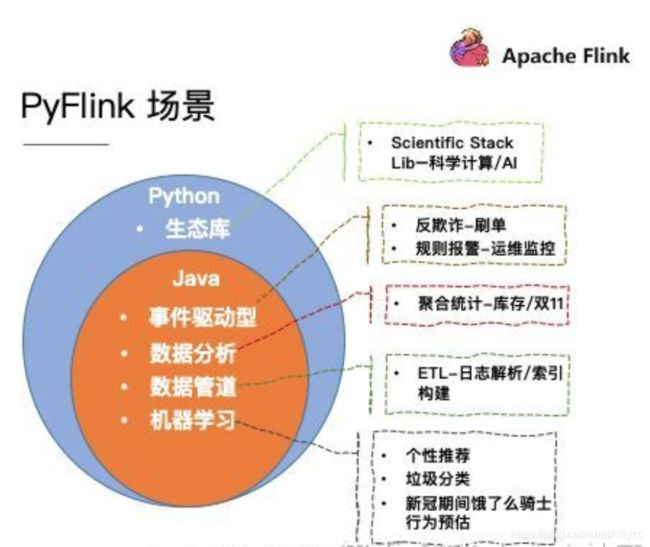
常见的应用场景:
第一个,事件驱动型,比如:刷单,监控等;
第二个,数据分析型的,比如:库存,双11大屏等;
第三个适用的场景是数据管道,也就是ETL场景,比如一些日志的解析等;
第四个场景,机器学习,比如个性推荐等。
1.2 基本概念
- bounded、unbounded
- state。无状态:来一条处理一条;有状态:需要keep之前的状态。Flink提供本地状态,需要定期远程备份。
- time。event(事件发生事件)、ingestion、processing time。
- api:sql/table api(dynamic tables);dataStream API(streams, windows),processFunction(events,state,time)。

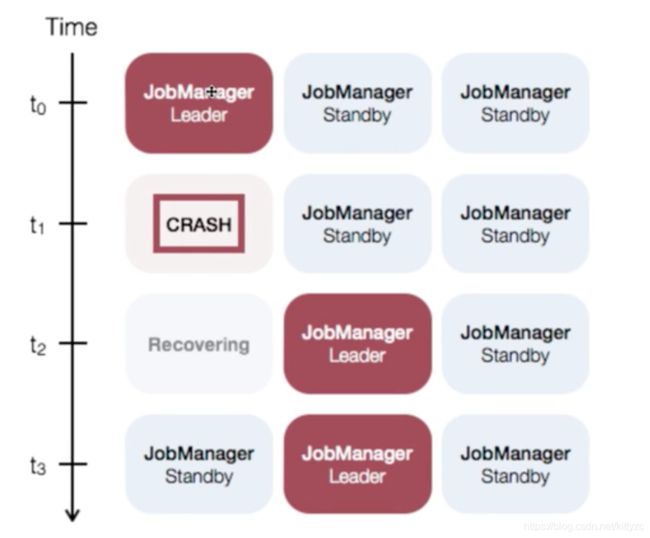
1.3 稳定性的一些配置
2. flink安装
2.1 brew方式
安装:brew install apache-flink。通过brew info apache-flink查找flink的安装位置。一般在/usr/local/Cellar/apache-flink/1.10.0目录下。
这个目录相当精简,没有python相关的环境。
cd到根目录下,启动standalone模式:
./libexec/bin/start-cluster.sh
slave清单在conf文件夹下
2.2 安装包启动
直接到官网找到源码,下载后,cd到根目录下,启动standalone模式。这里的内容是比较详细的,同目录下有pyflink-shell,外面的example里面也有python的例子

2.3 使用conda/pip安装
pip install apache-flink,
pip install alink
顺便把alink也装上。如果出现PyYAML问题,执行pip3 install --ignore-installed PyYAML。
启动脚本在~/anaconda3/lib/python3.7/site-packages/pyflink/bin目录下。可以看出内容同样很丰富。

