pytorch学习笔记——网络架构四调整与数据再增强(10)
训练集和测试集准确率纠缠不清,准确有没有再提升的可能?一种可能的情况就是过拟合了。基于之前训练准确率与测试集准确率十分接近的情况,我们再次增加网络的规模,同时使用对比度变换的数据增强方案,看看是不是有可能使准确率进一步提升。改变后的网络架构如下:
SimpleNet(
(conv1): Sequential(
(0): Conv2d(1, 8, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): BatchNorm2d(8, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
(3): Conv2d(8, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(4): BatchNorm2d(16, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU()
(6): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(conv2): Sequential(
(0): Conv2d(16, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
(3): Conv2d(32, 48, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(4): BatchNorm2d(48, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU()
(6): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(fc): Sequential(
(0): Linear(in_features=192, out_features=192, bias=True)
(1): Dropout(p=0.5, inplace=False)
(2): Linear(in_features=192, out_features=128, bias=True)
(3): Dropout(p=0.5, inplace=False)
(4): Linear(in_features=128, out_features=10, bias=True)
)
)>
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Conv2d-1 [-1, 8, 8, 8] 80
BatchNorm2d-2 [-1, 8, 8, 8] 16
ReLU-3 [-1, 8, 8, 8] 0
Conv2d-4 [-1, 16, 8, 8] 1,168
BatchNorm2d-5 [-1, 16, 8, 8] 32
ReLU-6 [-1, 16, 8, 8] 0
MaxPool2d-7 [-1, 16, 4, 4] 0
Conv2d-8 [-1, 32, 4, 4] 4,640
BatchNorm2d-9 [-1, 32, 4, 4] 64
ReLU-10 [-1, 32, 4, 4] 0
Conv2d-11 [-1, 48, 4, 4] 13,872
BatchNorm2d-12 [-1, 48, 4, 4] 96
ReLU-13 [-1, 48, 4, 4] 0
MaxPool2d-14 [-1, 48, 2, 2] 0
Linear-15 [-1, 192] 37,056
Dropout-16 [-1, 192] 0
Linear-17 [-1, 128] 24,704
Dropout-18 [-1, 128] 0
Linear-19 [-1, 10] 1,290
================================================================
Total params: 83,018
Trainable params: 83,018
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.00
Forward/backward pass size (MB): 0.07
Params size (MB): 0.32
Estimated Total Size (MB): 0.39
----------------------------------------------------------------
得出的结果如下:
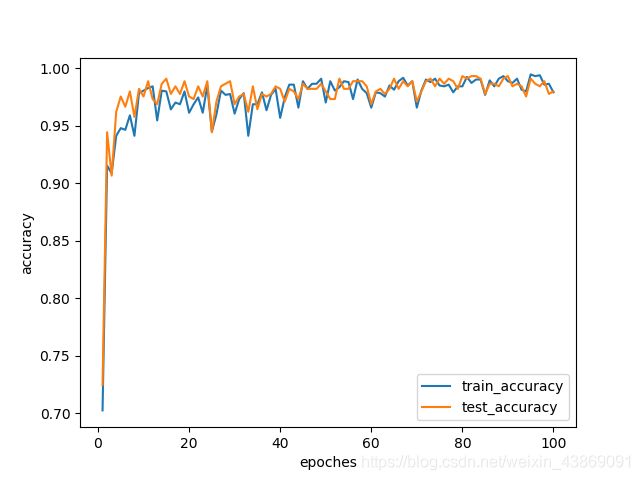
作用相当于挠痒痒。删去对比度增强,试训练一下再试试:
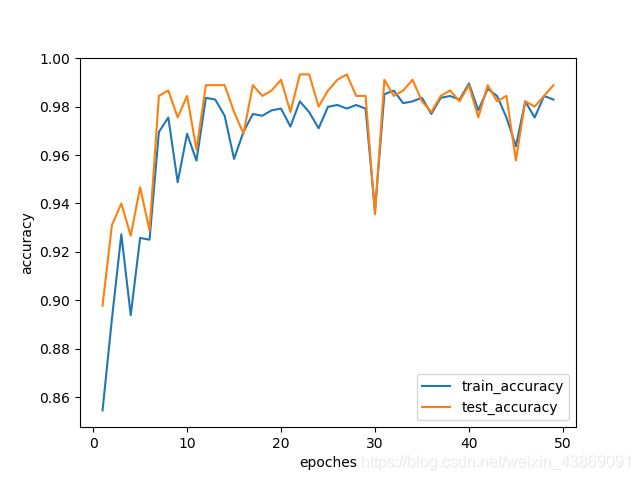
害,结果还不如之前的架构呢。具体原因我还得仔细想想。