考研数据库复习(一) 过一遍教材
1、绪论:
基本的概念
- 数据库DB
- 数据库管理系统DBMS:基础软件
- 数据管理员DBA
- 数据库系统DBS:DB+DBMS+DBA
- 数据库发展的三个阶段:人工管理阶段、文件系统阶段、数据库系统阶段
- 数据独立性:物理独立性(用户程序和DBMS独立)和逻辑独立性
- 数据库模型是数据库系统的核心和基础
- 按照不同的层次,模型分为概念模型、逻辑模型和物理模型
概念模型:
- 实体、属性
- 码:唯一标识实体的属性集称为码
- 实体型:用实体名及其属性名集合来抽象和刻画同类实体,称为实体型
- 表示方法:实体-联系方法 E-R方法也称为E-R模型
数据模型=数据结构+数据操作+完整性约束条件
常用的数据模型:
层次模型+网状模型+关系模型+面向对象数据模型+对象关系数据模型+半结构化数据模型
数据库系统的三级模式:外模式、模式、内模式
外模式/模式映像:逻辑独立性
模式/内模式印像:物理独立性
2、关系数据库
2.1关系数据结构及形式化定义
R(D1,D2,...,DN) n是母,R是关系名
- 候选码中选定主码
- 候选码的诸属性称为主属性
- 非主属性、非码属性
基本操作:
选择(Select)、投影(project)、连接(join)、、并(union)、差(except)、笛卡尔积
要记住各自的标号
基本术语:
结构化查询语句SQL
数据控制语言DCL
完整性约束:
实体完整性、参照完整性、用户定义完整性
运算
传统的集合运算是三目运算,包括并、差、交、笛卡尔积书本P50
专门的关系运算符:选择、投影、连接、除运算
连接:
等值连接、非等值连接、自然连接
自然连接
- 是一种特殊的等值连接:
- 两个都是同名属性组。去重
- 自然连接被舍弃的元组称为悬浮元组
若想保留悬浮元组则引入外连接
左外连接、右外连接(注意书写)
3、SQL
数据定义:
1、模式的定义与删除
- 定义模式:
并在其中顶一个一个table表
- CREATE SCHEMA TEST AUTHORIZATION ZHANG
- CREATE TABLE TAB1(COL1 SMALLINT,
- COL2 INT,
- COL3 CHAR(20),
- )
- 删除模式
级联:CASCADE(级联)
限制:RESTRICT(限制)
DROP SCHEMA ZHANG CASCADE
数据表的定义和删除
2、表的定义、删除与修改:
1、定义一个学生表
外键:
- CREATE TABLE student(
- Sno CHAR(9) PRIMARY KEY,
- Sname CHAR(20) UNIQUE,
- Ssex INT,
- Sage INT,
- Sdept CHAR(20)
- );
- CREATE TABLE course(
- Cno CHAR(4) PRIMARY KEY,
- Cname CHAR(40) NOT NULL,
- Cpno CHAR(4),
- Ceredit SMALLINT,
- FOEIGN KEY (Cpno) REFERENCES Course(Cno)
- )
- CREATE TABLE SC
- (Sno CHAR(9),
- Cno CHAR(4),
- Grade SMALLINT,
- PRIMARY KEY(Sno,Cno) ,
- FOREIGN KEY(Sno) REFERENCES Student(Sno),
- FOREIGN KEY(Cno) REFERENCES Course(Cno)
- );
2、修改表
- 向student表增加“入学时间”
ALTER TABLE student ADD S_entrance DATE;
- 将年龄的数据由字符串改为整数
ALTER TABLE student ALTER COLUNM Sage INT;
- 增加课程名称必须取唯一的约束条件
ALTER TABLE course ADD UNIQUE(Cname);
- 删除表:
DROP TABLE student CASCADE;
索引
- 建立索引:
CREATE UNIQUE INDEX Stusno ON student(SNO)
建立SC表按学号升序和按课程号降序建唯一索引
CREATE UNIQUE INDEX scno ON sc(Sno ASC,Cno DESC)
- 修改索引
将SC表的SCno 索引名改为SCSno
ALTER INDEX SCno RENAME TO SCSno;
- 删除索引
DROP INDEX Stusname;
数据查询
- 查询经过计算的值且为其重新命名
SELECT Sname,2014-Sage Brithday FROM student;
- 选择表中的若干元素组
- 去重(DISTINCT)
SELECT DISTINCT Sno FROM SC;
-
- 确定范围(BETWEEN AND)