2.4 使用方式
2.4.1 启动集群
- start-cluster.sh local启动的是flink进程,web管理页面为:http://localhost:8081/
2.4.2 pyflink
pyflink-shell.sh local启动的是一个python编译器和自带的flink环境,可以通过s_env和b_env获得环境变量。在新版本中,PyAlink 新增了 getMLEnv 的接口,直接获取 PyFlink 的执行环境。 这个接口返回四元组(benv, btenv, senv, stenv),分别对应 PyFlink 中的四种执行环境: ExecutionEnvironment、BatchTableEnvironment、StreamExecutionEnvironment 和 StreamTableEnvironment。 基于这四个变量,用户可以调用 PyFlink 的接口。
此外,在之前的版本中,PyAlink 提供了方便使用 Flink 不同执行环境的函数:useLocalEnv 和 useRemoteEnv。 这两个接口在新版本中将同样返回四元组 (benv, btenv, senv, stenv)。 用户可以通过返回的执行环境来调用 PyFlink 的接口。
PyAlink 提供了 TableSourceBatchOp 和 TableSourceStreamOp 将 PyFlink 中的 Table 分别转换为 Alink 中的 BatchOperator 和 StreamOperator。
同时,对于 PyAlink 中的 Operator,提供了 getOutputTable 来获取算法组件对应的 Table 。
pyflink-shell.sh remote localhost 8081,这样可以连接到最开始启动的flink环境上面去。
2.4.3 alink
mac上可以参考这里进行安装
进入jupyter notebook使用下面的方式进行查看
from pyalink.alink import *
resetEnv()
useLocalEnv('localhost',8081,1)
source_url = CsvSourceBatchOp()\
.setFilePath("http://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data")\
.setSchemaStr("sepal_length double, sepal_width double, petal_length double, petal_width double, category string")
source_url.firstN(5).print()

3. 操纵数据
3.1 基本读写数据
-
基于文件的:
read_text(path):按行读取文件并将其作为字符串返回。
read_csv(path, type):解析逗号(或其他字符)分隔字段的文件。返回元组的DataSet。支持基本java类型及其Value对应作为字段类型。 -
基于集合:
from_elements(*args):从Seq创建数据集。
generate_sequence(from, to):并行生成给定间隔中的数字序列。 -
支持的Data Sink
write_text():按字符串顺序写入数据元。通过调用每个数据元的str()方法获得字符串。
write_csv(…):将元组写为逗号分隔值文件。行和字段分隔符是可配置的。每个字段的值来自对象的str()方法。
output():打印标准输出上每个数据元的str()值。
3.2 python中获取数据
pyflink预绑定了四个变量,批处理表环境变量名为:
- bt_env(pyflink.table.table_environment.BatchTableEnvironment)
- 批处理执行环境变量名为: b_env(pyflink.dataset.execution_environment.ExecutionEnvironment)
- 流表环境变量名为:st_env(pyflink.table.table_environment.StreamTableEnvironment)
- 流执行环境变量名为:s_env(pyflink.datastream.stream_execution_environment.StreamExecutionEnvironment)
使用本地执行环境时,使用 Notebook 提供的“停止”按钮即可停止长时间运行的Flink作业。 使用远程集群时,需要使用集群提供的停止作业功能。
可以直接使用 Python 脚本而不是 Notebook 运行。但需要在代码最后调用 resetEnv(),否则脚本不会退出。
下面是python的例子
In [1]: import os, shutil
In [2]: sink_path = './streaming.csv'
In [3]: #设置了结果输出路径
In [4]: s_env.set_parallelism(1)
Out[4]: <pyflink.datastream.stream_execution_environment.StreamExecutionEnvironment at 0x10991e1d0>
In [5]: #设置并行度为1,因为是local模式只能设置为1,定义了一个数据来源
In [6]: t = st_env.from_elements([(1, 'hi', 'hello'), (2, 'hi', 'hello')], ['a', 'b', 'c'])
In [7]:
In [8]: st_env.connect(FileSystem().path(sink_path))\
...: .with_format(OldCsv()
...: .field_delimiter(',')
...: .field("a", DataTypes.BIGINT())
...: .field("b", DataTypes.STRING())
...: .field("c", DataTypes.STRING()))\
...: .with_schema(Schema()
...: .field("a", DataTypes.BIGINT())
...: .field("b", DataTypes.STRING())
...: .field("c", DataTypes.STRING()))\
...: .register_table_sink("stream_sink")
Out[8]: <pyflink.table.descriptors.StreamTableDescriptor at 0x1097b4590>
In [9]: t.select("a + 1, b, c")\
...: ... .insert_into("stream_sink")
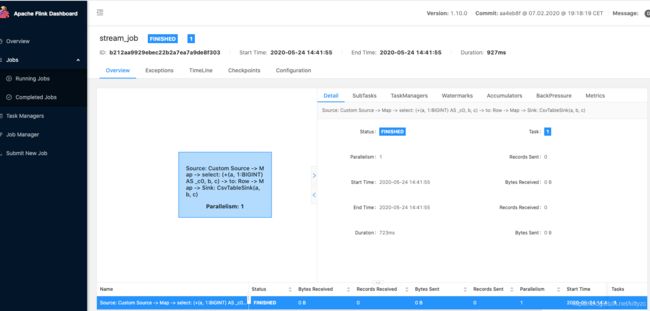
In [10]: st_env.execute("stream_job")
In [11]: # 如果在local模式下,以下代码才能执行.输出了文件结果
In [12]: with open(sink_path, 'r') as f:
...: print(f.read())
...:
2,hi,hello
3,hi,hello
页面上显示完成了一个任务,用时812ms。

