数据库原理及应用 数据模型(一)
Hierarchical Data Model(层次模型)
Basic idea:because many things in real world are organised in hierarchy,hierarchical model manages to describe real world in a tree structure.
层次数据模型的基本思想来源于人们发现现实世界中有很多数据本身就是有层次的,比如霍格沃茨下面分了格兰芬多、赫奇帕奇、拉文克劳和斯莱特林,而每个院下面又有不同的老师等等。我们就想能不能用树来表示这种层次关系。
■Record and field
我们把现实世界里各种各样的实体在层次模型中用记录来表示,每个记录由若干个域组成。
■Parent-Child relationship(PCR):the most baisc data relationship in hierarchical model.It expresses a 1:N relationship between two record types.
现实世界中有各种各样的实体,多个相同类型的实体就形成了实体类型,比如一个学生是一个实体,而学生这个群体则就形成了一种实体类型。如果两种实体类型之间存在一对多的关系,我们用双亲子女关系即PCR来描述这种关系。

上图中左边的就是一种PCR类型,系是一种记录类型,班级是一种记录类型,这两种类型之间存在一对多的关系:一个系下面有很多班。这是型的定义。而右边这是值:具体到了计算机系下面有901、902 、903、 904四个班。
Hierarchical Data Schema
■A hierarchical data schema consists of PCRs.
■Every PCR expresses one 1:N relatioship
■Every record type can only have one parent
右边的schema由四个PCR关系组成,右边是型,左边是值。
Virtual Record
■In real world,many data are not hierarchical.It is hard to express them directly with PCR.
►M:N relationships between different record types
►A record type is the child of more than two PCRs.
►N-ary relationship
一个PCR可以表示一个一对多关系,但是现实世界中还有多对多关系,像课程和学生,一门课可以有多个学生选,一个学生也可以选多门课。除此之外,还可能PCR里面一个记录类型有多个双亲,比班级和学生之间有一对多的关系,运动队和学生之间也有一对多的关系。再有,我们刚刚说的都是两种记录类型之间的关系,但实际生活中还存在更复杂的,比如供应商给某个工程供应某种零件,这就涉及到了三种记录类型。
■To avoid redundant,virtual record is introduced to express above relationships.It is a pointer in fact.(虚记录就是一个指针)
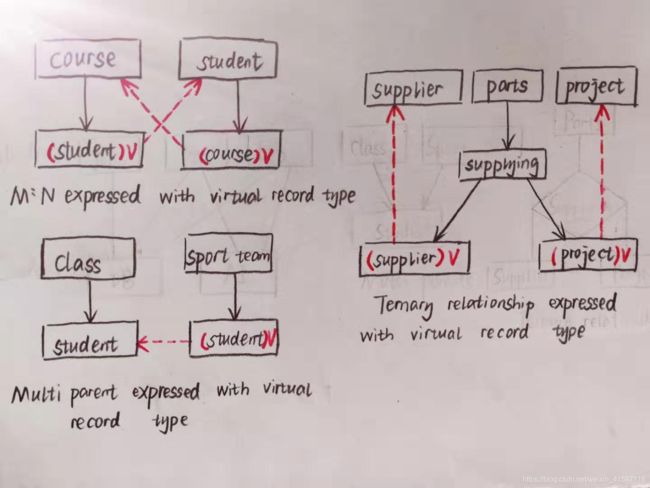
为了避免冗余,同时保持PCR关系的树型结构,引入了虚记录类型。以我们上面说的课程和学生的多对多关系为例,引入学生和课程的虚记录类型。课程和学生之间建立一个PCR关系,表示一门课程可以有多个学生选择,只不过这里的孩子节点学生类型是虚记录,并不真正存储数据,而是存储了一个指针,指向真正的学生类型。类似的,建立学生和课程之间的PCR关系,表示一个学生可以选多门课程,这里的课程是虚记录,存储一个指向真正课程的指针。看上图,如果从PCR角度来看,只看黑色的箭头,树型结构得到了保持。
类似地,对于有些记录类型可能有多个双亲的情况,也是引入虚记录解决。在上面的例子中,学生有运动队和课程两个双亲,我们对课程和学生定义一个PCR,对运动队和学生定义一个PCR,只不过运动队的孩子节点是虚记录,存储指向真正学生类型的指针。
Network Data Model(网状数据模型)
■The basic data structure is "set",it represent a 1:N relationship between things in real world."1" side is called owner,and "N" side is called member.One record type can be the owner of multi sets,and also can be the member of multi sets.Many sets form a network structure to express real world.
