【数据分析代码例】数据处理,柱状图,countplot,分布分析图,箱线图,点线图(折线图),饼图
python3数据分析与挖掘建模实战学习目录
代码实例下载
目录
- 本文的csv文件数据部分截图
- 导入包
- isnull() 判断缺失值
- mean(),std(),max(),min(),median(),skew(),kurt()
- np.histogram() 直方图
- 条件索引 le_s[le_s>1]
- 条件索引链接
- 利用条件索引进行异常值过滤
- value_counts()
- np_s.value_counts(normalize=True) 统计个数的占比
- sort_index() 默认根据行标签对所有行排序,或根据列标签对所有列排序,或根据指定某列或某几列对行排序。
- 配置seaborn包
- Salary柱状图
- countplot
- 分布分析图
- 箱线图
- 点线图(折线图)
- 饼图
- 完整代码
本文的csv文件数据部分截图

导入包
import pandas as pd
import numpy as np
isnull() 判断缺失值
df = pd.read_csv("./data/HR.csv")
#Satisfaction Level
sl_s = df["satisfaction_level"]
sl_null = sl_s.isnull()#是否为空值
print("satisfaction_level.isnull:\n",df[df["satisfaction_level"].isnull()])

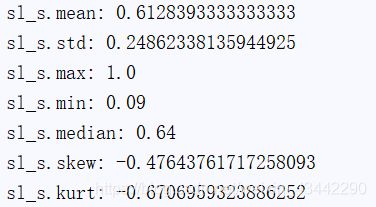
mean(),std(),max(),min(),median(),skew(),kurt()
mean() 求平均值,
std() 求标准差,
max() 求最大值,
min() 求最小值,
median() 求中位数,
skew() 求偏态,
kurt() 求峰态
np.histogram() 直方图
直方图是用面积表示各组频数的多少,矩形的高度表示每一组的频数或频率,宽度则表示各组的组距,因此其高度与宽度均有意义。
sl_s = sl_s.dropna()#丢弃空值
sl_s = sl_s.fillna(1)#将空值填充成1
#常用统计项
print("sl_s.mean:\n",sl_s.mean(),"sl_s.std:\n",sl_s.std(),"sl_s.max:\n",
sl_s.max(),"sl_s.min:\n",sl_s.min(),"sl_s.median:\n",sl_s.median(),
"sl_s.skew:\n",sl_s.skew(),"sl_s.kurt:\n",sl_s.kurt())
#直方图示例
# bins=np.arange(0.0,1.1,0.1) 范围(0.0,1.1),左开右闭,间隔0.1
print("直方图:\n",np.histogram(sl_s.values,bins=np.arange(0.0,1.1,0.1)))

条件索引 le_s[le_s>1]
条件索引链接
data_arr[condition]
#Last Evaluation
le_s = df["last_evaluation"]
le_null=le_s[le_s.isnull()]
print("le_s:\n",le_s)
print("le_s[15000]:",le_s[15000])
print("le_s[le_s>1]:\n",le_s[le_s>1]) # 第 15000 行,数据为 999999
# print("np.histogram:\n",np.histogram(le_s.values, bins=np.arange(0.0, 1.1, 0.1)))

