RocketMQ关键问题研究
文章目录
- RocketMQ的基本角色
- RocketMQ的高可用模式?
- NameServer有没有状态,为什么?
- Broker的自动选举高可用部署
- 如果slave先master启动会不会有问题?
- RocketMQ中关键角色的通信问题(基于容器)?
- 生产者重试机制?
- 消费者的消息重试
- 消息的存储的理解
- 消息消费如何保障幂等?
- 大消息直接进MQ会有什么影响,能不能使用(数kb~数百kb)?
- Tags的使用和理解
- Keys的使用和理解
- 日志的打印
- NameServer内部的数据结构
- RocketMQ的事务消息是如何
- 消息堆积的能力
- **消息可靠性理解**
- **同步刷盘和异步刷盘的区别**
- 如何读老消息?
- Consumer的处理逻辑
- RocketMQ中的负载均衡
- **消费速度慢的处理方式**
- Consumer消息消费的位点的理解
- 强顺序消息的应对手段
- RocketMQ消息磁盘满了怎么办
- Client端MQ的优雅停机问题
- 当broker重启,consumer会有什么影响
- 待研究
- Consumer在Push模式下,流控策略
- Consumer的批量消费
- Tags是如何工作的,在数据结构上有什么体现?
RocketMQ的基本角色
- Producer:消息发布的角色,支持分布式集群方式部署。Producer通过MQ的负载均衡模块选择相应的Broker集群队列进行消息投递,投递的过程支持快速失败并且低延迟。
- Consumer:消息消费的角色,支持分布式集群方式部署。支持以push推,pull拉两种模式对消息进行消费。同时也支持集群方式和广播方式的消费,它提供实时消息订阅机制,可以满足大多数用户的需求。
- NameServer:NameServer是一个非常简单的Topic路由注册中心,其角色类似Dubbo中的zookeeper,支持Broker的动态注册与发现。主要包括两个功能:Broker管理,NameServer接受Broker集群的注册信息并且保存下来作为路由信息的基本数据。然后提供心跳检测机制,检查Broker是否还存活;路由信息管理,每个NameServer将保存关于Broker集群的整个路由信息和用于客户端查询的队列信息。然后Producer和Conumser通过NameServer就可以知道整个Broker集群的路由信息,从而进行消息的投递和消费。NameServer通常也是集群的方式部署,各实例间相互不进行信息通讯。Broker是向每一台NameServer注册自己的路由信息,所以每一个NameServer实例上面都保存一份完整的路由信息。当某个NameServer因某种原因下线了,Broker仍然可以向其它NameServer同步其路由信息,Producer,Consumer仍然可以动态感知Broker的路由的信息。
- BrokerServer:Broker主要负责消息的存储、投递和查询以及服务高可用保证,为了实现这些功能,Broker包含了以下几个重要子模块。
RocketMQ的高可用模式?
