深入理解并行编程一
这里写自定义目录标题
- 并行编程
- 并行编程的目标
- 是什么使并行编程变得复杂
- 工作分割
- 并行访问控制
- 资源分割和复制
- 与硬件交互
- 硬件的习性
- 概述
- CPU 流水线
- 内存引用
- 原子操作
- 内存屏障
- Cache Miss
- I/O 操作
- 开销
- 硬件体系结构
- 操作的开销
- 工具
- 脚本语言
- POSIX 多进程
- POSIX进程创建和销毁
- POSIX线程创建和销毁
- POSIX 锁
- POSIX 读写锁
- 原子操作
- 计数
- 统计计数器
- 近似上限计数器
- 精确上限计数器
- 原子上限计数器
- Signal-Theft 上限计数器
并行编程
并行编程的目标
- 相对于串行编程来说,并行编程有如下三个主要目标:
- 性能
- 生产率
- 通用性
是什么使并行编程变得复杂
工作分割
每个线程都会占用一些资源, 比如 CPU cache 空间。如果过多的线程同时执行,CPU cache将会溢出,引起过高的cache miss,从而降低性能。
大量的线程可能会带来大量计算和 I/O 操作。
合法的并行线程会大量增加程序的状态空间,导致程序难以理解,降低生产率。
并行访问控制
资源分割和复制
与硬件交互
硬件的习性
概述
CPU 流水线
如果程序中带有许多循环,且循环计数都比较小;
或者面向对象的程序中带有许多虚对象,每个虚对象都可以引用不同的实对象,而这些实对象都有频繁被调用的成员函数的不同实现,此时 CPU很难或者完全不可能预测某个分支的走向。
这样CPU要么等待控制流进行到足以知道分支走向的方向时,要么干脆猜测——由于此时程序的控制流不可预测——CPU常常猜错。在这两种情况中,流水线都是空的,CPU需要等待流水线被新指令填充,这将大幅降低CPU的性能。
内存引用
虽然现代微型计算机上的大型缓存极大地减少了内存访问延迟,但是只有高度可预测的数据访问模式才能让缓存发挥最大效用。
不幸的是,一般像遍历链表这样的操作的内存访问模式非常难以预测。
原子操作
有一些指令是流水线必须延迟甚至需要冲刷, 以便一条原子操作成功完成。
内存屏障
由于内存屏障的作用是防止CPU为了提升性能而进行的乱序执行,所以内存屏障几乎一定会降低CPU性能。
spin_lock(&mylock);
a = a + 1;
spin_unlock(&mylock);
Cache Miss
现代CPU使用大容量的高速缓存来降低由于较低的内存访问速度带来的性能惩罚。
但是,CPU高速缓存事实上对多CPU间频繁访问的变量起反效果。因为当某个CPU想去更改变量的值时,极有可能该变量的值刚被其他CPU修改过。在这种情况下,变量存在于其他CPU而不是当前CPU的缓存中,这将导致代价高昂的Cache Miss。
I/O 操作
I/O操作涉及网络、大容量存储器,或者(更糟的)人类本身,I/O操作对性能的影响远远大于之前提到的各种障碍。
开销
硬件体系结构

数据以“缓存线”为单位在系统中传输,“缓存线”对应于内存中一个2的 幂大小的字节块,大小通常为32到256字节之间。
当CPU从内存中读取一个变量到它的寄存器中时,必须首先将包含了该变量的缓存线读取到CPU高速缓存。
同样地,CPU将寄存器中的一个值存储到内存时,不仅必须将包含了该值的缓存线读到CPU高速缓存,还必须确保没有其他CPU拥有该缓存线的拷贝。
操作的开销
| Operation | Cost (ns) | Ratio (cost/clock) |
|---|---|---|
| Clock period | 0.6 | 1.0 |
| Best-case CAS | 37.9 | 63.2 |
| Best-case lock | 65.6 | 109.3 |
| Single cache miss | 139.5 | 232.5 |
| CAS cache miss | 306.0 | 510.0 |
| Comms Fabric | 5,000 | 8,330 |
| Global Comms | 195,000,000 | 325,000,000 |
工具
脚本语言
1、创建新进程的开销是很大的,它包括代价高昂的fork()和exec()系统调用。
