Cascade RPN,结构的艺术带来极致提升 | NeurIPS 2019
 作者 | VincentLee
作者 | VincentLee
来源 | 晓飞的算法工程笔记(ID: gh_084c810bc839)
导读:论文提出Cascade RPN算法来提升RPN模块的性能,该算法重点解决了RPN在迭代时anchor和feature不对齐的问题,论文创新点足,效果也很惊艳,相对于原始的RPN提升13.4%AR。

论文地址:https://arxiv.org/abs/1909.06720
代码地址:https://github.com/thangvubk/Cascade-RPN
简介
目前,性能高的目标检测网络大都为two-stage(RPN+R-CNN)架构,相对于R-CNN,很少有研究专门去提升RPN的性能。因此,论文着重研究如何提升RPN的性能,解决其探索性的achor定义以及探索性的feature与anchor对齐的局限性。
anchor由尺寸和长宽比定义,常规算法会使用一系列不同尺寸和长宽比的anchor来充分覆盖检测目标。设定合适的尺寸和长宽比是提升性能的关键,这通常需要一顿tuning。
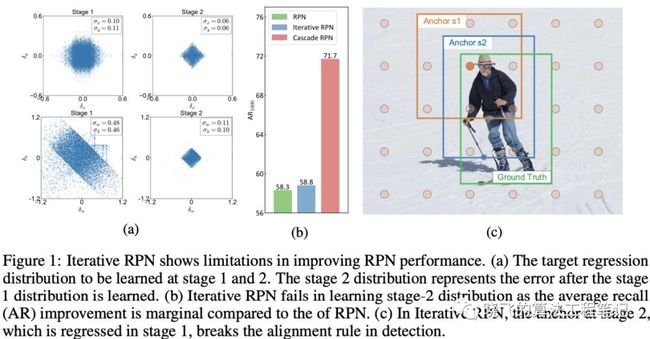
论文重点强调对齐规则,即图片特征和anchor必须是一致的。如图1a所示,由于RPN的anchor是均匀分布的,其方差十分大,难以学习,需要进行迭代回归。但RPN没有类似RoIPool或RoIAlign的手段进行特征对齐,因为RPN的输入很多,性能十分重要,只能进行常规的滑动卷积进行输出,这就造成了anchor和feature的对称问题。如图2b,可以看到Iterative RPN的收益是微乎其微的,这是由于在iterative RPN中,stage2的anchor与其特征不对齐(依然均匀地卷积),如图1c,stage2的输入anchor精调了,但是stage2卷积时使用的特征区域还是精调之前的
论文提出Cascade RPN来系统地解决前面提到的问题,算法主要有两个特点:
Cascade RPN使用单anchor,并且结合anchor-based和anchor-free的准则来进行正样本的判定
为了获得多stage精调的好处并且保持特征和anchor对齐,Cascade RPN使用自适应卷积来精调每个stage的anchor,自适应卷积可以当作是个轻量级的RoI Align层
Cascade RPN简单但有效,能比原生RPN高出13.4%AR,并且能集成到two-stage检测器中,如Fast R-CNN和Faster R-CNN分别提升3.1%和3.5%
区域提案网络和变体
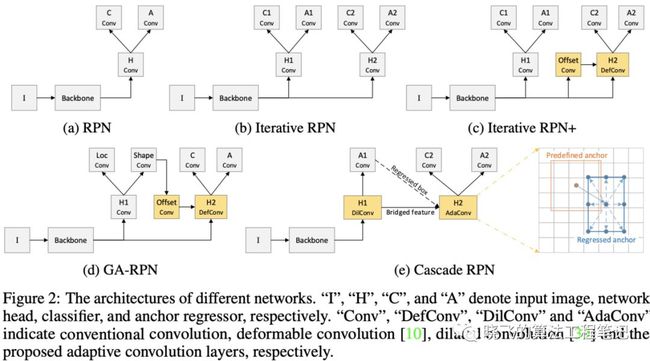
文中简单介绍了RPN的概念,如图1a,通过卷积回归当前anchor与GT间的差值来进行精调,相信大家都比较了解了,这里就不再赘述了
迭代RPN和变体
Iterative RPN的架构如图2b所示,通过迭代回归得出不同stage的差值,然后按顺序对anchor进行精调。从结构来看,如上所述,这样的方法收益是微乎其微的,因为其特征与anchor是不对齐的
为了缓解对齐问题,一些研究使用可变形卷积来进行特征图上的空间变换,希望能使得精调后的anchor与变换后的特征对齐,如图2cd。但是这种方法并没有严格的约束去保证特征与变换后的anchor对齐,也很难确定变换后的特征和anchor是否对齐了
Cascade RPN
Adaptive Convolution
对于feature map x,标准的二维卷积先通过网格 采样,然后与权重w加权求和。 由卷积核大小与膨胀(dilation)定义,如对应卷积核大小为3x3和膨胀为1。对于位置p的特征输出y,定义为
在自适应卷积中,网格 替换为从输入anchor计算出的偏移
让 定义为a在特征图上的精调后的anchor,偏移o可以分解为中心偏移和形状偏移
其中, 为中心点偏移量, 是形状偏移量,由anchor的形状和卷积核大小决定。假设卷积核大小为3x3,则,由于偏移量是小数,采样时使用双线性插值
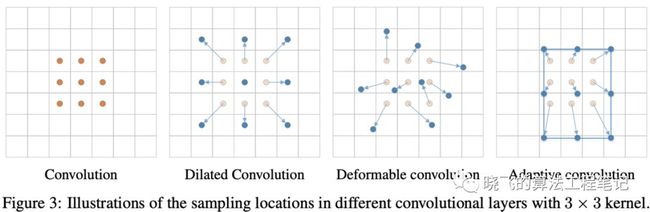
如图3所示,常规卷积连续地采样特征,空洞卷积则根据膨胀按间隔采样特征,可变形卷积则根据学习的偏移来增大采样的空间位置,这是不规则的。而论文提出的自适应卷积则能保证在anchor内进行采样,是规则的,确保特征与anchor对齐
Sample Discrimination Metrics
Cascade RPN每个位置仅使用一个anchor box,然后使用多stage的精调。在判定anchor的正负时,单纯地使用anchor-free或anchor-base方法都是不行的,因为使用anchor-free标准会导致stage2要求太低,而使用anchor-base则会导致stage1不能回归足够多的正样本。因此,Cascade RPN在stage1使用anchor-free标准,即中心点在GT center内即为正,而往后的stage则使用anchor-base标准,根据IoU进行判断
Cascade RPN
Cascade RPN的架构如图2e所示,依靠自适应卷积来对齐特征和anchor。在stage1,自适应卷积可以认为是空洞卷积,因为anchor中心偏移为0,膨胀量根据shape而定。stage1的特征输出会连接到下一个阶段,因为其包含当前anchor的空间信息