首先创建一组NameServer服务,NameServerr本身无状态,可以自由横向拓展。消息存储在Broker中,消息的丢失会严重影响业务,因此Broker必须部署为主从模式,master可以读写,slave只读;当只有一个master broker显然不满足可拓展性,不过我们可以部署多组master slave结构的broker并且可以无限拓展。
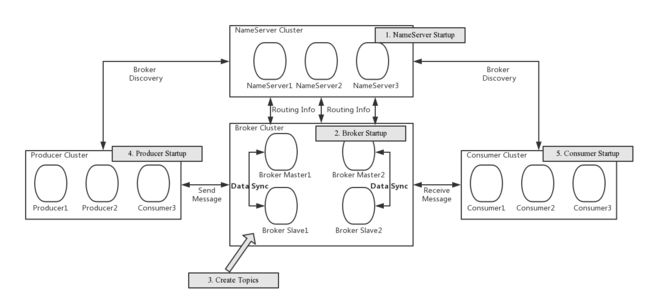
- NameServer是一个几乎无状态节点,可集群部署,节点之间无任何信息同步。
- Broker部署相对复杂,Broker分为Master与Slave,一个Master可以对应多个Slave,但是一个Slave只能对应一个Master,Master与Slave 的对应关系通过指定相同的BrokerName,不同的BrokerId 来定义,BrokerId为0表示Master,非0表示Slave。Master也可以部署多个。每个Broker与NameServer集群中的所有节点建立长连接,定时注册Topic信息到所有NameServer。 注意:当前RocketMQ版本在部署架构上支持一Master多Slave,但只有BrokerId=1的从服务器才会参与消息的读负载。
- Producer与NameServer集群中的其中一个节点(随机选择)建立长连接,定期从NameServer获取Topic路由信息,并向提供Topic 服务的Master建立长连接,且定时向Master发送心跳。Producer完全无状态,可集群部署。
- Consumer与NameServer集群中的其中一个节点(随机选择)建立长连接,定期从NameServer获取Topic路由信息,并向提供Topic服务的Master、Slave建立长连接,且定时向Master、Slave发送心跳。Consumer既可以从Master订阅消息,也可以从Slave订阅消息,消费者在向Master拉取消息时,Master服务器会根据拉取偏移量与最大偏移量的距离(判断是否读老消息,产生读I/O),以及从服务器是否可读等因素建议下一次是从Master还是Slave拉取。
建设RocketMQ集群,Broker采用多Master多Slave模式,Master-Slave保障消息不丢,多Master保障消息中间件可用。
NameServer有没有状态,为什么?
所有Broker会定时向NameServer注册自己,并且携带自己的topicInfo,因此如果NameServer重启,注册信息还是会添加进去;client会根据topic获取broker,如果查询不到,会到另外的NameServer查询获取broker;如果client拿到过期的broker信息,影响不大,provider当发送不可用,会进行重试,默认是2次,重试不过还可以尝试去发送其他broker,不过注意重试可能造成消息重复。因此只需要保障NameServer的可用性,而无需关注其数据一致性。
Broker的自动选举高可用部署
多副本最早的是Master/Slave架构,即简单地用Slave去同步Master的数据,然而这样最大的弊端就是无法自动切换Slave成为Master,而造成消息的不可写,影响系统整体可用性。Dledger-RocketMQ 基于Raft协议的commitlog存储库,可以实现集群自动选举master leader,至少部署3个节点。
apache/rocketmq
部署成功,杀掉 Leader 之后(在上面的例子中,杀掉端口 30931 所在的进程),等待约 10s 左右,用 clusterList 命令查看集群,就会发现 Leader 切换到另一个节点了。
如果slave先master启动会不会有问题?
broker启动当是Slave时候,会注册一个每3秒执行的定时任务,负责从master同步数据,同步方法参见SlaveSynchronize。因此slave和master没有先后启动顺序
RocketMQ中关键角色的通信问题(基于容器)?
-
broker的master和slave的通信:首先slave需要知道master地址。如果以有状态服务部署,则通过如rocket-01-master来访问master;如果是无状态则新建一个service管理master note供slave访问
-
nameserver与broker通信:首先所有broker需要知道每一个slave的地址。因此nameserver的每一个实例需要有一个独立且不变的地址供broker访问。
Broker启动后需要完成一次将自己注册至NameServer的操作;随后每隔30s时间定时向NameServer上报Topic路由信息。
-
client与nameserver通信:首先client需要跟nameserver的所有实例建立连接,因为只有配置多实例,一个找不到才会去另一个找。
消息生产者Producer作为客户端发送消息时候,需要根据消息的Topic从本地缓存的TopicPublishInfoTable获取路由信息。如果没有则更新路由信息会从NameServer上重新拉取,同时Producer会默认每隔30s向NameServer拉取一次路由信息。
消息生产者Producer根据上一步中获取的路由信息选择一个队列(MessageQueue)进行消息发送;Broker作为消息的接收者接收消息并落盘存储。
消息消费者Consumer根据Topic从NameServer中获取的路由信息,并再完成客户端的负载均衡后,选择其中的某一个或者某几个消息队列来拉取消息并进行消费。
生产者重试机制?