2、包括管道这样的共享数据操作,通常会包括代价高昂的文件I/O。
3、脚本可用的同步原语,通常也包括代价高昂的文件I/O。
POSIX 多进程
POSIX进程创建和销毁
进程通过fork()原语创建,使用kill()原语销毁,也可以用exit()原语自我销 毁。执行fork()的进程被称为新创建进程的“父进程”。父进程可以通过wait()原语等待子进程执行完毕。父进程和子进程并不共享内存。
pid_t fork(void);
pid_t wait(int *stat_loc);
POSIX线程创建和销毁
在一个已有的进程中创建线程,需要调用pthread_create()原语,pthread_join()原语是对进程的wait()的模仿,它一直阻塞到tid变量指定的线程返回。线程返回有两种方式,要么调用pthread_exit()返回, 要么通过线程的顶层函数返回。
int pthread_create(pthread_t *thread, const pthread_attr_t *attr, void *(*start_routine)(void *), void *arg);
int pthread_join(pthread_t thread, void **value_ptr);
POSIX 锁
POSIX锁包括几个原语,其中最基础的是pthread_mutex_lock()和 pthread_mutex_unlock()。这些原语操作类型为pthread_mutex_t 的锁。该锁的静态声明和初始化由 PTHREAD_MUTEX_INITIALIZER完成,或者由pthread_mutex_init()原语来动态分配并初始化。
POSIX 读写锁
POSIX API提供了一种读写锁,用pthread_rwlock_t 类型来表示。和pthread_mutex_t一样,pthread_rwlock_t也可以由PTHREAD_RWLOCK_INITILIZER静态初始化,或者由pthread_rwlock_init()原语动态初始化。
pthread_rwlock_rdlock()原语获取pthread_rwlock_t的读锁,pthread_rwlock_wrlock()获取它的写锁,pthread_rwlock_unlock()原语负责释放锁。
在任意时刻只能有一个线程持有给定pthread_rwlock_t的写锁,但同时可以有多个线程持有给定pthread_rwlock_t的读锁,至少在没有线程持有写锁时是如此。
在临界区较小时,读写锁性能未必有mutex好。
由于所有想获取读锁的线程都要更新pthread_rwlock_t的数据结构。(读的数目)因此,一旦全部线程同时尝试获取读写锁的读锁,那么这些线程必须一个一个的更新读锁中的pthread_rwlock_t结构。
原子操作
读写锁在临界区最小时开销最大,考虑到这一点,那么最好能有其他手段来保护极其短小的临界区。
gcc 编译器提供了许多附加的原子操作,__sync(如__sync_fetch_and_and())。
有一对原语提供了经典的“比较并交换”操作, __sync_bool_compare_and_swap()和__sync_val_compare_and_swap()。
__sync_synchronize()原语是一个“内存屏障”,它限制编译器和CPU对指令乱序执行的优化。
在某些情况下,只限制编译器对指令的优化就足够了,CPU的优化可以保留,此时就需要使用**barrier()原语。在某些情况下,只需要让编译器不优化某个内存访问就行了, 此时可以使用ACCESS_ONCE()**原语。这两个原语不是由 gcc 直接提供的,可以如下实现:
#define ACCESS_ONCE(x) (*(volatile typeof(x) *)&(x))
#define barrier() __asm__ __volatile__("": : : "memory")
计数
统计计数器
统计计数一般以每个线程一个计数器的方式处理(或者在内核运行时,每个 CPU 一个),所以每个线程只更新自己的计数器。根据加法的交换律和结合律, 总的计数值就是所有线程计数器值的简单相加。