3.3 在Alink中与Dataframe互操作
转DataFrame:
source = CsvSourceBatchOp()\
.setSchemaStr("sepal_length double, sepal_width double, petal_length double, petal_width double, category string")\
.setFilePath("https://alink-release.oss-cn-beijing.aliyuncs.com/data-files/iris.csv")
res = source.select(["sepal_length", "sepal_width"])
df = res.collectToDataframe()
# Operations with df
res.print()
转BatchOperator/StreamOperator
schema = "f_string string,f_long long,f_int int,f_double double,f_boolean boolean"
op = BatchOperator.fromDataframe(df, schema)
op.print()
op = StreamOperator.fromDataframe(df, schema)
op.print(key="op")
StreamOperator.execute()
同时,PyAlink 也提供了静态方法来进行转换:dataframeToOperator(df, schemaStr, opType),这里 df 和 schemaStr 参数与上文相同,opType 取值为 “batch” 或 “stream”。
3.4 Alink中StreamOperator数据预览
对于 StreamOperator, 在使用 Jupyter Notebook 时,PyAlink 提供了一种动态的数据预览方式。 这种预览方式采用了 DataFrame 的显示方式,支持随着时间窗口不断进行刷新,从而有较好的视觉体验来观察流式数据。这种预览方式通过以下方法实现: print(self, key=None, refreshInterval=0, maxLimit=100)
- key 为一个字符串,表示给对应的 Operator 给定一个索引;不传值时将随机生成。
- refreshInterval 表示刷新时间,单位为秒。当这个值大于0时,所显示的表将每隔 refreshInterval 秒刷新,显示前 refreshInterval 的数据;当这个值小于0时,每次有新数据产生,就会在触发显示,所显示的数据项与时间无关。
- maxLimit 用于控制显示的数据量,最多显示 maxLimit 条数据。
schema = "age bigint, workclass string, fnlwgt bigint, education string, education_num bigint, marital_status string, occupation string, relationship string, race string, sex string, capital_gain bigint, capital_loss bigint, hours_per_week bigint, native_country string, label string"
adult_batch = CsvSourceStreamOp() \
.setFilePath("http://alink-dataset.cn-hangzhou.oss.aliyun-inc.com/csv/adult_train.csv") \
.setSchemaStr(schema)
sample = SampleStreamOp().setRatio(0.01).linkFrom(adult_batch)
sample.print(key="adult_data", refreshInterval=3)
StreamOperator.execute()
需要特别注意的是:使用 print 进行数据预览的 StreamOperator 需要严格控制数据量。 单位时间数据量太大不仅不会对数据预览有太大帮助,还会造成计算与网络资源浪费。 同时, Python 端在收到数据后进行转换也是比较耗时的操作,两者会导致数据预览延迟。 比较合理的做法是通过采样组件 SampleStreamOp 来达到减少数据量的目的。
4. 常用算子
4.1 operator算子
operator是基于dataStream进行操作的。
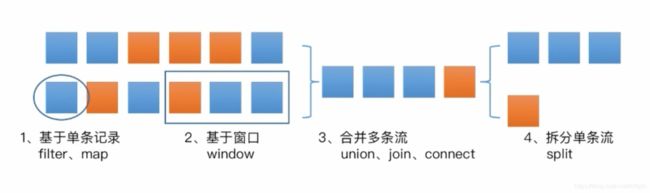
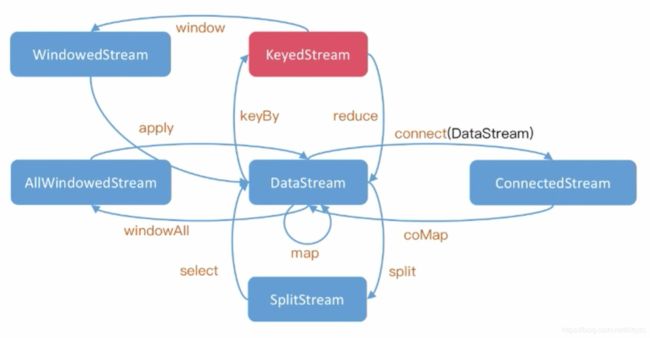
基于单条记录
Map:输入x,输出x’
FlatMap:输入x,输出list
合并多条流
MapPartition:输入list,输出list’
Filter:输入list,输出list’
Reduce:输入list,输出x
ReduceGroup:输入list,输出dict
Aggregate:输入list,输出x,比reduce更复杂
join:输入两个list,输出合并的list’
CoGroup:二维Reduce
Cross:输入两个list,输出x
拆分单条流
split
基于窗口操作
window
下面是个例子:

