浅析DirectX11技术带给图形业界的改变
浅析DirectX11技术带给图形业界的改变
前言:2009年10月23日,微软高调发布了其最新一代操作系统——Windows7,这款操作系统相对于之前的Vista系统有相当大的进步,特别核心执行效率方面得到显著改善,并且加入了DirectX 11等新技术。微软此次推出全新图形API——DirectX 11目的很明确,就是能够充分利用显卡资源,旨在游戏以及通用计算方面达到更高的执行效率。今天本文就带大家一起分析DirectX 11技术带给图形业界和游戏玩家的双重体验。同时也让更多人了解到自己是否需要一款支持DirectX 11的显卡,具体选择哪些显卡最为合适。

● DirectX对GPU发展带来的影响
DirectX并不是一个单纯的图形API,它是由微软公司开发的用途广泛的API,它包含有Direct Graphics(Direct 3D+Direct Draw)、Direct Input、Direct Play、Direct Sound、Direct Show、Direct Setup、Direct Media Objects等多个组件,它提供了一整套的多媒体接口方案。只是其在3D图形方面的优秀表现,让它的其它几个组件几乎被人们忽略。
Direct Graphics的优秀表现和微软的影响力,令无数硬件厂商生畏并不断遵循其变化来开发新的图形处理器架构。同时ATI和NVIDIA两家厂商之所以至今仍不断跟随DirectX的步伐,是意识到任何游戏相关的硬件厂商要是被微软抛弃,那么其后果是不堪设想的。

大家都在畅想DirectX技术的未来
在过去的数次DirectX更替中,有几次较大的更新,比如我们熟知的从DirectX 7到DirectX 8到DirectX 9到再DirectX 10,也是因为这样的理由使得芯片变得更大。在向DirectX 8的转移使得可编程的硬件进入管线成为了双重构造。对于DirectX 9的顶点处理与像素处理,则被真正的可编程处理器调换。而在向DirectX 10的转移为了实现更灵活的可编程性,需要GPU架构进行根本的改革。
所以哪个世代的改变以及生产什么样的GPU都关乎根本性的改革,而这种改革基本上都是围绕DirectX这个最重要的图形API来进行的。特别是DirectX 10时代架构的改革,从根本上改变了GPU的本质。从DirectX 8向DirectX 9通过API的改革牵动了GPU架构的改革,而架构巨大变化的转折点则是DirectX 10。

DirectX 10时代 着色器单元走向统一
在DirectX 10时代,我们非常有幸看到了Pixel Shader(顶点着色器)、Vertex Shader(像素着色器)和Geometry Shader(几何着色器),三种具体的硬件逻辑被整合为一个全功能的着色器Shader。但是我们也发现,GPU在性能提升的同时,芯片规模发生了更快速的放大,这不得不让人担心未来GPU的功耗和发热等等问题。
事实上芯片变大有两个主要原因。一个是因为性能的增加。要提高运算性能就会需要更多的资源,这会增加晶体管的数量。另一个就是为了发展可编程化。需要让单一的可编程处理器包括个别进行处理的固定功能硬件,这必然也会增加晶体管数量。可是这样会让性能出现大幅度下滑,因此为了保持同样的性能也需要大幅度增加运算资源。结果就是对于GPU的情况需要从固定硬用向可编程硬件转换,晶体管数和核心尺寸也因此而增加。
直到今天我们看到的DirectX 11出现,这个问题得到了一个平衡的解决方案。DirectX 10带来了众多绚丽无比的新特效,但“滥用”各种特效最终导致GPU不堪重负。在DirectX 10经历了种种波折,瓶颈尽显时,微软也开始将重心集中在如何提升算法和效率上面,而不是一味的加入新特效或提高模型复杂度。因此我们看到的DirectX 11,已经将技术重心放在如何用最小的硬件开销在先进图形技术的辅助下实现最佳的渲染效果。
| 濮元恺所写过的技术分析类文章索引(持续更新) | |||
| NVIDIA/ATI命运转折 |
改变翻天覆地 |
显卡只能玩游戏? 10年GPU通用计算回顾 |
通用计算对决 |
| 从裸奔到全身武装 |
AMD统一渲染架构 |
浅析DirectX11技术 |
摩尔定律全靠它 |
| 我就喜欢 |
别浪费你的电脑 分布式计算在中国 |
从Folding@home项目 |
Computex独家泄密 解析AMD下代GPU |

DirectX 11带来的全新特性
● DirectX 11带来的全新特性
DirectX 11作为一套全新的图形API,提供给图形开发者和用户极大的想象空间,同时降低了开发难度,节省硬件资源,特别是后两个特点,是DirectX 11区别与以往的DirectX最为显著的特点。
2009年NVISION大会上,微软就透漏了DirectX 11的大量细节,此时DirectX 11已经完全成熟并获得硬件厂商支持,就等和Win7操作系统一同上市了。同时借助SIGGRAPH以及GameFest 2008大会上放出的幻灯片,我们可以进行一些深入的研究。此外,DX11特性的提前放出,对于目前DX10以及DX10.1硬件用户而言也很有帮助,因为AMD和NVIDIA可以照此提前开发适当的驱动支持。