基于每线程变量__thread的实现,因为线程退出变量就没了,所以要加锁(可用全局数组替代)。
显然本节只是保持“结果一致性”。
近似上限计数器
维护一个每线程计数器的上限值。当超过这个上限时,线程将自己的计数加到全局计数器上。在减少计数值时利用上全局计数器,否则每线程计数器的值就可能降到0以下。
如果这个上限(设为countermax)足够大,那么几乎所有的加减操作都是在每线程计数器中执行的,这就给我们带来了良好的性能和可扩展性。
但是,每线程变量countermax 的使用表明即使未到达上限,加减操作也可能会失败(毕竟已经把max近似当做满荷了)。
精确上限计数器
原子上限计数器
主要是精确计算每个线程内剩余计数,通过清零的方式。
static void flush_local_count(void)
{
int c; int cm; int old; int t; int zero;
if (globalreserve == 0) return;
zero = merge_ctrandmax(0, 0);
for_each_thread(t)
if (counterp[t] != NULL) {
old = atomic_xchg(counterp[t], zero);
split_ctrandmax_int(old, &c, &cm);
globalcount += c;
globalreserve -= cm;
}
}
Signal-Theft 上限计数器
这个思路其实是用信号量来完成状态机的状态通知。
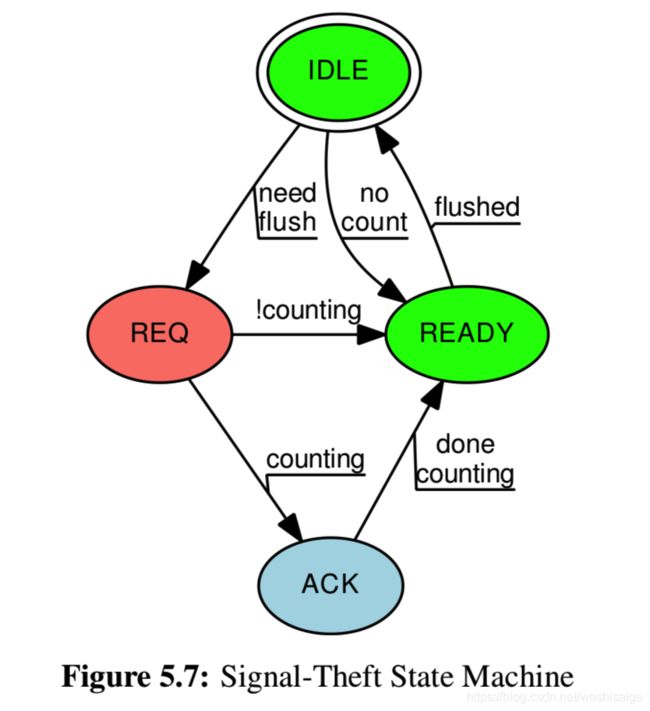
状态机从 IDLE 状态开始,当进入慢速路径(需要计算别的线程剩余可用个数)时将每个线程的theft状态设置为 REQ(除非线程没有计数值,这样它就直接转为READY)。
然后慢速路径向每个线程发送一个信号,对应的信号处理函数检查本线程的theft和counting状态。
**一旦慢速路径发现某个线程的theft状态为READY,这时慢速路径有权窃取此线程的计数。**然后慢速路径将线程的theft状态设置为IDLE。
static void flush_local_count(void)
{
int t;
thread_id_t tid;
for_each_tid(t, tid)
if (theftp[t] != NULL) {
if (*countermaxp[t] == 0) {
WRITE_ONCE(*theftp[t], THEFT_READY);
continue;
}
WRITE_ONCE(*theftp[t], THEFT_REQ);
pthread_kill(tid, SIGUSR1);
}
for_each_tid(t, tid) {
if (theftp[t] == NULL)
continue;
while (READ_ONCE(*theftp[t]) != THEFT_READY) {
poll(NULL, 0, 1);
if (READ_ONCE(*theftp[t]) == THEFT_REQ)
pthread_kill(tid, SIGUSR1);
}
globalcount += *counterp[t];
*counterp[t] = 0;
globalreserve -= *countermaxp[t];
*countermaxp[t] = 0;
WRITE_ONCE(*theftp[t], THEFT_IDLE);
}
}
信号处理函数检查本线程的theft和counting状态。
static void flush_local_count_sig(int unused)
{
if (READ_ONCE(theft) != THEFT_REQ)
return;
smp_mb();
WRITE_ONCE(theft, THEFT_ACK);
if (!counting) {
WRITE_ONCE(theft, THEFT_READY);
}
smp_mb();
}
如果theft状态是ACK,当快速路径完成时,会将theft状态设置为READY(信号量何时中断线程未知,稍微思考下可能情况就好理解)。