高级特性——python
函数式编程
基于lambda演算的一种编程方式
程序中只有函数
函数可以作为参数,同样可以作为返回值
纯函数式编程语言:LISP Haskell
python函数式编程只是借鉴函数式编程的一些特点,可以理解成一半函数式一半python
- 高阶函数
- 返回函数
- 匿名函数
- 装饰器
- 偏函数
lambda表达式
函数:最大程度复用代码
存在问题:如果函数很小,很短,则会造成啰嗦
如果函数被调用次数少。则会造成浪费
lambda表达式(匿名函数):一个表达式,函数体相对简单,不是一个代码块,仅仅是一个表达式。使用lambda表达式可以不用定义函数名字以及不用使用def 去定义
格式lambda <参数表>: 表达式——注意冒号 (调用时和基本函数调用一致)
rs=lambda x:x*x
print(rs(10))
高阶函数
把函数作为参数使用的函数,叫高阶函数
函数名称就是一个变量
可以当作参数传入另一个函数
def funA(n):
return n*100
#函数可以当作参数传入另一个函数
def funC(n,f):
return f(n)*3
print(funC(9,funA))
系统高阶函数–map()
有时候需要对列表中每个元素做相同的处理,得到新的列表。
例:对一个列表所有数据乘以3,所有字符串转换为整数,两列表值对应相加等等!我们学过for循环后可以利用for循环进行处理。但方便还是用map()函数。
格式:map(func,list2,list1,…listn)——内置函数
list(map())表示要转换为列表形式,要像转为元组即tuole(map())
func为一个函数,这个函数中有几个参数后面跟几个列表(参数对应列表中的元素)
注意:使用时func为一个函数名,在使用时map()里为一个函数名,不需要加入括号以及参数
def fun(a):
return a*3
list1=[1,2,3]
print(list(map(fun,list1)))
reduce——归并,缩减
把一个可迭代的对象最后归并成一个结果
对于函数参数要求:必须有两个参数,必须有返回结果
reduce([1,2,3,4,5])==f(f(f(f(1,2),3),4),5)
reduce需要导入functools包
import functools
#定义一个操作函数
def myadd(x,y):
return x+y
#对于列表执行myadd的educe操作
rst=functools.reduce(myadd,[1,2,3,4,5])
print(rst)
filter函数
过滤函数:对一组数据进行过滤,符合条件的数据会生成一个新的列表并返回
和map相比较:相同:都对列表的每一个元素逐一进行操作
不同;map会生成一个跟原来数据相对应的新队列。filter不一定,只要符合条件的才会进入新的数据集合
filter函数写法:利用给定的函数进行判断,返回值一定是一个布尔值
格式:filter(f,data)——f是要过滤函数,date是数据
#需要定义过滤函数,过滤函数要求有输入,返回布尔值
def iseven(a):
return a%2==0
l=[1,2,4,5,8,7,11,45,66]
#注意python3中要想以列表形式输出必须list(filter())
print(list(filter(iseven,l)))
高阶函数—排序
把一个序列按照给定的算法进行排序
Key:在排序前对每一个元素进行key函数运算,可以理解成按照key函数定义的逻辑进行排序(在这方面python2和3还是相差较大的)
案例
1、
a=[1,22,,99]
k=sorted(a)
print(k)
#默认升序,指定reverse=True为降序排序
2、
a=[1,-23,88,9,-8]
al=sorted(a,key=abs,reverse=True)
print(al)
#按照绝对值进行排序,但是返回列表元素并没有改变符号,结果为;[88, -23, 9, -8, 1]
#abs求取绝对值的意思
3、
astr=['dana','Dna','wangfei','chenxi']
str1=sorted(astr,key=str.lower)
print(str1)
str2=sorted(astr,key=str.upper)
print(str2)
高阶函数–zip
把两个可迭代内容生成一个可迭代的tuple元素类型组成的内容
a=[1,2,3,4,5]
b=[2,8,9,7,3]
z=zip(a,b)
print(z)
print(list(z))
c=["an",'xx','aas']
d=[78,87,99]
p=zip(c,d)
print(p)
print(list(p))
高阶函数–enumerate
跟zip功能比较像
对可迭代的里的每一个元素,配上一个索引,然后索引和内容构成元组类型
a=[1,2,3,4,5]
z=enumerate(a)
#也可以设定索引开始值:start=n 表示从n开始
print(list(z))
高阶函数–collections模块
1、高阶函数namedtuple deque
import collections as t
#namedtuple 元组类型 是一个可命名的
point=t.namedtuple("point",['x','y'])
p=point(11,12)