4.2 UDF函数
我们提供了 udf 和 udtf 函数来帮助构造 UDF/UDTF。 两个函数使用时都需要提供一个函数体、输入类型和返回类型。
函数体对于 UDF 而言,是直接用 return 返回值的 Python 函数,或者 lambda 函数; 对于 UDTF 而言,是用 yield 来多次返回值的 Python 函数。
输入类型均为 DataType 类型的 Python list。
输出类型,UDF 为单个 DataType 类型,UDTF为 DataType 类型的 Python list。
DataType 类型可以直接用DataTypes.DOUBLE()等类似的函数得到。
以下是定义 UDF/UDTF 的代码示例:
# 4种 UDF 定义
# ScalarFunction
class PlusOne(ScalarFunction):
def eval(self, x, y):
return x + y + 10
f_udf1 = udf(PlusOne(), input_types=[DataTypes.DOUBLE(), DataTypes.DOUBLE()], result_type=DataTypes.DOUBLE())
# function + decorator
@udf(input_types=[DataTypes.DOUBLE(), DataTypes.DOUBLE()], result_type=DataTypes.DOUBLE())
def f_udf2(x, y):
return x + y + 20
# function
def f_udf3(x, y):
return x + y + 30
f_udf3 = udf(f_udf3, input_types=[DataTypes.DOUBLE(), DataTypes.DOUBLE()], result_type=DataTypes.DOUBLE())
# lambda function
f_udf4 = udf(lambda x, y: x + y + 40
, input_types=[DataTypes.DOUBLE(), DataTypes.DOUBLE()], result_type=DataTypes.DOUBLE())
udfs = [
f_udf1,
f_udf2,
f_udf3,
f_udf4
]
# 4种 UDTF 定义
# TableFunction
class SplitOp(TableFunction):
def eval(self, *args):
for index, arg in enumerate(args):
yield index, arg
f_udtf1 = udtf(SplitOp(), [DataTypes.DOUBLE(), DataTypes.DOUBLE()], [DataTypes.INT(), DataTypes.DOUBLE()])
# function + decorator
@udtf(input_types=[DataTypes.DOUBLE(), DataTypes.DOUBLE()], result_types=[DataTypes.INT(), DataTypes.DOUBLE()])
def f_udtf2(*args):
for index, arg in enumerate(args):
yield index, arg
# function
def f_udtf3(*args):
for index, arg in enumerate(args):
yield index, arg
f_udtf3 = udtf(f_udtf3, input_types=[DataTypes.DOUBLE(), DataTypes.DOUBLE()], result_types=[DataTypes.INT(), DataTypes.DOUBLE()])
# lambda function
f_udtf4 = udtf(lambda *args: [ (yield index, arg) for index, arg in enumerate(args) ]
, input_types=[DataTypes.DOUBLE(), DataTypes.DOUBLE()], result_types=[DataTypes.INT(), DataTypes.DOUBLE()])
udtfs = [
f_udtf1,
f_udtf2,
f_udtf3,
f_udtf4
]
注意:在 Flink 1.10 及以上版本对应的 PyAlink 包中,udf 定义的 UDF 与 PyFlink 中的 udf 定义是完全一致的。
4.3 SQL操作
schema = "age bigint, workclass string, fnlwgt bigint, education string, education_num bigint, marital_status string, occupation string, relationship string, race string, sex string, capital_gain bigint, capital_loss bigint, hours_per_week bigint, native_country string, label string"
adult_batch = CsvSourceStreamOp() \
.setFilePath("http://alink-dataset.cn-hangzhou.oss.aliyun-inc.com/csv/adult_train.csv") \
.setSchemaStr(schema)
UDFStream = UDFStreamOp().setFunc(f_udf2)\
.setSelectedCols(["age", "education_num"]) \
.setOutputCol("newAge") \
.linkFrom(adult_batch)
UDFStream.registerTableName("A")
res = StreamOperator.sqlQuery("select age,newAge from A where age>30")
res.print()
StreamOperator.execute()
4.4 pyflink API
常用的api见
https://github.com/alibaba/Alink/blob/master/docs/index-cn.md