整体流程如公式1,stage1的anchor集合 是均匀分布在图片上的,而在stage ,计算出anchor的偏移 并通过regressor 计算出回归值 ,再产生精调的anchor 。在最后的阶段,通过classifer计算出分类置信度,然后再进行NMS得出最后的结果
Learning

Cascade RPN可以通过多任务的end-to-end方式进行训练,其中 是stage 回归loss,权重为 , 则是分类的loss,两个loss通过 进行权重调整。在实现时,分类使用二值交叉熵而回归使用IoU loss。
实验
实验设置
实验的模型以ResNet50-FPN作为主干,每个特征level使用的尺寸为 , , , , 。FPN采用two-stage,第一阶段使用anchor-free标准,center-region 和ignore-region 分别为0.2和0.5,第二阶段使用anchor-based标准,IoU阈值为0.7。multi-task loss的stage-wise权重 ,平衡权重 ,NMS阈值为0.8。实验将图片等比缩放为 ,不使用其余数据增强手段,在8GPU上用SGD训练12个epoch,batch 16,初始学习率为0.02,8周期和11周期降低10倍。RPN的性能用AR来衡量,最终的检测结果则以AP进行衡量
Benchmarking结果
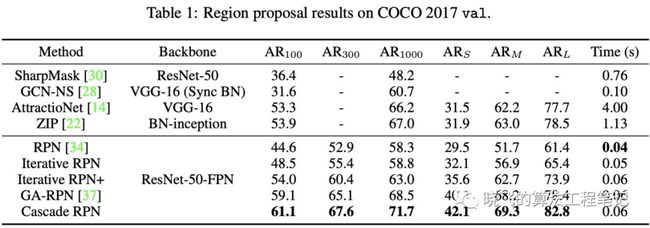
Region Proposal Performance.Table1展示了Cascade RPN与state-of-the-art的RPN研究对比,其中Sharp Mask,GCN-NS,AttractionNet,ZIP结果直接从原文里获取,其余用mmdetection复现。Cascade RPN比原始的RPN提升了13.4%AR,由于遵守了对齐规则,Cascade RPN比其它的方法性能都要优异