Producer的send方法本身支持内部重试,重试逻辑如下:
- 至多重试2次(同步发送为2次,异步发送为0次)。
- 如果发送失败,则轮转到下一个Broker。这个方法的总耗时时间不超过sendMsgTimeout设置的值,默认10s。
- 如果本身向broker发送消息产生超时异常,就不会再重试。
同时根据消息类型的不同另有区别。
- 普通消息:消息是无序的,任意发送发送哪一个队列都可以。
- 普通有序消息:同一类消息(例如某个用户的消息)总是发送到同一个队列,在异常情况下,也可以发送到其他队列。
- 严格有序消息:消息必须被发送到同一个队列,即使在异常情况下,也不允许发送到其他队列。
如果业务对消息可靠性要求比较高,建议应用增加相应的重试逻辑:比如调用send同步方法发送失败时,则尝试将消息存储到db,然后由后台线程定时重试,确保消息一定到达Broker。
消费者的消息重试
Consumer消费消息失败后,要提供一种重试机制,令消息再消费一次。Consumer消费消息失败通常可以认为有以下几种情况:
- 由于消息本身的原因,例如反序列化失败,消息数据本身无法处理(例如话费充值,当前消息的手机号被注销,无法充值)等。这种错误通常需要跳过这条消息,再消费其它消息,而这条失败的消息即使立刻重试消费,99%也不成功,所以最好提供一种定时重试机制,即过10秒后再重试。
- 由于依赖的下游应用服务不可用,例如db连接不可用,外系统网络不可达等。遇到这种错误,即使跳过当前失败的消息,消费其他消息同样也会报错。这种情况建议应用sleep 30s,再消费下一条消息,这样可以减轻Broker重试消息的压力。
RocketMQ会为每个消费组都设置一个Topic名称为“%RETRY%+consumerGroup”的重试队列(这里需要注意的是,这个Topic的重试队列是针对消费组,而不是针对每个Topic设置的),用于暂时保存因为各种异常而导致Consumer端无法消费的消息。考虑到异常恢复起来需要一些时间,会为重试队列设置多个重试级别,每个重试级别都有与之对应的重新投递延时,重试次数越多投递延时就越大。RocketMQ对于重试消息的处理是先保存至Topic名称为“SCHEDULE_TOPIC_XXXX”的延迟队列中,后台定时任务按照对应的时间进行Delay后重新保存至“%RETRY%+consumerGroup”的重试队列中。
RocketMQ可在broker.conf文件中配置Consumer端的重试次数和重试时间间隔,如下:
messageDelayLevel=1s 5s 10s 30s 1m 2m 3m 4m 5m 6m 7m 8m 9m 10m 20m 30m 1h 2h
在Consumer中maxReconsumeTimes可以配置重试次数,默认是-1,-1代表16次最大,如果超过maxReconsumeTimes次数,则会被放到一个等待队列
消息的存储的理解

消息存储架构图中主要有下面三个跟消息存储相关的文件构成。
(1) CommitLog:消息主体以及元数据的存储主体,存储Producer端写入的消息主体内容,消息内容不是定长的。单个文件大小默认1G ,文件名长度为20位,左边补零,剩余为起始偏移量,比如00000000000000000000代表了第一个文件,起始偏移量为0,文件大小为1G=1073741824;当第一个文件写满了,第二个文件为00000000001073741824,起始偏移量为1073741824,以此类推。消息主要是顺序写入日志文件,当文件满了,写入下一个文件;