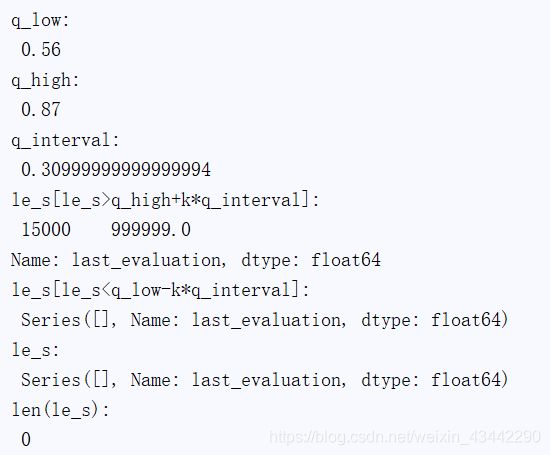
利用条件索引进行异常值过滤
print("le_s:\n",le_s)
print("le_s[15000]:",le_s[15000])
print("le_s[le_s>1]:\n",le_s[le_s>1]) # 第 15000 行,数据为 999999
q_low = le_s.quantile(q=0.25)#下四分位数
print("q_low:\n",q_low)
q_high=le_s.quantile(q=0.75)#上四分位数
print("q_high:\n",q_high)
k=1.5
q_interval = q_high - q_low
print("q_interval:\n",q_interval)
#异常值过滤
print("le_s[le_s>q_high+k*q_interval]:\n",le_s[le_s>q_high+k*q_interval])
print("le_s[le_s,le_s[le_s<q_low-k*q_interval])
le_s=le_s[le_s>q_high+k*q_interval][le_s<q_low-k*q_interval]
print("le_s:\n",le_s)
print("len(le_s):\n",len(le_s))
value_counts()
np_s.value_counts(normalize=True) 统计个数的占比
Python pandas数据计数函数value_counts
sort_index() 默认根据行标签对所有行排序,或根据列标签对所有列排序,或根据指定某列或某几列对行排序。
#Number Project
np_s=df["number_project"]
# print(np_s[np_s.isnull()])
# print(np_s.mean(),np_s.std(),np_s.median(),np_s.max(),np_s.min(),np_s.skew(),np_s.kurt())
print("np_s.value_counts:\n",np_s.value_counts(normalize=True)) # 统计个数的占比
print(np_s.value_counts(normalize=True).sort_index())


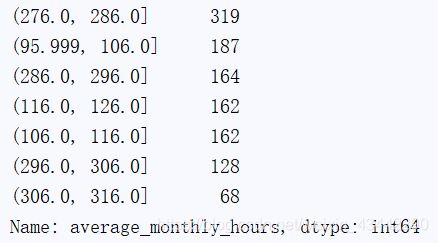
#average_montly_hours
amh_s=df["average_monthly_hours"]
# print(amh_s.mean(),amh_s.std(),amh_s.median(),amh_s.max(),amh_s.min(),amh_s.skew(),amh_s.kurt())
print("11:",amh_s.quantile(0.75)+1.5*(amh_s.quantile(0.75)-amh_s.quantile(0.25)))
print(len(amh_s[amh_s < amh_s.quantile(0.75)+1.5*(amh_s.quantile(0.75)-amh_s.quantile(0.25))]))
print("22:",amh_s.quantile(0.25)-1.5*(amh_s.quantile(0.75)-amh_s.quantile(0.25)))
print(len([amh_s>amh_s.quantile(0.25)-1.5*(amh_s.quantile(0.75)-amh_s.quantile(0.25))]))
print("33:",len(amh_s[amh_s < amh_s.quantile(0.75)+1.5*(amh_s.quantile(0.75)-amh_s.quantile(0.25))][amh_s>amh_s.quantile(0.25)-1.5*(amh_s.quantile(0.75)-amh_s.quantile(0.25))]))

interval=10
print(np.histogram(amh_s.values,bins=np.arange(amh_s.min(),amh_s.max()+interval,interval)))
print(amh_s.value_counts(bins=np.arange(amh_s.min(),amh_s.max()+interval,interval)))


#Work Accident
wa_s=df["Work_accident"]
print(wa_s.value_counts())
#Left
l_s=df["left"]
print("l_s.value_counts:\n",l_s.value_counts())

#promotion_last_5years
pl5_s=df["promotion_last_5years"]
print("pl5_s.value_counts:\n",pl5_s.value_counts())

#salary
s_s=df["salary"]
print("s_s.value_counts:\n",s_s.value_counts())

#department
d_s=df["department"]
print("d_s.value_counts(normalize=True):\n",d_s.value_counts(normalize=True))
print("d_s.where(d_s!= sale):\n",d_s.where(d_s!="sale"))