2008年度NVISION资料截图
回顾历次DirectX的更替过程,几乎都对GPU架构产生了颠覆性的影响,它们大部分要求GPU改变现有的着色器Shader单元结构,或者为着色器Shader单元追加资源,这些改进都是为了让GPU的指令数提升,寄存器数量增加,纹理规模提升,材质Texture精度提升。这样的改进难免带来晶体管数量的增长,也就说说GPU内部的每个着色器Shader单元变得更加庞大。
DirectX 11发布后,人们发现微软并没有在Shader Model方面做出重要提升,虽然版本升至Shader Model 5.0,但是更重要的是它实际上可以被看作是DirectX 10和DirectX 10.1的功能补全,你也可以认为它是DirectX 10和DirectX 10.1的超集,如果换个角度大胆设想,我们今天看到的DirectX 11才是微软想要的DirectX 10完美形态。
DirectX 11针对不同方面带来了全新的特性,目前通过现有资料分析,它主要有以下几个方面的提升:

DirectX 11带来的全新特性
● 着色器版本提升到Shader Model 5.0,采用面向对象的概念,并且完全可以支持双精度数据。
● Tessellation曲面细分技术获得微软正式支持,逐渐走向成熟;
● Multithreading多线程处理,让图形处理面对多线程编程环境不再尴尬;
● 提出微软自己的Compute Shader通用计算概念,把GPU通用计算推向新的巅峰;
● 新的Texture Compression纹理压缩方案,在画质损失极小的环境下带来了硬件资源的节约。
在今天的分析中,我们将重点放在Tessellation曲面细分技术方面,因为这是DirectX 11最为突出的特色之一,也是给图形运算产生深远影响的一项技术,DirectX 11的其他特点我们也会提及。
Tessellation技术简析
● Tessellation技术简析
Tessellation又可译作拆嵌式细分曲面技术。其实这是ATI早在其第一代DirectX 10图形核心R600,即HD2900XT上就引入的一个特殊的计算模块。从HD2000系列开始,直到最新的HD5000系列,整整4代显卡全部支持这一技术。即使目前也仍然没有游戏能够支持这一技术,ATI也依然没有放弃在这项技术上的努力——从名字上也可以看出ATI在这项技术上的心血:Tessell-ATI-on。
Tessellation主要是靠GPU内部的一个模块Programmable Tessellator(可编程拆嵌器)来实现的。能够根据3D模型中已经有的顶点,根据不同的需求,按照不同的规则,进行插值,将一个多边形拆分成为多个多边形。而这个过程都是可以由编程来控制的,这样就很好的解决了效率和效果的矛盾。TessellATIon能自动创造出数百倍与原始模型的顶点,这些不是虚拟的顶点,而是实实在在的顶点,效果是等同于建模的时候直接设计出来的。

Tessellation工作流程三部曲
很明显,DirectX 11中的Tessellation让雪山的凹凸感更为明显,远胜于DirectX 10里所采用的视差映射贴图技术。虽然后者在较远距离观看的时候也能提供一定的视觉欺骗性,但和 Tessellation技术塑造出来的真实感觉还相差太远。我们使用的分析图来自AMD在R600发布时放出的一段Demo,这段Demo区别于以往的设计方式,它没有突出主角而淡化背景,因为在没有Tessellation技术之前,大量顶点的生成和随之而来的计算将给GPU的几何处理部分带来巨大压力,无法流畅运行,而Tessellation技术改变了这一模式。
除了大幅提升模型细节和画质外,Tessellation最吸引程序员的地方就是:他们无需手动设计上百万个三角形的复杂模型,只需简单勾绘一个轮廓,剩下的就可以交给Tessellation技术自动拆嵌,大大提高了开发效率;而且简单的模型在GPU处理时也能大幅节约显存开销,令渲染速度大幅提升。
Tessellation技术历史回顾
● Tessellation技术历史回顾
Tessellation技术最早可以追溯到DX8时代,当时ATI就已经和微软联手开发了TruForm(N-Patch)技术,也就是Tessellation的前身,并被纳入DX8.1的范畴。
2001年,ATI公布了TruForm的技术细节,相关媒体也对这一技术进行了报道。简单地说TruForm技术就是将在芯片内部将游戏中的三角形转换成曲面然后再转换成一个新的三角形,这个三角形可以在场景中显示。
当三角形信息通过图形芯片时,TruForm技术开始工作,它通过创建N-Patch来形成N-Patch网格。
N-Patch网格是一个曲面,通过线性三角形信息来定义。N-Patches在三角形每个边放两个控制点,这样就产生了六个新的顶点。这些控制点都在一个单独的平面上,可以位于原三角形之下或者之上。使用储存在原三角形的顶点向量的信息,可以决定控制点的位置。
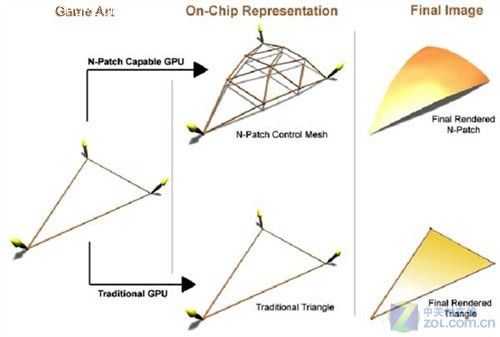
N-Patch技术示意图
当然,这并不是一个简单的工作,而这正是TruForm技术的用处所在。当时人们认为它是ATI下一代显卡Radeon2的独门武器。在当时GPU运算能力极为有限的情况下,N-Patch技术可以大幅提升3D模型的细节和显示效果。
但是它却出现了一些非常遗憾的失误,导致这项技术最终被用户放弃。因为N-Patch技术技术比较适合于海豚、赛车等表面为曲面的模型上,而如果这个技术应用在坦克等不需要做曲面化的模型上的时候,效果就会变得相当的滑稽。