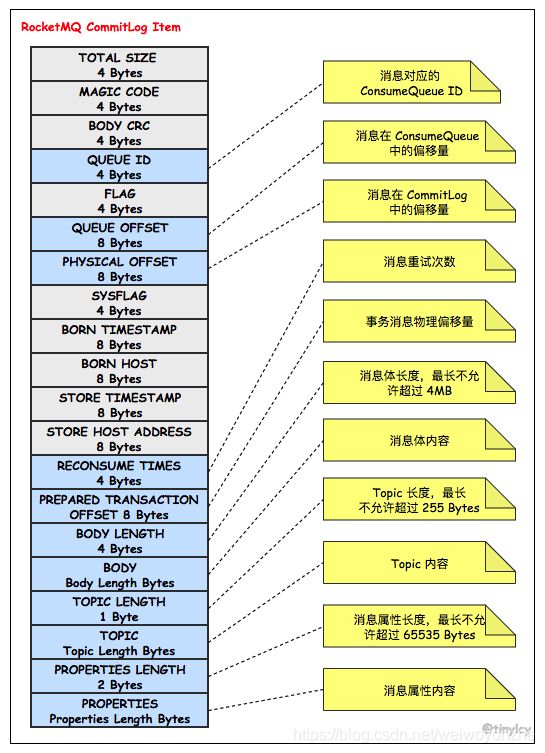
(2) ConsumeQueue:消息消费队列,引入的目的主要是提高消息消费的性能,由于RocketMQ是基于主题topic的订阅模式,消息消费是针对主题进行的,如果要遍历commitlog文件中根据topic检索消息是非常低效的。Consumer即可根据ConsumeQueue来查找待消费的消息。其中,ConsumeQueue(逻辑消费队列)作为消费消息的索引,保存了指定Topic下的队列消息在CommitLog中的起始物理偏移量offset,消息大小size和消息Tag的HashCode值。consumequeue文件可以看成是基于topic的commitlog索引文件,故consumequeue文件夹的组织方式如下:topic/queue/file三层组织结构,具体存储路径为:$HOME/store/consumequeue/{topic}/{queueId}/{fileName}。同样consumequeue文件采取定长设计,每一个条目共20个字节,分别为8字节的commitlog物理偏移量、4字节的消息长度、8字节tag hashcode,单个文件由30W个条目组成,可以像数组一样随机访问每一个条目,每个ConsumeQueue文件大小约5.72M;

拓展:RocketMQ 利用 mmap 将文件直接映射到用户态内存地址,由此将对文件的 IO 转化为对内存的 IO。
(3) IndexFile:IndexFile(索引文件)提供了一种可以通过topic、key或时间区间来查询消息的方法。Index文件的存储位置是:KaTeX parse error: Undefined control sequence: \store at position 6: HOME \̲s̲t̲o̲r̲e̲\index{fileName},文件名fileName是以创建时的时间戳命名的,固定的单个IndexFile文件大小约为400M,一个IndexFile可以保存 2000W个索引,IndexFile的底层存储设计为在文件系统中实现HashMap结构,故rocketmq的索引文件其底层实现为hash索引。
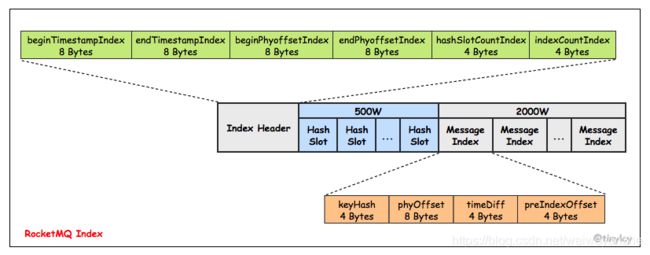
存储机制参考:
RocketMQ高性能之底层存储设计
消息消费如何保障幂等?
RocketMQ无法避免消息重复(Exactly-Once),所以如果业务对消费重复非常敏感,务必要在业务层面进行去重处理。可以借助关系数据库进行去重。首先需要确定消息的唯一键,可以是msgId,也可以是消息内容中的唯一标识字段,例如订单Id等。在消费之前判断唯一键是否在关系数据库中存在。如果不存在则插入,并消费,否则跳过。(实际过程要考虑原子性问题,判断是否存在可以尝试插入,如果报主键冲突,则插入失败,直接跳过)
msgId一定是全局唯一标识符,但是实际使用中,可能会存在相同的消息有两个不同msgId的情况(消费者主动重发、因客户端重投机制导致的重复等),这种情况就需要使业务字段进行重复消费。
拓展:消息领域有一个对消息投递的QoS定义,分为:
- 最多一次(At most once)
- 至少一次(At least once)
- 仅一次( Exactly once)
大消息直接进MQ会有什么影响,能不能使用(数kb~数百kb)?
