深度学习基础系列:VGG
深度学习基础系列:VGG
Visual Geometry Group是牛津大学的一个科研团队。他们推出的一系列深度模型,被称作VGG模型。
论文名:《Very Deep Convolutional Networks for Large-Scale Visual Recognition》
VGG模型是2014年ILSVRC竞赛的第二名,第一名是GoogLeNet。但是VGG模型在多个迁移学习任务中的表现要优于googLeNet。而且,从图像中提取CNN特征,VGG模型是首选算法。它的缺点在于,参数量有140M之多,需要更大的存储空间。但是这个模型很有研究价值。
VGG的结构图如下:

该系列包括A/A-LRN/B/C/D/E等6个不同的型号。其中的D/E,根据其神经网络的层数,也被称为VGG16/VGG19。
从原理角度,VGG相比AlexNet并没有太多的改进。其最主要的意义就是实践了“神经网络越深越好”的理念。也是自那时起,神经网络逐渐有了“深度学习”这个别名。
VGG-16的网络结构如下图所示:
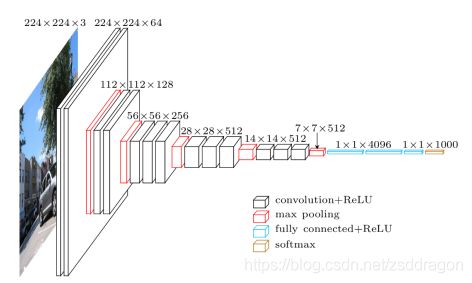
VGG-16的结构非常整洁,深度较AlexNet深得多,里面包含多个conv->conv->max_pool这类的结构,VGG的卷积层都是same的卷积,即卷积过后的输出图像的尺寸与输入是一致的,它的下采样完全是由max pooling来实现。
VGG网络后接3个全连接层,filter的个数(卷积后的输出通道数)从64开始,然后没接一个pooling后其成倍的增加,128、512,VGG的注意贡献是使用小尺寸的filter,及有规则的卷积-池化操作。
VGG特点:
1.小卷积核。作者将卷积核全部替换为3x3(极少用了1x1);
2.小池化核。相比AlexNet的3x3的池化核,VGG全部为2x2的池化核;
3.层数更深特征图更宽。基于前两点外,由于卷积核专注于扩大通道数、池化专注于缩小宽和高,使得模型架构上更深更宽的同时,计算量的增加放缓;
与AlexNet相比,可以看出VGG-Nets的卷积核尺寸还是很小的,比如AlexNet第一层的卷积层用到的卷积核尺寸就是11*11,这是一个很大卷积核了。而反观VGG-Nets,用到的卷积核的尺寸无非都是1×1和3×3的小卷积核,用来替代大的filter尺寸。
3×3卷积核的优点:
多个3×3的卷基层比一个大尺寸filter卷基层有更多的非线性,使得判决函数更加具有判决性
多个3×3的卷积层比一个大尺寸的filter有更少的参数,假设卷基层的输入和输出的特征图大小相同为C,那么三个3×3的卷积层参数个数3×(3×3×C×C)=27CC;一个7×7的卷积层参数为49CC;所以可以把三个3×3的filter看成是一个7×7filter的分解(中间层有非线性的分解)
VGG-16的Keras实现:
def VGG_16():
model = Sequential()
model.add(Conv2D(64,(3,3),strides=(1,1),input_shape=(224,224,3),padding='same',activation='relu',kernel_initializer='uniform'))
model.add(Conv2D(64,(3,3),strides=(1,1),padding='same',activation='relu',kernel_initializer='uniform'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Conv2D(128,(3,2),strides=(1,1),padding='same',activation='relu',kernel_initializer='uniform'))
model.add(Conv2D(128,(3,3),strides=(1,1),padding='same',activation='relu',kernel_initializer='uniform'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Conv2D(256,(3,3),strides=(1,1),padding='same',activation='relu',kernel_initializer='uniform'))
model.add(Conv2D(256,(3,3),strides=(1,1),padding='same',activation='relu',kernel_initializer='uniform'))
model.add(Conv2D(256,(3,3),strides=(1,1),padding='same',activation='relu',kernel_initializer='uniform'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Conv2D(512,(3,3),strides=(1,1),padding='same',activation='relu',kernel_initializer='uniform'))
model.add(Conv2D(512,(3,3),strides=(1,1),padding='same',activation='relu',kernel_initializer='uniform'))
model.add(Conv2D(512,(3,3),strides=(1,1),padding='same',activation='relu',kernel_initializer='uniform'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Conv2D(512,(3,3),strides=(1,1),padding='same',activation='relu',kernel_initializer='uniform'))
model.add(Conv2D(512,(3,3),strides=(1,1),padding='same',activation='relu',kernel_initializer='uniform'))
model.add(Conv2D(512,(3,3),strides=(1,1),padding='same',activation='relu',kernel_initializer='uniform'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Flatten())
model.add(Dense(4096,activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(4096,activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(1000,activation='softmax'))
return model
使用上述模型训练猫狗分类,5000张猫图片,5000张狗图片,batch_size=8,epochs=50
训练了30分钟左右,大概已经训练了10几个epochs,accuracy 大概0.5,几乎没变,loss到是在变小
停止训练,分析原因:
个人觉得原因大概是VGG参数较多,这个从模型大小也可以看出,VGG权重模型比Inception,Resnet权重模型大很多,要训练成功估计需要更多的数据,需要增加数据。
方法一:这个实验没有使用数据增强,数据是先加载到内存,增加数据需要增加内存,浪费钱,不试了
方法二:使用数据增强,增加数据量,增加训练epochs,因为个人电脑,资源有限,batch_size不可能设很大,训练太浪费时间,不试了
结论:VGG常用于CNN特征提取,但是很少从头开始训练模型,不是没有道理,从头训练太麻烦了,建议采用迁移学习的方式
VGG的正确使用方式:
参考代码github连接:https://github.com/Sdamu/Keras_pratice 中的dogs_vs_cats_vgg16.py