#交叉
df=df.dropna(how="any",axis=0)
df=df[df["last_evaluation"]<=1][df["salary"]!="nme"][df["department"]!="sale"]
print("df:\n",df)


sub_df_1=df.loc[:,["satisfaction_level","department"]]
print("sub_df_1:\n",sub_df_1)
print("sub_df_1.groupby(department):\n",sub_df_1.groupby("department"))
print("sub_df_1.groupby(department).mean():\n",sub_df_1.groupby("department").mean())


![]()

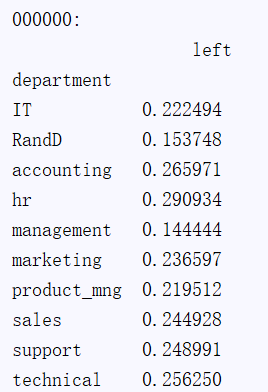
sub_df_2 = df.loc[:,["left","department"]]
print("sub_df_2:\n",sub_df_2)
print("000000:\n",sub_df_2.groupby("department").mean())


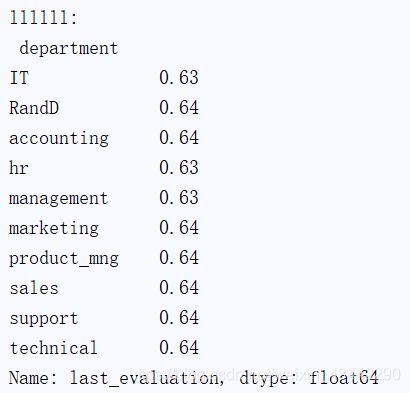
sub_df_3=df.loc[:,["last_evaluation","department"]]
print("sub_df_3:\n",sub_df_3)


print("llllll:\n",sub_df_3.groupby("department",group_keys=False)["last_evaluation"].apply(lambda x:x.max()-x.min()))
print("222222:\n",df.groupby("department").mean())

#Visual
import seaborn as sns
import matplotlib.pyplot as plt
sns.set_style(style="darkgrid")#配置样式
sns.set_context(context="poster",font_scale=1.5)#配置字体
sns.set_palette(sns.color_palette("RdBu", n_colors=7))#配置色板
配置seaborn包

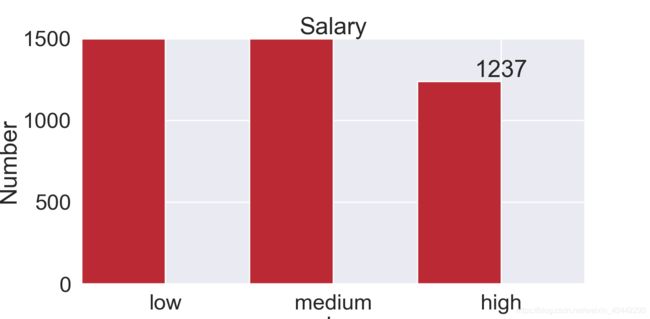
Salary柱状图
#Salary柱状图
plt.title("Salary")
plt.bar(np.arange(len(df["salary"].value_counts()))+0.25,df["salary"].value_counts(),width=0.5)
plt.xticks(np.arange(len(df["salary"].value_counts()))+0.5,df["salary"].value_counts().index)
plt.axis([0,3,0,9000])
plt.xlabel("salary")
plt.ylabel("Number")
for x,y in zip(np.arange(len(df["salary"].value_counts()))+0.5,df["salary"].value_counts()):
plt.text(x,y,y,ha="center",va="bottom")
plt.ylim(0,1500)
plt.show()
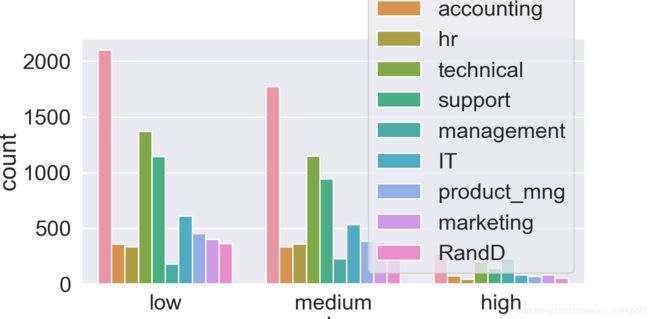
countplot
countplot是seaborn库中分类图的一种,作用是使用条形显示每个分箱器中的观察计数
countplot
#countplot
sns.countplot(x="salary",hue="department",data=df)
plt.show()
分布分析图
#分布分析图
f=plt.figure(0)
f.add_subplot(1,3,1)
sns.distplot(df["satisfaction_level"],bins=10)
f.add_subplot(1,3,2)
sns.distplot(df["last_evaluation"],bins=10)
f.add_subplot(1,3,3)
sns.distplot(df["average_monthly_hours"],bins=10)
plt.show()