print(p.x)
print(p[1])
y=t.deque([1,2,3])
y.append('a')
#也可以从前面插入
y.appendleft('s')
print(y)
del y[0]
print(y)
deque:比较方便的解决了频繁删除插入带来的效率问题
2、高阶函数–defaultdict
当直接读取dict不存在的属性时,直接返回默认值
defaultdict第一个参数为一个函数,当属性不存在时返回函数中的值(见下方案例)
import collections as t
dic={'one':1,'two':2,'three':3}
#defaultdict有一个函数,当属性不存在时返回函数中的值
def k():
return "王"
x=t.defaultdict(k,dic)
print(x['one'])
print(x['four'])
3、高阶函数–Counter
统计字符串个数
以键值对的形式把字符串个数打印出来
import collections as t
#以键值对的形式把字符串个数打印出来
c=t.Counter("ahsalLlsaajldjjojfe")
print(c)
print(help(t.Counter))
s=["love","love","csdlc","hlichdf"]
k=t.Counter(s)
print(k)
具体用法可以通过help函数进行获取
返回函数
函数可以返回具体的值
也可以返回一个函数作为结果
函数作为返回值返回,被返回的函数在函数体内定义
def a():
def b():
print("ninhao")
return 3
return b
#调用啊,返回一个函数b,赋值给调用者F
F=a()
F()
def my(*args):
def mi():
rst=0
for n in args:
rst+=n
return rst
return mi
ff=my(1,2,3,4,5)
print(ff())
闭包(closure)
当一个函数在内部定义函数,并且内部函数应用外部函数的参数或者局部变量,当内部函数被当作返回值的时候,相关参数和变量保存在返回的函数中,这种结果,称为闭包
上面的第三个案例是非常典型的
案例
'''
def count():
#定义列表,列表里存放的是定义的函数
fs=[]
for i in range(1,4):
#定义了一个函数f
#f是一个闭包结构
def f():
return i*i
fs.append(f)
return fs
f1,f2,f3=count()
print(f1())
print(f2())
print(f3())
'''
'''
出现的问题:返回函数引用了变量i,i并非立即执行,
而是等到三个函数都返回的时候才统一使用,
此时i已经变成了3,最终调用的时候,都返回的是3*3
此问题描述成:返回闭包时,返回函数不能引用任何循环变量
解决方案:再创建一个函数,
用该函数的参数绑定循环变量的当前值,
无论该循环变量以后如何改变,
已经绑定的函数参数值不再改变
'''
def count1():
def f(j):
def g():
return j*j
return g
fs=[]
for i in range(1,4):
fs.append(f(i))
return fs
f4,f5,f6=count1()
print(f4())
print(f5())
print(f6())
返回闭包时,返回函数不能引用任何循环变量
装饰器
def hello():
print("ninha ")
return 0
f=hello
#为一个函数
f()
现对hello函数扩展功能,每次打印hello之前,打印当前系统时间,而实现这个功能又不能改变当前代码,此时运用装饰器
定义:在不改动函数代码的基础上无限制扩展函数功能的一种机制,本质上讲,装饰器是一个返回函数的高阶函数
装饰器的使用:使用@语法,即在每次要扩展到函数定义前使用@+函数名
import time
#高阶函数,以函数作为参数
def printtime(f):
def wrapper(*args,**kwargs):
print(time.ctime())#先执行这句代码
return f(*args,**kwargs)
return wrapper
#上面定义了装饰器,调用时需要用到@
@printtime
def hello():
print("你好")
hello()
偏函数
参数固的函数,相对于一个由特定参数的函数体
funtools.partial的作用,把一个函数某些函数固定。返回一个新函数
调试技术
调试流程:单元测试–集成测试–交测试部
分:静态测试、动态测试:pdb调试
持久化-文件
文件:长久保存信息的一种数据信息集合
常用操作:打开关闭(打开必须关闭)
open函数
该函数用于打开文件,带有很多参数
第一个参数必须有文件的路径和名称
mode:表示文件以什么方式打开,有以下几种
- r:以只读方式打开
- w:写方式打开,会覆盖以前的内容
- x:创建方式打开,如文件已经存在,报错
- a:append方式,以追加的方式对文件内容进行写入
- b:binary方式,二进制方式写入
- t:文本方式打开
- +:可读写
1、往往会遇到转义字符,若不想转义在前面加一个r即可
2、以写方式打开文件,如果没有文件,则创建
with语句