5. 代码注意事项
数据在物理层面上的传递有如下几种方法:
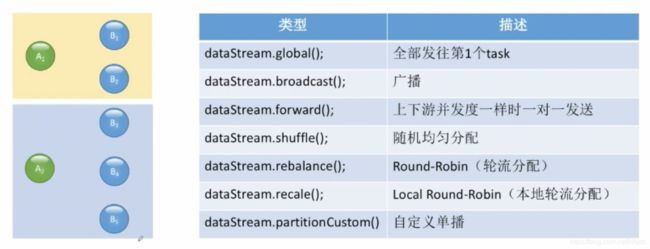

在做实时成交额统计时,一般不用accumulator方法,而是用tableAPI的retractStream方法。key值一般是远大于并发度的,如果每次更新都产生一个非常大的map的话,系统会受不了。
6. 客户端操作
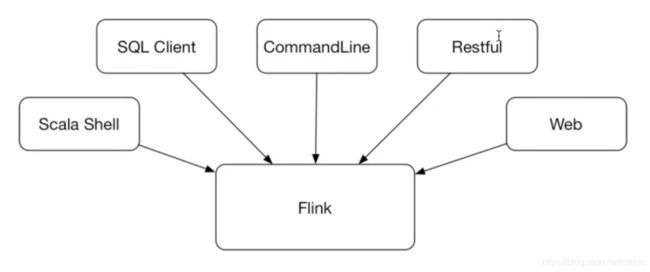
6.1 command line
info 看执行计划,在https://flink.apache.org/visualizer/里可以把命令转化为执行计划图。和物理计划会有差别。
list列出运行任务
detach模式,任务结束就退出
cancel/stop 暴力取消vs优雅取消
cancel可以指定savepoint,下次可以用savepoint。

![]()