Tessellation技术带来的3D流水线变化
N-Patch/TruForm技术就这样被市场边缘化,但是ATI还是没有放弃对它的开发和研究。终于在2005年出现了转机,在微软与ATI的合作结晶——专为XBOX360设计的图形芯片Xenos当中,经过改进的N-Patch/TruForm技术重出江湖,这次ATI将它直接命名为我们熟悉的TessellATIon,直译为“拆嵌”意译为“细分曲面”,同时表示ATI在这项技术中不可磨灭的贡献。
Tessellation技术拆解分析
● Tessellation技术拆解分析
Tessellation这个英文单词直译为“镶嵌”,也就是在顶点与顶点之间自动嵌入新的顶点。Tessellation经常被意译为“细分曲面”,因为在自动插入大量新的顶点之后,模型的曲面会被分得非常细腻,看上去更加平滑致密。它是一种能够在图形芯片内部自动创造顶点,使模型细化,从而获得更好画面效果的技术。Tessellation能自动创造出数百倍与原始模型的顶点,这些不是虚拟的顶点,而是实实在在的顶点,效果是等同于建模的时候直接设计出来的。
图形业界对于曲面细分的探索不断深入
在此之前,人们对低代价多边形操作法已经探索了近10年,从最开始的对三角形的fan操纵,到后来的龟裂和冲撞检查,这些方法可以实现曲面细分效果,但是对资源的消耗量太大不可控制。这次微软在DirectX 11中加入硬件Tessellation单元,我们可以视作曲面细分技术历经长时间的磨练后修成正果。虽然它不太符合通用处理单元的设计方向,但是如果计算晶体管的投入与性能回报,独立的硬件Tessellation单元是目前最好的选择。
Tessellation技术是完全可编程的,它提供了多种插值顶点位置的方法来创造各种曲面:
1. N-Patch曲面,就是和当年TruForm技术一样,根据基础三角形顶点的法线决定曲面;
2. 贝塞尔曲面,根据贝塞尔曲线的公式计算顶点的位置;
3. B-Spline、NURBs、NUBs曲线(这三种曲线均为CAD领域常用曲线,在Maya中均有相应工具可以生成)
4. 通过递归算法接近Catmull-Clark极限曲面。

不同方式的曲面细分效果实例
Tessellation技术最初主要被用以“细分曲面”,随着该技术被纳入DX11范畴,得到大范围推广之后,插值顶点的算法也越来越多,因此用途也越来越广,产生了很多非常有创意的应用。
Tessellation技术还经常与Displacement Maps(贴图置换)技术搭配使用,从而将平面纹理贴图改造成为具有立体感的几何图形,大大增强3D模型或场景的真实性。
除了大幅提升模型细节和画质外,Tessellation最吸引程序员的地方就是:他们无需手动设计上百万个三角形的复杂模型,只需简单勾绘一个轮廓,剩下的就可以交给Tessellation技术自动镶嵌,大大提高开发效率;而且简单的模型在GPU处理时也能大幅节约显存开销,同时大幅提升渲染速度。
DX11中引入可编程曲面细分管线
● DirectX 11引入可编程曲面细分管线
在DirectX10时代的细分曲面里,最有新用途的就是Geometry Shader和Stream Out,前者可以输入一些数据,然后产生一些三角形,后者可以断绝Pixel Shader,做完Geometry Shader就直接输出回Input Assembler,这就意味着可以做GPU递归和迭代。
而DirectX 11相比DirectX 10,Shader Model的变化并不算大,只是增加了5个全新的指令集。但是对于游戏开发者而言,Shader Model 5.0函数和子程序代码的开发都比上一代更加简单方便。增加的五个新指令集目的也是为了让编程者可以进行更灵活的数据访问和操作。
在Shader Model 5.0中,Shader进行了类型的统一,除了4.0版本中就已经有的Vertex Shader、Pixel Shader、Geometry Shader外,还增加了Hull Shader、Compute Shader、Domain Shader三种新的Shade,它们的出现都是为了完善曲面细分管线。

ATI的HD2000以上级别显卡其实都具备Tessellation的功能,但它们却无法与DX11中的Tessellation技术相兼容。这是因为微软并没有原封未动的将R600的Tessellation技术抄到DX11之中,而是对其进行了优化,使之能与渲染流程完美的结合在一起,可以更高效率的细分出更多的多边形和曲面。

与DX9C/DX10时代孤零零的Tessellator模块不同,在DX11当中,微软加入了两种全新着色器来全力配合Tessellator的工作,分别位于镶嵌器的前后。
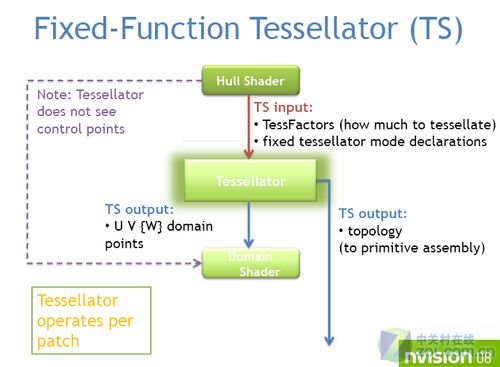
其中Hull Shader(外壳着色器)用来控制自动生成顶点的数量和算法,也就是Tessellator的细分级别,然后交给Tesselator进行镶嵌处理,最后由Domain Shader(域着色器)按照程序要求生成所需曲面,并自动进行法线平移、置换贴图,产生新的模型。