(注意with下调用方法,别名点操作,见案例)
with语句使用的技术是一种称为上下文管理协议的技术
自动判断文件的作用域,自动关闭不在使用的打开的文件句柄
此语句自动关闭
格式:with open(r"路径或文件名",‘打开方式’) as f
pass
第一个参数r往往会遇到转义字符,若不想转义在前面加一个r即可
with open(r"a.txt",'r') as f:
strline=f.readline()
#此结构保证能够完整读取文件直到结束
while strline:
print(strline)
strline=f.readline
#上面代码会报错,UnoDeDebug错误:解码的时候读取文件和编辑器所用的编码导致的(在此我读的文档为UTF-8,可能pycharm为GBK)
#在括号里加上,encoding='UTF-8'即可
readline:按行读取文件内容
list
能用打开的文件作为参数,把文件内每一行内容作为一个元素
with open(r"tec.txt",'r',encoding='UTF-8') as f:
s=list(f)
for line in s:
print(line)
#或者with open(r"tec.txt",'rb') as f:
read
按字符读取文件内容
允许输入参数决定读取几个字符,如果没有指定,从当前位置读到结尾
否则,从当前位置读到指定个数字符
with open(r"tec.txt",'r',encoding='UTF-8') as f:
st=f.read(1)#参数表示读取几个
for line in st:
print(line)
seek
移动文件的读取,也叫读取指针
from的取值范围
0:从文件头开始偏移
1:从文件当前位置开始偏移
2:从文件末尾开始偏移
移动的单位是字节
一个汉字由若干个字节构成
返回文件只针对当前位置
#从第五个字节开始读取
#打开读写指针在0处,即文件的开头
with open(r"tec.txt",'rb') as f:
f.seek(6,0)
#seek(<偏移量或移动的单位>,<开始处>) seek移动单位是字节
dtr=f.read()
print(dtr)
#若4会报错因为编码方式上出现问题,一个汉字由若干个字节构成,应该从第零个开始,改变一下偏移量,即跳过
tell函数
用来显示文件读写指针的当前位置
#tell返回的数字单位是byte
#read是以字符为单位的
with open(r'tt.txt','r',encoding='UTF-8') as p:
str=p.read(2)
dd=p.tell()
while str:
print(dd)
print(str)
str=p.read(2)
dd=p.tell()
文件的写操作
write(str)——把字符串写入文件
writelines(str)——把字符串按行写入文件
区别:write参数只能是字符串
writelines可以是字符串,也可以是字符序列。可以写入很多行,参数可以是列表形式
#tell返回的数字单位是byte
#read是以字符为单位的
file=['nn','s']
with open(r'tt.txt','a',encoding='UTF-8') as p:
#a代表以追加方式打开
p.write("\n 燕雀安知鸿鹄")
p.writelines("远方有你有我——等着")
p.writelines(file)
pickle
序列化(持久化、落地):把程序运行中的信息保存在磁盘上
反序列化:序列化的逆过程
pickle:python提供序列化的模块
pickle.dump:序列化
pickle.load:反序列化
格式:pickle.dump(<插入的元素>,<打开文件的名>)序列化外置,反序列化内置或变量赋值的形式
具体格式见案例
import pickle as t
age=["jin",'tian','wo','hen']
with open(r'tt.txt','wb') as p:
t.dump(age,p)
#反序列化
import pickle as t
with open(r'tt.txt','rb') as o:
age=t.load(o)
print(age)
持久化-shelve
持久化工具
类似字典,用键值对保存数据,存取方式跟字典类似
shelve自动创建的不仅仅是一个shv.db文件,还包括其他文件格式
import shelve as w
#shv相当于一个字典
shv=w.open(r'sh.db')
shv['one']=1
shv.close()
#shelve自动创建的不仅仅是一个shv.db文件,还包括其他文件格式
'''
读取
'''
import shelve as f
try:
sh=f.open(r'shv.db')
print(sh['one'])
except:
print('真烦人')
finally:
sh.close()
shelve不支持多个应用并行写入
为解决这个问题,open 的时候可以使用flag=r
写回问题
不会等待持久化对象进行任何修改
解决:强制写回:writeback=True
一旦shelve关闭,则内容还是存在于内存中,没有写回数据库
shelve忘记写回,需要使用强制写回
import shelve as f
sh=f.open(r'shv.db')
try:
sh['one']={"s":1,"d":2}