6.2 sql-clinet
sql-client.sh embedded启动命令
通过explain命令可以直接看执行计划
6.3 restful方式
更多命令参考这里:
https://ci.apache.org/projects/flink/flink-docs-stable/monitoring/rest_api.html
➜ flink-1.7.2 curl http://127.0.0.1:8081/overview
{"taskmanagers":1,"slots-total":4,"slots-available":0,"jobs-running":3,"jobs-finished":0,"jobs-cancelled":0,"jobs-failed":0,"flink-version":"1.7.2","flink-commit":"ceba8af"}%
➜ flink-1.7.2 curl -X POST -H "Expect:" -F "jarfile=@/Users/baoniu/Documents/work/tool/flink/flink-1.7.2/examples/streaming/TopSpeedWindowing.jar" http://127.0.0.1:8081/jars/upload
{"filename":"/var/folders/2b/r6d49pcs23z43b8fqsyz885c0000gn/T/flink-web-124c4895-cf08-4eec-8e15-8263d347efc2/flink-web-upload/6077eca7-6db0-4570-a4d0-4c3e05a5dc59_TopSpeedWindowing.jar","status":"success"}%
➜ flink-1.7.2 curl http://127.0.0.1:8081/jars
{"address":"http://localhost:8081","files":[{"id":"6077eca7-6db0-4570-a4d0-4c3e05a5dc59_TopSpeedWindowing.jar","name":"TopSpeedWindowing.jar","uploaded":1553743438000,"entry":[{"name":"org.apache.flink.streaming.examples.windowing.TopSpeedWindowing","description":null}]}]}%
➜ flink-1.7.2 curl http://127.0.0.1:8081/jars/6077eca7-6db0-4570-a4d0-4c3e05a5dc59_TopSpeedWindowing.jar/plan
{"plan":{"jid":"41029eb3feb9132619e454ec9b2a89fb","name":"CarTopSpeedWindowingExample","nodes":[{"id":"90bea66de1c231edf33913ecd54406c1","parallelism":1,"operator":"","operator_strategy":"","description":"Window(GlobalWindows(), DeltaTrigger, TimeEvictor, ComparableAggregator, PassThroughWindowFunction) -> Sink: Print to Std. Out","inputs":[{"num":0,"id":"cbc357ccb763df2852fee8c4fc7d55f2","ship_strategy":"HASH","exchange":"pipelined_bounded"}],"optimizer_properties":{}},{"id":"cbc357ccb763df2852fee8c4fc7d55f2","parallelism":1,"operator":"","operator_strategy":"","description":"Source: Custom Source -> Timestamps/Watermarks","optimizer_properties":{}}]}}% ➜ flink-1.7.2 curl -X POST http://127.0.0.1:8081/jars/6077eca7-6db0-4570-a4d0-4c3e05a5dc59_TopSpeedWindowing.jar/run
{"jobid":"04d80a24b076523d3dc5fbaa0ad5e1ad"}%
7. TableAPI和 Flink SQL


7.1 table API
定义表

输出表

查询操作
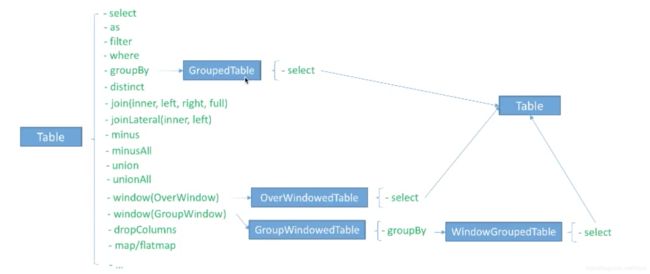






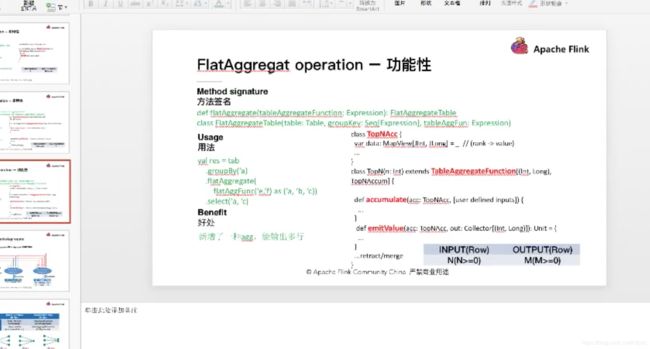


7.2 flink sql



7.3 优化原理
分段优化

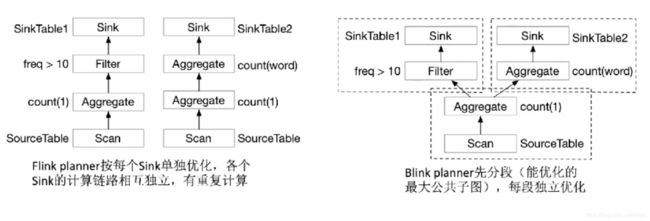
sub-plan reuse


agg优化