与DX9/10中的Tessellation技术相比,DX11新增的两种着色器都受统一渲染架构支配,因此处理能力非常富裕,DX11版Tessellation不仅效率更高、而且细分级别更丰富。但是,更高的细分等级对Tessellator模块本身的处理能力提出了苛刻要求,这需要芯片厂商在设计之初就考虑周全。
Tessellation与Displacement Mapping
● Tessellation与Displacement Mapping综合应用
Displacement Mapping(贴图置换)与Tessellation(曲面细分)的结合使用具有许多优势。虽然两者在原理方面本来是没有任何。
贴图置换是一种通过VS和alpha混合操作来达成复杂表面的操作;基本上贴图置换不会增加新的多边形,即便增加也仅作操作点用。曲面细分则不一样,它通过在已知多边形内设立新的顶点,达成fan操作来完成增加多边形的目的。这两种技术一个的重点是alpha和顶点移动,另一个的重点则是直接增加多边形数量。这是两种完全不同的复杂表面细节实现手段。
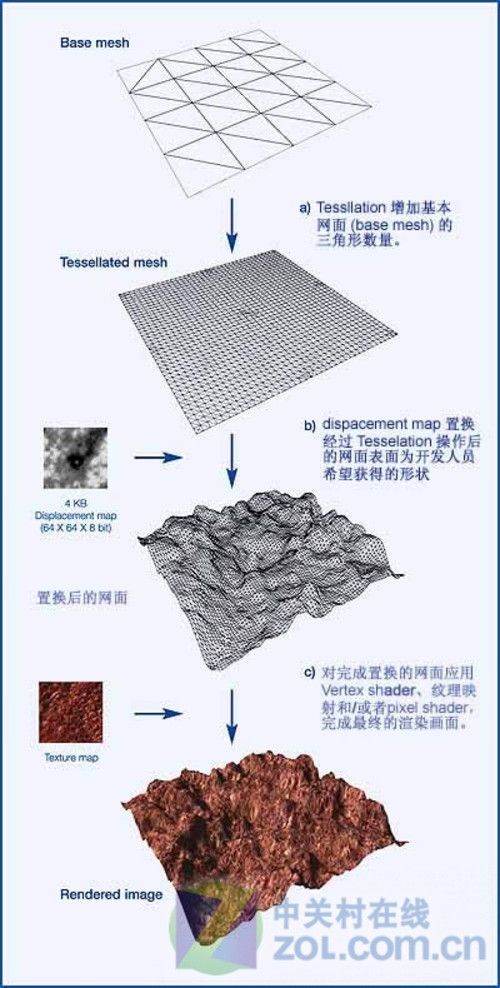
Tessellation和Displacement Mapping结合应用
简单来讲,Displacement Mapping的目的就是借助Tessellation改变多变形的外观,而不仅仅只是圆滑棱角。
正如你所看到的那样,Displacement mapping能够透过Tessellation和Displacement Mapping让一张平面的网面真正实现具有不同形状的外观(上面的例子是绵绵起伏的山丘),只要使用Displacement Mapping映像到网面的顶点上,就能够让网面善的顶点提升/升降到不同的相对高度,同样的网面可以形成不同的形状。

Tessellation和Displacement Mapping结合应用
和以往主要在光栅化阶段进行的Bump mapping不同的是,Displacement Mapping是生成的是由更多多边形构成的真实外观,而Bump mapping则是一种欺骗性手段、一种性能妥协方案而已,不能产生真正不同的外形,采用Displacement Mapping来实现丰富的表面细节实在有太多的好处了。
最终,利用Displacement Mapping(贴图置换)与Tessellation(曲面细分)相结合的方式所渲染出来的模型与艺术家所用工具中的原生模型很相似,从而让艺术家不必创建不同几何细节级别的模型,无需重复地进行这种一般性劳动。
全新的多线程渲染技术
● 全新的多线程渲染技术
虽然超线程概念已经在CPU领域发展了数十年,但大多数程序员还是直到近年来多核心CPU流行之后才开始关心程序的平行化,在此之前大部分通用代码都是简单的单线程,在这些代码里寻找并挖掘多线程化带来的性能提升是非常困难的。
为了改变这一现状,DirectX 11特性还包括很重要一点:支持多线程(multi-threading)。没错,无论是DirectX 10还是DirectX 11,所有的色彩信息最终都将被光栅化并显示在电脑显示屏上(无论是通过线性的方式还是同步的),但是DirectX 11新增了对多线程技术的支持。

从DirectX 10到DirectX 11的多线程变化
得益于此,应用程序可以同步创造有用资源或者管理状态,并从所有专用线程中发送提取命令,这样做无疑效率更高。DX11的这种多线程技术可能并不能加速绘图的子系统(特别是当我们的GPU资源受限时),但是这样却可以提升线程启动游戏的效率,并且可以利用台式CPU核心数量不断提高所带来的潜力。