Detection Performance.Table2展示了集成进two-stage检测器后的整体性能表现,Fast RCNN使用预先计算的anchor进行训练,而Faster RCNN则是end-to-end的。直接替换RPN的实验结果只有很小收益,需要修改一下实验参数,设定IoU阈值为0.65,只取top300 anchor。从结果看来,top300时在两个框架下分别提升了3.5%mAP和3.7%mAP
消融研究

Component-wise Analysis. 为了进一步了解Cascade RPN性能,进行了component-wise的实验。baseline是anchors为3的RPN, 为58.3,当anchor为1时, 降到55.8,意味着正样本的大幅减少。而当使用自适应卷积使用时,性能提升为67.8,这意味着对齐在多阶段精调的重要性。混合anchor-free和anchor-based准则带来了0.8%的提升,使用回归统计(对回归差值进行归一化)带来2.9%AR收益,IoU loss带来0.2%的提升

Acquisition of Alignment. 为了研究自适应卷积的性能,进行了Table4实验。从结果可以看出,当仅使用中心偏移时,提升6.1%AR,而当使用中心和形状偏移时,性能达到67.8%
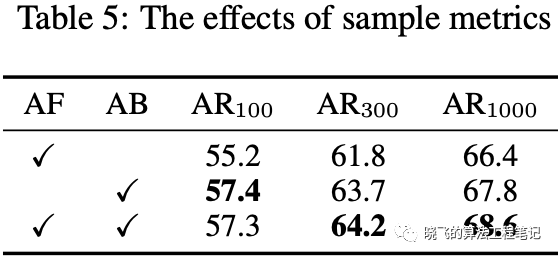
Sample Discrimination Metrics. Table5展示了采用标准的性能测试,从结果看来,单独使用anchor-free或anchor-based标准是不完美的,同时使用能带来很好的效果

Qualitative Evaluation. 图4的第一和第二行图片为stage1的结果,第三行为stage2的结果,可以看到,stage2的结果要好点

Number of Stages. Table6展示了stage数量对结果的影响,可以看到2-stage和3-stage性能几乎一样,2-stage是个不错的选择
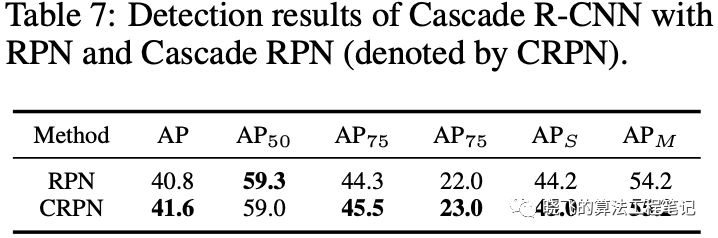
Extension with Cascade R-CNN. 在Cascade R-CNN上,Cascade RPN能提升0.8%AP
结论
论文提出优化版的Cascade RPN,该架构能够有效地解决RPN中anchor和feature的对齐问题,相对于原始的RPN,能提升13.4%AR,是个很不错的架构。
(*本文为AI科技大本营转载文章,转载请联系原作者)
◆
精彩推荐
◆
人工智能数学基础系列公开课通过人工智能热点问题开始,引出其中蕴涵的数学原理,然后构建解决实际问题的数学模型和方法,兼具趣味性与实用性。
1月16日晚8:00, 哈工大屈教授在线直播课---『看得见 』的数学,带大家解密计算机视觉背后的数学知识!
点击阅读原文,或扫描海报二维码免费报名
加入公开课福利群,每周还有精选学习资料、技术图书等福利发送、60+公开课免费学习

推荐阅读
Python 三十大实践、建议和技巧
2020年AI 2000最具影响力学者榜单发布,何恺明排名超过李飞飞
达摩院 2020 预测:模块化降低芯片设计门槛 | 问底中国 IT 技术演进
在调查过基于模型的强化学习方法后,我们得到这些结论
千万不要和程序员一起合租
人工智能的下一个前沿:识别“零”和“无”
十大新兴前端框架大盘点
Oracle 抄袭亚马逊的 API 是侵权吗?
2019全年盘点之一:公链生死战场

你点的每个“在看”,我都认真当成了AI