- SELECT Sname,Sdept,Sage
- FROM Student
- WHERE Sage BETWEEN 20 AND 23;
- 确定集合
查询CS、MA、IS学生的姓名和性别
- SELECT Sname,Ssex
- FROM Student
- WHERE Sdept IN(‘CS’,’MA’,’IS’);
- 字符匹配
- 查询所有姓刘的学生的姓名、学号和性别
- SELECT Sname,Sno,Ssex
- FROM Student
- WHERE Sname LIKE ‘刘%’;
- 查询姓“欧阳”且全名为是三个汉字的学生姓名
- SELECT Sname
- FROM Student
- WHERE Sname like’欧阳_’;
- 查询名字中第二字字为“阳”的学生的姓名和学号
- SELECT Sname,Sno
- FROM student
- WHERE Sname like ‘_阳%’;
- 查询DB_Design课程的课程号和学分
- SELECT Cno,Ccredit
- FROM Course
- WHERE Cname like ‘DE\_Design’ ESCAPE ‘\’;
- 查询以DB_开头,且倒数第三个字符为i的课程的详细情况
- SELECT *
- FROM Course
- WHERE Cname like ‘DE\_%i_ _’ ESCAPE ‘\’;
- 聚集函数(COUNT() SUM() AVG() MAX() MIN())
- 查询选修了课程的人数
- SELECT COUNT(DISTINCT Cno)
- FROM Course;
- 计算选修一号课程的学生平均成绩
- SELECT AVG(Grade)
- FROM SC
- WHERE Cno=’1’;
- 查询选修一号课程的学生最高分数
- SELECT MAX(Grade)
- FROM SC
- WHERE Cno=’1’;
- 查询学生201215012选修课程的总学分数
- SELECT SUM(Ceredit)
- FROM SC,Course
- WHERE Sno=’201215012’ AND SC.Cno=Course.Cno;
注意:WHERE子句中是不能用聚集函数作为条件表达式,聚集函数只能用在SELECT子句
和GROUP BY 中的HAVING 子句
- ORDER BY
- 求各个课程号所对应的人数
- SELECT Cno COUNT(Sno)
- FROM SC
- GROUP BY Cno;
- 选修了三门课程以上的学生学号
- SELECT Sno
- FROM SC
- GROUP BY Sno
- HAVING COUNT(*)>3
- 查询平均成绩大于90
- SELECT Sno,AVG(Grade)
- FROM SC
- GROUP BY Sno
- HAVING AVG(GRADE)>=90;
2、连接查询
自然连接
查询选修2号课程且成绩在90分以上的所有学生的学号和姓名
- 1.SELECT Student Sno,Sname
- 2.FROM Student,SC
- 3.WHERE Student.Sno= SC.Sno AND
- 4.SC.Cno=’2’ AND SC.Grade>90;
自身连接
查询一门先修课的先修课
外连接:
- SELECT FIRST.Cno,SECOND.Cpno
- FROM Course FIRST,Course SECOND
- WHERE FIRST.Cpno=SECOND.Cno;
左外连接:
- SELECT *
- FROM Student LEFT OUTER JOIN SC ON (Student.Sno=SC.Sno);
3、嵌套查询
带有in的子查询
不相关子查询
查询与刘晨在同一个系学习的学生
- SELECT Sno,Sname,Sdept
- FROM Student
- WHERE Sdept IN
- (SELECT Sdept
- FROM Student
- WHERE Sname=’刘晨’);
方法二:
- SELECT S1.Sno,S1.Sname,S1.Sdept
- FROM Student S1,Student S2
- WHERE S1.Sdept=S2.Sdept AND S2.Sname=’刘晨’;
相关子查询
找出每个学生超过他自己选修课程平均成绩的课程号
- SELECT Sno,Cno
- FROM SC x
- WHERE GRADE>=(SELECT AVG(Grade)
- FORM SC y
- WHERE y.Sno=x.Sno);
3.4.数据更新
1、插入:
插入一条数据
- INSERT INTO Student(Sno,Sname,Ssex,Sdept,Sage)
- VALUES(‘201215128’,’陈东’,’男’,’IS’,18);