多线程渲染示意图1
在DirectX 11中,微软通过将目前单一执行的Direct 3D设备被分为三个独立的接口:设备(Device)、立即执行范畴(immediate Context)和延迟执行范畴(Deferred Context)。
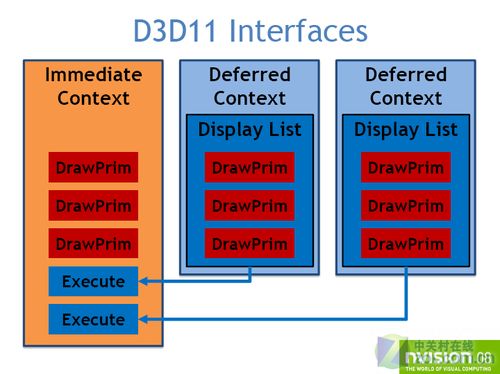
多线程渲染示意图2
这三者都被分发到各自独立的线程,而且设备和Deferred context还可以分配多个线程,负责将等待执行的任务发送给immediate Context或渲染线程。这样的设计可以将图形生成所需的资源做预先的存取。同时,CPU还可以利用显卡的多线程处理加快DirectX的处理,减少CPU的响应时间而使游戏不再受到CPU的瓶颈限制。
Compute Shader与Texture Compression
● Compute Shader与Texture Compression
GPU是图形处理器,以往的GPU通用计算需要程序员先将资料伪装成GPU可识别的图像,再将GPU输出的图像转换为想要的结果,而通过DX11中的Compute Shader通用计算,任意类型的数据(即使是非图形数据)都可以直接进行计算,而且不受图形渲染流程的束缚,可以随时写入写出,GPU通用计算的效能提高了很多。
由于GPU的浮点运算能力非常强大,支持GPU进行通用计算的技术发展势头很快,NVIDIA和AMD分别有CUDA和Stream技术,以前两家是各自为战,如今微软也看到了GPU通用计算的曙光,在DX11中加入了Compute Shader这一技术,意在统一当前的通用计算技术。你可以认为Compute Shader标准就是微软提出的OPEN CL。
Compute Shader技术是微软DirectX 11 API新加入的特性,在Compute Shader的帮助下,程序员可直接将GPU作为并行处理器加以利用,GPU将不仅具有3D渲染能力,也具有其他的运算能力,也就是我们说的GPGPU的概念和物理加速运算。多线程处理技术使游戏更好地利用系统的多个核心。
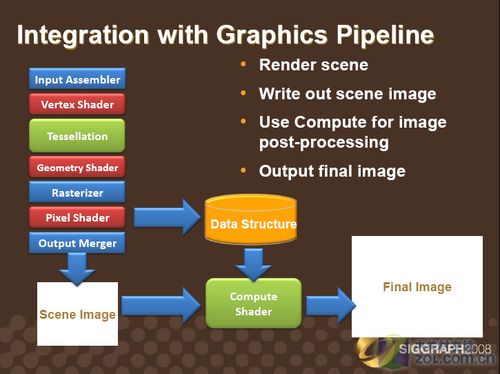
Compute Shader图形流水线
Compute Shader主要特性包括线程间数据通信、一整套随机访问和流式I/O操作基本单元等,能加快和简化图像和后期处理效果等已有技术,也为DX11级硬件的新技术做好了准备,对于游戏和应用程序开发有着很重大的意义。
在DirectX 11以及CS的帮助下,游戏开发者便可以越过复杂的数据结构,并在这些数据结构中运行更多的通用算法。与其他完整的可编程的DX10和DX11管线阶段一样,CS将会共享一套物质资源(也就是着色处理器)。
在硬件支持Compute Shader之后,相应的硬件必须要比当代硬件更加灵活,因为在运行CS代码的时候,硬件必须支持随机读写、不规则列阵(而不是简单的流体或者固定大小的2D列阵)、多重输出、可根据程序员的需要直接调用个别或多个线程、32k大小的共享寄存空间和线程组管理系统、粒数据指令集、同步建构以及可执行无序IO运算的能力。
Compute Shader可发挥的地方很多,游戏中可以使用GPU进行光线追踪、A-Buffer采样抗锯齿、物理特效、人工智能AI等游戏特效运算。在游戏之外,程序员也可以利用CS架构进行图像处理、后期处理(Post Process)等。
Texture Compression(纹理压缩)是一种和虚拟纹理类似的纹理管理方法,在很多情况下具有6倍以上压缩比例的纹理压缩都可以极其有效地减小纹理本身的大小,从而避免纹理传输和管理方面的瓶颈,并且可以获得更加精细的画面,由此看来其效率比虚拟纹理要高。
DirectX 11加入了两种新的压缩算法——BC6和BC7。其中,BC6是专门针对HDR图像设计的压缩算法,压缩比为6:1;而BC7是专门为LDR(低动态范围)图像设计的压缩算法,压缩比为3:1。

上图则是BC7针对LDR纹理的压缩与传统的BC3纹理压缩对比。可以看出传统的BC3纹理压缩损失了大量的纹理细节,压缩之后的效果也很不好。而采用BC7算法压缩后的纹理,丢失的细节很少,效果也非常好,这就是改进纹理压缩的魅力。