finally:
sh.close()
sh=f.open(r'shv.db')
try:
one=sh['one']
print(one)
finally:
sh.close()
shelve使用with管理上下文环境
import shelve as f
with f.open(r'shv.db',writeback=True) as shv:
m1=shv['one']
print(m1)
m1['a']=10000
with f.open(r'shv.db',writeback=True) as shv:
print(shv['one'])
LOG
logging模块提供模块级别的函数记录日志
日志相关的概念
日志:定期存取程序运行等信息,写日志只记录关键信息
日志的级别:(level)
不同的用户关注不同的程序信息
- DEBUG
- INFO
- NOTICE
- WARNING
- ERROR
- CRITICAL
- ALERT
- EMERGENCY
IO操作不要频繁操作
LOG作用
调试
–了解软件的运行情况
–分析定位问题
日志信息:time、地点、level、内容
logging模块
级别可自定义(由低到高)
–DEBUG
–INFO
–WARNING
–ERROR
–CRITICAL
写日志实例需要指定级别,只有当级别等于或高于指定级别才能被记录
使用方式:直接使用logging模块(封装了其它组件)
logging四大组件直接定制
logging模块级别的日志
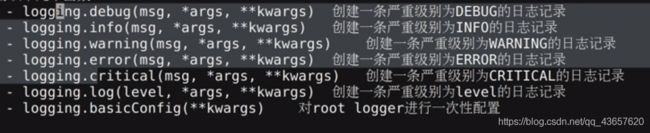
logging.basicConfig(**kwargs)对root logger进行一次性配置
-只在第一次调用时起作用
-不配置使用默认值
----输出:sys.stderr
----级别:WARNING
----格式:level:log_name:content
import logging as t
#也可以定义自己的日志书写格式
LOG_FORMAT="%(asctime)s======%(levelname)s+++++++%(message)s"
#要改的话使用t.basicConfig(level=p.DEBUG)
#一旦配置了级别凡是低于它的将不会显示出来
t.basicConfig(filename="python.log",level=p.DEBUG,format=LOG_FORMAT)
#执行上面这条语句结果将会被保存在该文件中,同样一旦配置了级别凡是低于它的将不会显示出来
t.debug("is a debug log")
t.info("is a info log")
t.warning("is a warning log")
t.error("is a error log")
t.critical("is a critical log")
#下方为另一种写法
t.log(t.DEBUG,"is a debug log")
t.log(t.INFO,"is a info log")
t.log(t.WARNING,"is a warning log")
t.log(t.ERROR,"is a error log")
t.log(t.CRITICAL,"is a error log")
'''
显示结果如下
WARNING:root:is a warning log
ERROR:root:is a error log
CRITICAL:root:is a critical log
WARNING:root:is a warning log
ERROR:root:is a error log
CRITICAL:root:is a error log
'''
#显示结果按原理将显示十条日志,但显示了6个
#日志是有级别的低于日志级别的不能显示,没配置默认显示WARNING
'''
级别(由低到高)
--DEBUG
--INFO
--WARNING
--ERROR
--CRITICAL
所以结果显示以上结果
'''
format参数

logging模块的处理流程
四大组件
- 日志器(Logger):产生日志的接口
- 处理器(Handler):把产生的日志发送到相应的目的地
- 过滤器(Filter):更精细的控制那些日志输出
- 格式器(Formatter):对输出信息进行格式化
1、ogger:产生一个日志
操作:
logger.setLevel()设置日志器将会处理的日志消息的最低严重级别logger.addHandler()和logger.removeHandler()为该logger对象添加和移除一个Handlerlogger.addFilter()和logger.removeFilter() 为该logger对象添加和移除一个filterlogger.debug 产生一条debug级别的日志,同理,Info、errorlogger.exception()创建类似于logger.error的日志消息logger.log() 获取一个明确的日志level参数类创建一个日志记录
如何得到一个logger对象
实例化
即:logging.getLogger()
2、Handler
把log发送到指定位置


多线程
程序:一堆代码以文本形式存进一个文档里
进程:程序运行的一个状态。
线程:一个进程的独立运行片段,一个进程可以有多个线程
更新中