插入子查询结果:
- INSERT INTO
- Dept_age(Sdept,Avg_age)
- SELECT Sdept,AVG(Sage)
- FROM Student
- GROUP BY Sdept;
2、修改:
修改某一个元组的值
- UPDATE Student
- SET Sage=22
- WHERE Sno=’201212293’;
修改多个元组的值
UPDATE Student SET Sage=Sage+1
带自查询的修改语句
- UPDATE SC
- SET Grade=0
- WHERE Sno IN
- (SELECT Sno
- FROM Student
- WHERE Sdept=’CS’);
3、删除
删除某一个元组的值
- DELECT
- FROM Student
- WHERE Sno=’20019929’
删除多个元组的值
- DELECT
- FROM SC;
带子查询的删除语句
- DELECT
- FROM SC
- WHERE Sno IN
- (SELECT Sno
- FROM Student
- WHERE Sdept=’CS’);
3.5视图创建
1、建立信息系学生的视图
- CREATE VIEW IS_Student
- AS
- SELECT Sno,Sname,Sage
- FROM Student
- WHERE Sdept=’IS’;
- 删除视图
DROP VIEW IS_Student;
- 查询视图
- SELECT IS_Student.Sno,Sname
- FROM IS_Student,SC
- WHERE IS_Student.Sno=SC.Sno AND SC.Cno=’1’;
- 更新
- UPDAET IS_Student
- SET Sname=’刘晨’
- WHERE Snn=’20199299’
第四章数据库安全性:
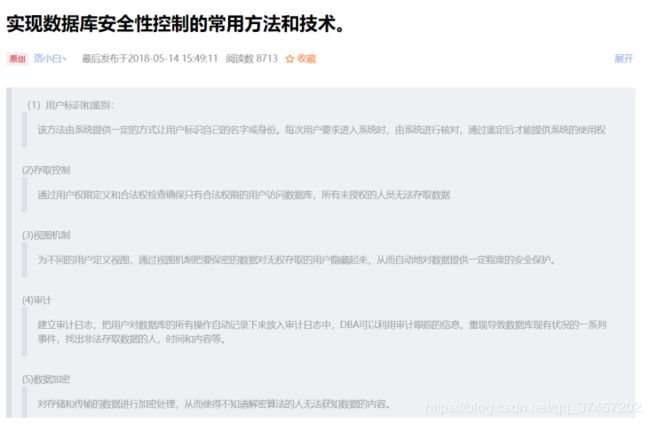
第五章数据库完整性约束
其中参照完整性和实体完整性会结合创建表的时候去考
第六章:
函数依赖:X->Y
完全函数依赖、部分函数依赖
码:
超码
外码:
比如在SC(Sno,Cno,Grade)中,Sno不是码,但Sno是S(Sno,Sdept,Sage)的码,则称X是R的外部码
1NF:每个分量必须是不可分的数据项
2NF:非主属性码完全函数依赖于任何一个候选码,不存在部分依赖
3NF:满足二的前提下不存在传递依赖
BCNF:每一个决定因素中都存在码

难点在于
闭包的理解
第七章!
笔试题! E-R图必须会读题意和画图
第八章 并发控制
并发控制
事务的执行方式:事务串行、交叉并发、同时并发
数据的不一致性:丢失修改(自己改,别人也改,然后自己改的没了)、不可重复读(自己在读,别人在写,读取错误)、读脏数据(自己在写,别人在读时,然后自己又把写的撤销了,造成别人读脏数据)
封锁是实现并发控制的一个非常重要的技术
排他X锁又称为写锁,共享S锁读锁
加锁规则:
按照何时申请X,S:
一级协议:加X锁,直至事务结束 ----防止丢失修改
二级协议:一的前提当读数据时上S锁,读完释放 -----+读脏数据
三级协议:一的前提当读数据时上S锁,直至事务结束才释放 ----+不可重复度
按照释持锁时间:
二段锁协议
并发调度的可串行性:
并发事务正确调度的准则:可串行性
冲突可串行化:一个调度Sc在保证冲突操作的次序不变的情况下,交换事务得到串行的,则~
要会判断!!
若一个调度是冲突可串行化,则一定是可串行化的调度
简答:
1、什么是封锁粒度:
封锁对象的大小。
多粒度封锁
多粒度封锁协议:对一个节点加锁意味着这个节点所有后裔都被加同样锁。
有显示封锁、隐式封锁
因检查效率低,引入意向锁
如果意向锁则表明该节点的下一层节点正在被加锁
常见的三种:意向共享锁IS 意向排它锁IX 共享意向排它锁SIX
注意:
SIX:SIX=S+IX; 数据所的相容矩阵通过所得强度偏序关系就可以记住
2、数据库中死锁产生的原因和解决死锁的方法
原因:封锁可以引起死锁,相互等待~~~
方法:一次封锁法、顺序封锁法
诊断的方法:
超时法
等待图法
2、基本的封锁类型有几种,试叙述他们的含义:
答:基本的分所类型有排它锁(“X”锁)和共享锁(“S”锁)两种。
若事务T对数据A加上X锁,则只允许事务T读取和修改数据A.
若事务T对数据A加上S锁,则其他事务可以进行+S锁但不能加X
3、什么是活锁?
如果T1、T2、T3、T4轮流请求个封锁数据R,T1释放后系统首先批准T3请求,T2DENGDAI
T2有可能永远等地。后锁的含义是等待事务等待的时间太长,似乎被锁住了,实际上可能被激活
决策:先来先服务
4、请简述两段锁协议的内容:
事务分为两个阶段,第一个阶段是获得封锁,也成为扩展阶段(只获得不释放);第二阶段是释放封锁,也称为收缩阶段(只释放不获得)