上图展示的是图像通过BC6压缩模式进行压缩的前后效果对比图。其中左边的图像为原始图像,中间的是在压缩过程中损失的一些细节,而右边的就是压缩后的图像。可以看出,从画质上来看几乎没有损失(肉眼看不出),但是却可以大幅度降低显存的占用。
着色器模型变化历程与总结
● 着色器模型变化历程与总结
在图形渲染中,GPU中的可编程计算单元被称为着色器(Shader),着色器的性能由DirectX中规定的Shader Model来区分。GPU中最主要的可编程单元式顶点着色器和像素着色器。
为了实现更细腻逼真的画质,GPU的体系架构从最早的固定单元流水线到可编程流水线,到DirectX 8初步具备可编程性,再到DirectX 10时代的以通用的可编程计算单元为主、图形固定单元为辅的形式,最新的DirectX 11更是明确提出通用计算API Direct Compute概念,鼓励开发人员和用户更好地将GPU作为并行处理器使用。在这一过程中,着色器的可编程性也随着架构的发展不断提高,下表给出的是每代模型的大概特点。
表:Shader Model版本演化与特点
| Shader Model |
GPU代表 |
显卡时代 |
特点 |
|
|
1999年第一代NV Geforce256 |
DirectX 7 1999~2001 |
GPU可以处理顶点的矩阵变换和进行光照计算(T&L),操作固定,功能单一,不具备可编程性 |
| SM 1.0 |
2001年第二代NV Geforce3 |
DirectX 8 |
将图形硬件流水线作为流处理器来解释,顶点部分出现可编程性,像素部分可编程性有限(访问纹理的方式和格式受限,不支持浮点) |
| SM 2.0 |
2003 年 ATI R300 和第三代NV Geforce FX |
DirectX 9.0b |
顶点和像素可编程性更通用化,像素部分支持FP16/24/32浮点,可包含上千条指令,处理纹理更加灵活:可用索引进行查找,也不再限制[0,1]范围,从而可用作任意数组(这一点对通用计算很重要) |
| SM 3.0 |
2004年 第四代NV Geforce 6 和 ATI X1000 |
DirectX 9.0c |
顶点程序可以访问纹理VTF,支持动态分支操作,像素程序开始支持分支操作(包括循环、if/else等),支持函数调用,64位浮点纹理滤波和融合,多个绘制目标 |
| SM 4.0 |
2007年 第五代NV G80和ATI R600 |
DirectX 10 2007~2009 |
统一渲染架构,支持IEEE754浮点标准,引入Geometry Shader(可批量进行几何处理),指令数从1K提升至64K,寄存器从32个增加到4096个,纹理规模从16+4个提升到128个,材质Texture格式变为硬件支持的RGBE格式,最高纹理分辨率从2048*2048提升至8192*8192 |
| SM 5.0 |
2009年 ATI RV870 和2010年NV GF100 |
DirectX 11 2009~ |
明确提出通用计算API Direct Compute概念和Open CL分庭抗衡,以更小的性能衰减支持IEEE754的64位双精度浮点标准,硬件Tessellation单元,更好地利用多线程资源加速多个GPU |
传统的分离架构中,两种着色器的比例往往是固定的。在GPU核心设计完成时,各种着色器的数量便确定下来,比如著名的“黄金比例”——顶点着色器与像素着色器的数量比例为1:3。但不同的游戏对顶点资源和像素资源的计算能力要求是不同的。如果场景中有大量的小三角形,则顶点着色器必须满负荷工作,而像素着色器则会被闲置;如果场景中有少量的大三角形,又会发生相反的情况。因此,固定比例的设计无法完全发挥GPU中所有计算单元的性能。
顶点着色单元(Vertex Shader,VS)和像素着色单元(Pixel Shader,PS)两种着色器的架构既有相同之处,又有一些不同。两者处理的都是四元组数据(顶点着色器处理用于表示坐标的w、x、y、z,但像素着色器处理用于表示颜色的a、r、g、b),顶点渲染需要比较高的计算精度;而像素渲染则可以使用较低的精度,从而可以增加在单位面积上的计算单元数量。在Shader Model 4.0之前,两种着色器的精度都在不断提高,但同期顶点着色器的精度要高于像素着色器。
Shader Model 4.0统一了两种着色器,所以顶顶点和像素着色器的规格要求完全相同,都支持32位浮点数。这是GPU发展的一个分水岭;过去只能处理顶点和只能处理像素的专门处理单元被统一之后,更加适应通用计算的需求。
DirectX 11提出的Shader Model 5.0版本继续强化了通用计算的地位,微软提出的全新API——Direct Compute将把GPU通用计算推向新的巅峰。同时Shader Model 5.0是完全针对流处理器而设定的,所有类型的着色器,如:像素、顶点、几何、计算、Hull和Domaim(位于Tessellator前后)都将从新指令集中获益。

GPU执行FFT性能将在未来迅速提升
如图,快速傅里叶变换(Fast Fourier Transform,FFT)有广泛的应用,如数字信号处理、计算大整数乘法、求解偏微分方程等等。SIGGRAPH2008峰会认为未来随着Compute Shader和新硬件、新算法的加入,GPU执行FFT操作的性能将得到快速提升。
如果使用DirectX 11中的Computer Shader技术,API将能借助GPU充裕的浮点计算能力进行加速计算,则能轻易完成大量的FFT(傅里叶变换)。在图形渲染中,这项技术的运用极大地提高了波浪生成速度,而且画面质量也更好。
以往受限于浮点运算性能,目前CPU进行FFT变换只能局限在非常小的区域内,比如64x64,高端CPU最多能达到128x128,而GTX 280则能实现每帧512x512的傅里叶变换,所用时间不过2ms,效能非常高。
性能测试的硬件、软件平台状况
性能测试的硬件、软件平台状况
● 测试系统硬件环境
性能测试使用的硬件平台由Intel Core i7-975 Extreme Edition、ASUS P6T Deluxe主板和2GB*3三通道DDR3-1600内存构成。细节及软件 环境设定见下表:
| 测 试 平 台 硬 件 | |
| 中央处理器 | Intel Core i7-975 Extreme Edition |
| (4核 / 超线程 / 133MHz*25 / 8MB共享缓存 ) | |
| 散热器 | Thermalright Ultra-120 eXtreme |
| (单个120mm*25mm风扇 / 1600RPM) | |
| 内存模组 | G.SKILL F3-12800CL9T-6GBNQ 2GB*3 |
| (SPD:1600 9-9-9-24-2T) | |
| 主板 | ASUS P6T Deluxe |
| (Intel X58 + ICH10R Chipset) | |
| 显示卡 | |
| 测 试 产 品 | |
| GeForce GTX 480 | |
| (GF100 / 1536MB / 核心:700MHz / Shader:1401MHz / 显存:3696MHz) | |
| GeForce GTX 470 | |
| (GF100 / 1280MB / 核心:607MHz / Shader:1215MHz / 显存:3348MHz) | |
| Radeon HD 5850 | |
| (RV870 / 1024MB / 核心:725MHz / Shader:725MHz / 显存:4000MHz) | |
| Radeon HD 5870 | |
| (RV870 / 1024MB / 核心:850MHz / Shader:850MHz / 显存:4800MHz) | |
| Radeon HD 5970 | |
| (RV870 / 2048MB / 核心:725MHz / Shader:725MHz / 显存:4000MHz) | |
| 硬盘 | Western Digital Caviar Blue |
| (640GB / 7200RPM / 16M缓存 / 50GB NTFS系统分区) | |
| 电源供应器 | AcBel R8 ATX-700CA-AB8FB |
| (ATX12V 2.0 / 700W) | |
| 显示器 | DELL UltraSharp 3008WFP |
| (30英寸LCD / 2560*1600分辨率) | |