- 在Consumer消费时,如果批量拉取消息,涉及到broker随机IO读取文件、网络传输开销,在consumer消息放在内存中,导致consumer内存不可控
- broker消息存储需要尽可能快,如果慢则会占用线程池资源,导致broker整体吞吐量大大降低,broker线程池不够,抛出[OVERLOAD]system busy异常或者[TIMEOUT_CLEAN_QUEUE]broker busy,。
Tags的使用和理解
一个应用尽可能用一个Topic,而消息子类型则可以用tags来标识。tags可以由应用自由设置,只有生产者在发送消息设置了tags,消费方在订阅消息时才可以利用tags通过broker做消息过滤:message.setTags(“TagA”)。
Keys的使用和理解
每个消息在业务层面的唯一标识码要设置到keys字段,方便将来定位消息丢失问题。服务器会为每个消息创建索引(哈希索引),应用可以通过topic、key来查询这条消息内容,以及消息被谁消费。由于是哈希索引,请务必保证key尽可能唯一,这样可以避免潜在的哈希冲突。
日志的打印
消息发送成功或者失败要打印消息日志,务必要打印SendResult和key字段。send消息方法只要不抛异常,就代表发送成功。发送成功会有多个状态,在sendResult里定义。以下对每个状态进行说明:
- SEND_OK
消息发送成功。要注意的是消息发送成功也不意味着它是可靠的。要确保不会丢失任何消息,还应启用同步Master服务器或同步刷盘,即SYNC_MASTER或SYNC_FLUSH。
- FLUSH_DISK_TIMEOUT
消息发送成功但是服务器刷盘超时。此时消息已经进入服务器队列(内存),只有服务器宕机,消息才会丢失。消息存储配置参数中可以设置刷盘方式和同步刷盘时间长度,如果Broker服务器设置了刷盘方式为同步刷盘,即FlushDiskType=SYNC_FLUSH(默认为异步刷盘方式),当Broker服务器未在同步刷盘时间内(默认为5s)完成刷盘,则将返回该状态——刷盘超时。
- FLUSH_SLAVE_TIMEOUT
消息发送成功,但是服务器同步到Slave时超时。此时消息已经进入服务器队列,只有服务器宕机,消息才会丢失。如果Broker服务器的角色是同步Master,即SYNC_MASTER(默认是异步Master即ASYNC_MASTER),并且从Broker服务器未在同步刷盘时间(默认为5秒)内完成与主服务器的同步,则将返回该状态——数据同步到Slave服务器超时。
- SLAVE_NOT_AVAILABLE
消息发送成功,但是此时Slave不可用。如果Broker服务器的角色是同步Master,即SYNC_MASTER(默认是异步Master服务器即ASYNC_MASTER),但没有配置slave Broker服务器,则将返回该状态——无Slave服务器可用。
在Consumer消费端,如果消息量较少,建议在消费入口方法打印消息,消费耗时等,方便后续排查问题。
public ConsumeConcurrentlyStatus consumeMessage(
List<MessageExt> msgs,
ConsumeConcurrentlyContext context) {
log.info("RECEIVE_MSG_BEGIN: " + msgs.toString());
// TODO 正常消费过程
return ConsumeConcurrentlyStatus.CONSUME_SUCCESS;
}
如果能打印每条消息消费耗时,那么在排查消费慢等线上问题时,会更方便。
NameServer内部的数据结构
- topicQueueTable 维护了 Topic 和其对应消息队列的映射关系,QueueData 记录了一条队列的元信息:所在 Broker、读队列数量、写队列数量等。