箱线图
#箱线图
sns.boxplot(y=df["last_evaluation"],saturation=0.75)
plt.show()

点线图(折线图)
#点线图(折线图)
sub_df=df.groupby("time_spend_company").mean()
sns.pointplot(x="time_spend_company",y="left",data=df)
#sns.pointplot(sub_df.index,sub_df["left"])
plt.show()

饼图
#饼图
lbs=df["department"].value_counts().index
explodes=[0.1 if i=="sales" else 0 for i in lbs ]
plt.pie(df["department"].value_counts(normalize=True),explode=explodes,autopct='%1.1f%%',colors=sns.color_palette("Reds", n_colors=7),labels=df["department"].value_counts().index)
plt.show()
plt.pie(df["number_project"].value_counts(normalize=True),labels=df["number_project"].value_counts().index)
plt.show()

完整代码
import pandas as pd
import numpy as np
def main():
df = pd.read_csv("./data/HR.csv")
#Satisfaction Level
sl_s = df["satisfaction_level"]
sl_null = sl_s.isnull()#是否为空值
print(df[df["satisfaction_level"].isnull()])
sl_s = sl_s.dropna()#丢弃空值
sl_s = sl_s.fillna(1)#将空值填充成1
#常用统计项
print(sl_s.mean(),sl_s.std(),sl_s.max(),sl_s.min(),sl_s.median(),sl_s.skew(),sl_s.kurt())
#直方图示例
print(np.histogram(sl_s.values,bins=np.arange(0.0,1.1,0.1)))
#Last Evaluation
le_s = df["last_evaluation"]
le_null=le_s[le_s.isnull()]
#常见统计项
print(le_s.mean(),le_s.std(),le_s.median(),le_s.max(),\
le_s.min(),le_s.skew(),le_s.kurt())
print(le_s[le_s>1])
q_low=le_s.quantile(q=0.25)#下四分位数
q_high=le_s.quantile(q=0.75)#上四分位数
k=1.5
q_interval=q_high-q_low
#异常值过滤
le_s=le_s[le_s>q_high+k*q_interval][le_s<q_low-k*q_interval]
print(len(le_s))
print(np.histogram(le_s.values, bins=np.arange(0.0, 1.1, 0.1)))
#Number Project
np_s=df["number_project"]
print(np_s[np_s.isnull()])
print(np_s.mean(),np_s.std(),np_s.median(),np_s.max(),np_s.min(),np_s.skew(),np_s.kurt())
print(np_s.value_counts(normalize=True).sort_index())
#average_montly_hours
amh_s=df["average_monthly_hours"]
print(amh_s.mean(),amh_s.std(),amh_s.median(),amh_s.max(),amh_s.min(),amh_s.skew(),amh_s.kurt())
print(len(amh_s[amh_s<amh_s.quantile(0.75)+1.5*(amh_s.quantile(0.75)-amh_s.quantile(0.25))][amh_s>amh_s.quantile(0.25)-1.5*(amh_s.quantile(0.75)-amh_s.quantile(0.25))]))
interval=10
print(np.histogram(amh_s.values,bins=np.arange(amh_s.min(),amh_s.max()+interval,interval)))
print(amh_s.value_counts(bins=np.arange(amh_s.min(),amh_s.max()+interval,interval)))
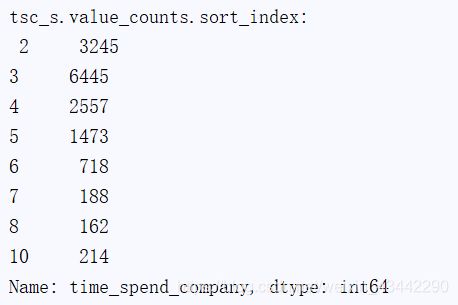
#Time Spend Company
tsc_s=df["time_spend_company"]
print(tsc_s.value_counts().sort_index())
#Work Accident
wa_s=df["Work_accident"]