G.SKILL F3-12800CL9T-6GBNQ

AcBel R8 ATX-700CA-AB8FB

Thermalright Ultra-120 eXtreme
我们的硬件评测使用的内存模组、电源供应器、CPU散热器均由COOLIFE玩家国度俱乐部提供,COOLIFE玩家国度俱乐部是华硕(ASUS)玩家国度官方店、英特尔(Intel)至尊地带旗舰店和芝奇(G.SKILL)北京旗舰店,同时也是康舒(AcBel)和利民(Thermalright)的北京总代理。
● 测试系统的软件环境
| 操 作 系 统 及 驱 动 | |
| 操作系统 | |
| Microsoft Windows 7 Ultimate RTM | |
| (中文版 / 版本号7600) | |
| 主板芯片组 驱动 |
Intel Chipset Device Software for Win7 |
| (WHQL / 版本号 9.1.1.1120) | |
| 显卡驱动 | |
| AMD Catalyst for Win7 | |
| (WHQL / 版本号 10.3) | |
| NVIDIA Forceware for GTX 400 | |
| (WHQL / 版本号 197.41) | |
| 桌面环境 |
2560*1600_32bit 60Hz |
| 测 试 平 台 软 件 | |
| 其他综合测试项目 | DX11 SDK Test:Sub D11 |
| Tessellation Factor=1 | |
| Tessellation Factor=16 | |
| Tessellation Factor=31 | |
| DX11 TechDemo:StoneGiant | |
| 1280*800 | |
| 1920*1200 | |
| DX11 SDK Test:PN Triangle | |
| Tessellation Factor=5 | |
| Tessellation Factor=19 | |
| DX11 SDK Test:Detail Tessellation | |
| Bump Mapping | |
| Parallax Occlusion Mapping | |
| Tessellation+Displacement Mapping | |
| Adaptive Tessellation+Displacement Mapping | |
| Tessellation Ultra+Displacement Mapping | |
| Adapter Tessellation Ultra+Displacement Mapping | |
| 辅助测试软件 | Fraps |
| beepa / 版本号 3.0.3 | |
各类合成测试软件和直接测速软件都用得分来衡量性能,数值越高越好,以时间计算的几款测试软件则是用时越少越好。
Tesslation测试-Stone Giant
DirectX11最为强调的图形特性就是Tessellation(曲面细分)。Tessellation技术利用GPU硬件加速,将现有3D模型的三角形拆分得更细小、更细致,也就是大大增加三角形数量,使得渲染对象的表面和边缘更平滑、更精细。
● Tesslation测试-Stone Giant
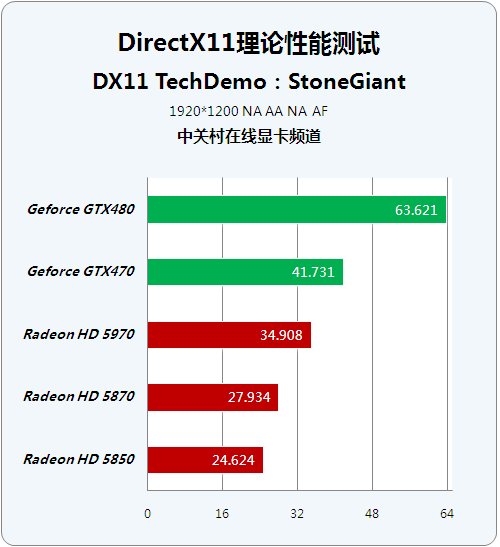
《Stone Giant》是一个针对DirectX 11 Tessellation效能十分依赖的Demo,本次笔者将用其作为检验产品Tessellation性能的工具。
以下对比图左侧为Geforce GTX480,右侧为Radeon HD 5870。
● NO Tessellation + NO Wireframe


● NO Tessellation + Wireframe


● Tessellation + NO Wireframe


● Tessellation + Wireframe



Direct X11 SDK Test:Sub D11
● Direct X11 SDK Test:Sub D11
Direct X11 SDK Test:Sub D11是集成在微软的DirectX SDK开发包中的测试组件之一,它主要测试GPU的Tessellation性能。这个测试一共包含31个层级,从第一级的轻度曲面细分到31级重度曲目细分,对显卡的几何处理能力考验不断升级。
我们为了对NVIDIA和AMD公平起见,选择了Factor=1/16/31,这三个级别的测试曲面数量很有可能在未来作为图形开发者的重要参考标准。




我们能够看到一个很明显的性能变化,在曲面细分压力不大的情况下,HD5870有接近于Fermi架构GTX480的表现,HD5970则能够超越GTX480。而在曲面细分压力变大之后,A卡出现了非常严重的性能下降,毕竟R800架构的一个曲面细分单元无法对抗NVIDIA在Fermi架构中给每个SM单元分配一个曲面细分单元。
DX11 SDK Test:PN Triangle
● DX11 SDK Test:PN Triangle
PN Triangle和上一个Sub D11测试有异曲同工之处,它们都着重测试GPU的曲面细分性能。这个SDK测试程序是在微软发布DirectX 11初期由AMD提供的。

