ICCV2019《TSM: Temporal Shift Module for Efficient Video Understanding》编译记录
ICCV2019《TSM: Temporal Shift Module for Efficient Video Understanding》食用指南
0
最近在研究行为识别方面,发现ICCV2019的这篇文章写的非常好,正好对研究非常有帮助,于是想先编译一下文章提供的代码,编译过程中也遇到了很多坑,记录下来。
首先,贴上这篇文章的链接 文章
code:代码
1
我是在服务器跑的,我的环境是:Ubuntu16.04.3 python3.5。可以用下面指令来download整个项目。
git clone git://github.com/mit-han-lab/temporal-shift-module.git首先是安装项目需要用到的库,这里也遇到了一些关于服务器的坑,比如有些指令要加sudo,不然没有管理员权限,而且因为linux中python默认的是2.7版本的,我用的是py3.5,用pip安装时要用pip3。
先是安装pytorch
可以在pytorch官网 https://pytorch.org/ 上下载,首先要看CUDA的版本,如果不知道电脑有没有安装CUDA以及CUDA的版本,可以输入以下指令来查看:
nvidia-smi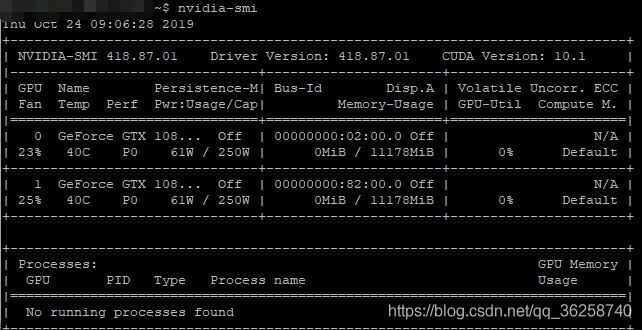
可以看到CUDA版本是10.1,其实我装的是cuda10.0,系统会自动升级到最新版本,可以参照网上教程安装10.0,比较推荐10.0版本。要安装cuda可能还要安装显卡驱动,根据自己的显卡安装合适的驱动版本。
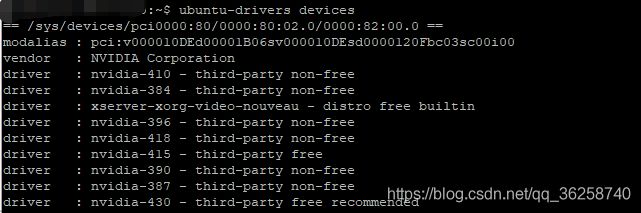
输入指令查看推荐的版本,我安装了418版本。
然后根据CUDA和python的版本来安装对应的pytorch,可以在官网上下载以前的版本,我下载的是torch1.2版本
下载地址
然后就是安装项目所需要的库,第一个已经安装好了,下面就安装另外两个,github上给出了这两个链接,我就不重复了。
2
搭好环境之后就要下载模型文件和数据集了,github给出的下载链接可能打不开,估计得科学上网()。可以把github上那几个kinetics的pth文件下载下来,后面会用到。
我看了一下作者用的kinetics-400数据集,都是来自于youtube上的视频,大概130个g,网上下载不下来,去闲鱼搞了一份百度云的,下载的太慢,用云盘下载过了10个还是20个g就限速了,于是放弃了,直接用自己的数据集开始跑。
首先在项目中新建一个data目录,把视频文件按类全部放进去,我目前只有三类动作,于是就分成了1 2 3文件夹。再在data目录下新建frames文件,用于存放抽取的帧。
python3 tools/vid2ing_kinetics.py data/pingpang data/frames 2后面那个2意思是我用了2个gpu。
然后写训练集和验证集的csv文件,train.csv和val.csv,我的格式是这样的

分别是类名,视频名称,split。同样格式安排好train.csv。
修改tools目录下的gen_label_kinetics.py文件,主要是修改标签和数据集地址还有类的数目。

这个py文件会生成val_videofolder.txt和train_videofolder.txt。然后将这些都添加到ops/dataset_config.py中去。如果用的不是作者用到的那几个数据集,还得在dataset_config.py文件中定义自己的数据集,参照另外几个数据集定义写一下,比如我自己的数据集

还要在下面的函数中添加自己的数据集名称。
![]()
写的可能不是太详细,有的细节修改可能忽略了。到此,训练前的准备工作就大致完成了。
3
开始训练模型啦,
python3 main.py pingpang RGB \
--arch resnet50 --num_segments 8 \
--gd 20 --lr 0.02 --wd 1e-4 --lr_steps 20 40 --epochs 50 \
--batch-size 64 -j 16 --dropout 0.5 --consensus_type=avg --eval-freq=1 \
--shift --shift_div=8 --shift_place=blockres --npb如果报错cuda out of memory,这不是说程序有问题,把指令中的batch-size改小就行。
我在跑成功前还遇到这样一个错误:
RuntimeError:invalid argument 5:k not in range for dimension at /pytorch/ate ...意思是5这个参数是无效的,我一开始认为是我数据集的问题,应该不是图片通道的问题,因为我用的都是三通道的,应该是图片尺寸不统一,就想着把它们都改成同样大小。在我改着的时候我突然意识到是topk出错了,训练返回top1和top5精度,我这数据集只分三类,根本没有top5,于是我把5都改成了3。终于开始跑了。
我的数据集不大,跑了大概20来分钟,跑出来的top1精度只有65.169,然后用Kinetics预训练模型对数据集进行微调,精度提升到了91.011
python3 main.py pingpang RGB \
--arch resnet50 --num_segments 8 \
--gd 20 --lr 0.001 --lr_steps 10 20 --epochs 25 \
--batch-size 64 -j 16 --dropout 0.8 --consensus_type=avg --eval-freq=1 \
--shift --shift_div=8 --shift_place=blockres \
--tune_from=pretrained/TSM_kinetics_RGB_resnet50_shift8_blockres_avg_segment8_e50.pth使用test_models.py测试了一下,精度一样。