网状数据模型的基本数据结构是系,一个系就表示了两种记录类型之间一对多的关系,其中的“一”我们称为主记录,“多”称为属记录。下面是关键:一种记录类型可以是多个系的主记录,也可以是多个系的属记录。这打破了层次模型只能有一个双亲节点的限制,各种记录类型之间通过系形成复杂的网状结构。
■It breakthrough the limit of hierarchical structure ,so can express non-hierarchical data more easy.
■Record and data items:data items are similar as field in hierarchical model,but it can be vector.
网状数据模型中记录的概念还是一样的,现实世界中的一个实体我们描述成一条记录,所有同类的记录成为一种记录类型。而数据项,和层次模型中的域的概念类似,是用来描述记录的各种属性的,不同的是,数据项可以是向量,即它可以是一种复合类型。我们以后要看到的关系数据模型中对记录属性的描述就必须是原子的,不能是复合类型。
■Set:express the 1:N relationship between two record types.
一个系表达现实世界中两个实体类型之间一对多的关系。
■LINK record type:used to express self relationship,M:N relationship and N-ary relationship.
网状数据模型引入了LINK记录表示现实世界中的自联系、多对多、多元联系等关系。
左上方定义了一个班级和学生一对多关系的系,这是型的定义。右上方给出了这个系的一个值,可以看到它实际上是一个表,班级是表头,如果我需要查询这个班级所有的学生,则从头将链表遍历一次即可。
EMP是雇员类型,我们想表达雇员和雇员之间的领导和被领导的关系,因为单位的领导也是员工,被领导领导的人也是员工,这实际上是雇员类型的自连接。我们不能定义一个系,主记录也是雇员,属记录也是雇员。于是我们引入LINK类型作为领导的替身,首先雇员作为主记录和LINK之间定义一个一对一的系,称s1,再以LINK作为主记录,和雇员之间定义一个一对多的系,称为s2,这是型的定义。在网状数据库中,每一个系型都对应一个链表,我们这里有两种系型,故有两种链表。看右边的例子,Mary是公司的总裁,我们想表示Mary的直接下属都有谁,首先通过s1这个一对一的系型引一个链表,让L1作为Mary的替身,再由L1作为表头,引一个s2的链表,把Mary的直接下属串起来。下面的下属的下属处理方法也类似,先一对一引一个LINK记录,再由这个LINK记录把下属串起来。如果想要查询的话,就遍历链表。
我们引入一个更复杂一点的例子:学生和课程多对多的联系。在层次数据模型中引入虚记录以解决此问题,在网状数据模型中则是引入了LINK记录,网站数据模型中的基本数据结构是系,系只可以表示一对多,我们就通过引入LINK记录将两个一对多的记录拼在一起表示多对多关系。如左上图,在学生和LINK记录中定义一个系SL,学生是主记录,LINK是属记录;在课程和LINK之间定义一个系CL,课程是主记录,LINK是属记录。这样便可以表示学生和课程之间的多对多的关系。右边是一个实例,有两学生,看John,沿着他的SL链表走有四个LINK记录,说明他选了四门课,再沿着各个记录的CL链表走可以做到是什么课程。
小总结
学习上面的两种数据类型我们发现,我们如果想要查询,都必须要编程序,因为查询就要遍历树或链表,我们得可以遍历树和链表才行。