因为它同样也有曲面层级设置,所以我们选取了负载较轻的5和负载较重的19进行测试。结果如下:


PN Triangle的测试结果和Sub D11非常相似,毕竟两者的测试目的相同。但是我们需要清楚知道的一点是我们所作的都是理论性能测试,而且是有很强侧重性的。
在图形运算中不可能有完全纯净的Tessellation环境和极大的Tessellation负载。所以我们不可能看到在DirectX 11游戏中出现A卡因为开启了DirectX 11支持的Tessellation功能之后性能大幅度下降。
Detail Tessellation(1)
● DX11 SDK Test:Detail Tessellation (1)
Detail Tessellation是集成在DirectX 11 SDK开发包中的重要基准测试程序,它提供了Bump Mapping、Parallax Occlusion Mapping和Tessellation三种主渲染模式,同时使用者可以在这3种模式之上添加其他附加效果,以达到较为复杂的Shader效果。

这个测试中只要涉及置换位移贴图和传统的凹凸类贴图,都会有大量的VS指令,而VS指令天生就是4D指令,因此R800的4D+1D组织SIMD结构流处理器会表现出较强的性能。而NVIDIA显卡的主要看点则在曲面细分性能上。越复杂的Shader效果对着色器性能要求越高。
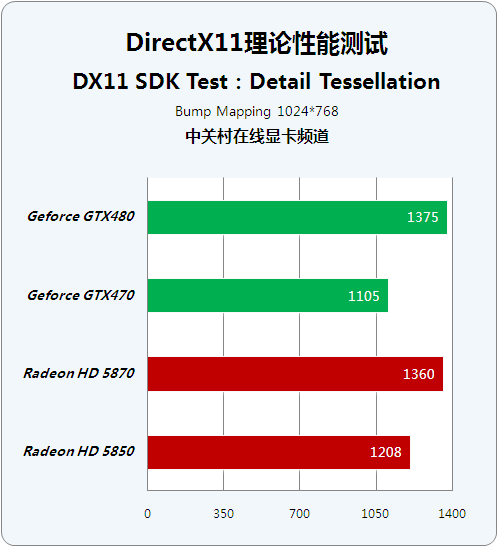


Detail Tessellation(2)
● DX11 SDK Test:Detail Tessellation (2)
Detail Tessellation是集成在DirectX 11 SDK开发包中的重要基准测试程序,它提供了Bump Mapping、Parallax Occlusion Mapping和Tessellation三种主渲染模式,同时使用者可以在这3种模式之上添加其他附加效果,以达到较为复杂的Shader效果。
Adaptive Tessellation技术一样会通过调节VS来细化曲面结构,跟单纯的设置顶点碎多边形的Tessellation技术来说不一样。我们发现这方面AMD显卡表现较为优秀,比起单纯的Tessellation技术来说性能衰减要小很多。
而Tessellation Ultra对曲面细分单元较为缺乏的A卡来说,性能下降非常迅速,毕竟Fermi架构的GF100完整版拥有16个曲面细分单元,而AMD的R800架构只是在UTDP指令分配器中装配了一个曲面细分单元以达到微软DirectX 11的硬件要求,所以性能较弱理所应当。

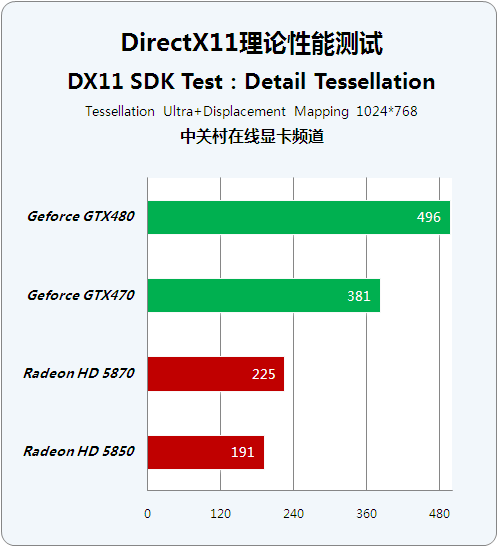

鉴于这项测试对单卡双芯HD5970显卡没有提供良好支持,我们在Detail Tessellation测试中忽略了这款显卡的成绩。我们可以从测试中看到,在Shader效果较为简单的前几项测试中,AMD和NVIDAI的最新架构显卡并没有太大分别,而在越来越复杂的Shader效果中,全新设计的Fermi架构显卡体现出了比较强劲的运算能力。
在4月下旬,中关村在线显卡频道已经对DirectX 11现有的大部分游戏进行了横向评测,而今天这篇文章的目的,就是让大家更加深入地了解DirectX 11这套全新的API将如何从图形图像的渲染方面改变我们的“视界”。
目前Fermi架构的Geforce GTX400系列显卡刚上市不久,整个DirectX 11周边配合程序还没有完善,用户方便执行的、可用于单项性能测试的也只有屈指可数的Techdemo和SDK开发包内的程序,而且它们的测试方向几乎都指向了Tessellation技术。相信在未来的一段时间内,我们可以运用更好的软件来了解DirectX 11显卡的各项技术特性。
本文参考文献:
[1] 全新绘图时代DirectX 11 GPU架构深度解析
[2] 图像的革新 Win7 DirectX 11技术全解析
[3] DirectX 11核心技术Tessellation浅析
[4] 开创DX11宏图霸业 镭HD5870权威评测
[5] Matrox絕地大反擊 幻日Parhelia-512
[6] 全新API呼之欲出 DirectX 11动力深析
[7] 细分模式构造及拟合
原文地址:http://vga.zol.com.cn/176/1769287_all.html