print(wa_s.value_counts())
#Left
l_s=df["left"]
print(l_s.value_counts())
#promotion_last_5years
pl5_s=df["promotion_last_5years"]
print(pl5_s.value_counts())
#salary
s_s=df["salary"]
print(s_s.value_counts())
#department
d_s=df["department"]
print(d_s.value_counts(normalize=True))
print(d_s.where(d_s!="sale"))
#交叉
df=df.dropna(how="any",axis=0)
df=df[df["last_evaluation"]<=1][df["salary"]!="nme"][df["department"]!="sale"]
sub_df_1=df.loc[:,["satisfaction_level","department"]]
print(sub_df_1.groupby("department").mean())
sub_df_2=df.loc[:,["left","department"]]
print(sub_df_2.groupby("department").mean())
sub_df_3=df.loc[:,["last_evaluation","department"]]
print(sub_df_3.groupby("department",group_keys=False)["last_evaluation"].apply(lambda x:x.max()-x.min()))
print(df.groupby("department").mean())
#Visual
import seaborn as sns
import matplotlib.pyplot as plt
sns.set_style(style="darkgrid")#配置样式
sns.set_context(context="poster",font_scale=1.5)#配置字体
sns.set_palette(sns.color_palette("RdBu", n_colors=7))#配置色板
#Salary柱状图
plt.title("Salary")
plt.bar(np.arange(len(df["salary"].value_counts()))+0.25,df["salary"].value_counts(),width=0.5)
plt.xticks(np.arange(len(df["salary"].value_counts()))+0.5,df["salary"].value_counts().index)
plt.axis([0,3,0,9000])
plt.xlabel("salary")
plt.ylabel("Number")
for x,y in zip(np.arange(len(df["salary"].value_counts()))+0.5,df["salary"].value_counts()):
plt.text(x,y,y,ha="center",va="bottom")
plt.ylim(0,1500)
plt.show()
#countplot
sns.countplot(x="salary",hue="department",data=df)
plt.show()
#分布分析图
f=plt.figure(0)
f.add_subplot(1,3,1)
sns.distplot(df["satisfaction_level"],bins=10)
f.add_subplot(1,3,2)
sns.distplot(df["last_evaluation"],bins=10)
f.add_subplot(1,3,3)
sns.distplot(df["average_monthly_hours"],bins=10)
plt.show()
#箱线图
sns.boxplot(y=df["last_evaluation"],saturation=0.75)
plt.show()
#点线图(折线图)
sub_df=df.groupby("time_spend_company").mean()
sns.pointplot(x="time_spend_company",y="left",data=df)
#sns.pointplot(sub_df.index,sub_df["left"])
plt.show()
#饼图
lbs=df["department"].value_counts().index
explodes=[0.1 if i=="sales" else 0 for i in lbs ]
plt.pie(df["department"].value_counts(normalize=True),explode=explodes,autopct='%1.1f%%',colors=sns.color_palette("Reds", n_colors=7),labels=df["department"].value_counts().index)
plt.show()
plt.pie(df["number_project"].value_counts(normalize=True),labels=df["number_project"].value_counts().index)
plt.show()
if __name__=="__main__":
main()