- brokerAddrTable 维护了 Broker Name 和 Broker 元信息的映射关系,Broker 通常以 Master-Slave 架构部署,BrokerData 记录了同一个 Broker Name 下所有节点的地址信息。
- clusterAddrTable 维护了 Broker 的集群信息。
- brokerLiveTable 维护了 Broker 的存活信息。NameServer 在收到来自 Broker 的心跳消息后,更新 BrokerLiveInfo 中的 lastUpdateTimestamp,如果 NameServer 长时间未收到 Broker 的心跳信息,NameServer 就会将其移除。
- filterServerTable 用于消息过滤。

RocketMQ的事务消息是如何
Half Message(半消息)是指暂不能被Consumer消费的消息。Producer 已经把消息成功发送到了 Broker 端,但此消息被标记为暂不能投递状态,处于该种状态下的消息称为半消息。需要 Producer对消息的二次确认后,Consumer才能去消费它。
消息回查,由于网络闪段,生产者应用重启等原因。导致 Producer 端一直没有对 Half Message(半消息) 进行 二次确认。这是Brock服务器会定时扫描长期处于半消息的消息,会主动询问 Producer端 该消息的最终状态(Commit或者Rollback),该消息即为 消息回查。
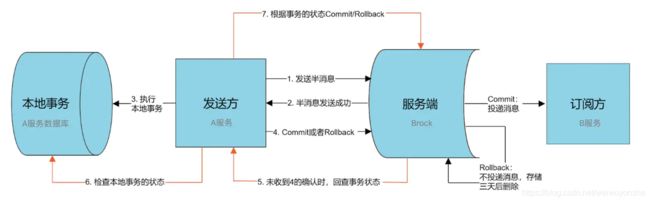
- A服务先发送个Half Message给Brock端,消息中携带 B服务 即将要+100元的信息。
- 当A服务知道Half Message发送成功后,那么开始第3步执行本地事务。
- 执行本地事务(会有三种情况1、执行成功。2、执行失败。3、网络等原因导致没有响应)
- 如果本地事务成功,那么Product像Brock服务器发送Commit,这样B服务就可以消费该message。
- 如果本地事务失败,那么Product像Brock服务器发送Rollback,那么就会直接删除上面这条半消息。
- 如果因为网络等原因迟迟没有返回失败还是成功,那么会执行RocketMQ的回调接口,来进行事务的回查。
消息堆积的能力
消息中间件的主要功能是异步解耦,还有个重要功能是挡住前端的数据洪峰,保证后端系统的稳定性,这就要求消息中间件具有一定的消息堆积能力,消息堆积分以下两种情况:
- 消息堆积在内存Buffer,一旦超过内存Buffer,可以根据一定的丢弃策略来丢弃消息,如CORBA Notification规范中描述。适合能容忍丢弃消息的业务,这种情况消息的堆积能力主要在于内存Buffer大小,而且消息堆积后,性能下降不会太大,因为内存中数据多少对于对外提供的访问能力影响有限。
- 消息堆积到持久化存储系统中,例如DB,KV存储,文件记录形式。 当消息不能在内存Cache命中时,要不可避免的访问磁盘,会产生大量读IO,读IO的吞吐量直接决定了消息堆积后的访问能力。
评估消息堆积能力主要有以下四点:
- 消息能堆积多少条,多少字节?即消息的堆积容量。
- 消息堆积后,发消息的吞吐量大小,是否会受堆积影响?
- 消息堆积后,正常消费的Consumer是否会受影响?
- 消息堆积后,访问堆积在磁盘的消息时,吞吐量有多大
消息可靠性理解
RocketMQ支持消息的高可靠,影响消息可靠性的几种情况:
- Broker非正常关闭
- Broker异常Crash 损坏
- OS Crash 损坏
- 机器掉电,但是能立即恢复供电情况
- 机器无法开机(可能是cpu、主板、内存等关键设备损坏)
- 磁盘设备损坏
1)、2)、3)、4) 四种情况都属于硬件资源可立即恢复情况,RocketMQ在这四种情况下能保证消息不丢,或者丢失少量数据(依赖刷盘方式是同步还是异步)。
5)、6)属于单点故障,且无法恢复,一旦发生,在此单点上的消息全部丢失。RocketMQ在这两种情况下,通过异步复制,可保证99%的消息不丢,但是仍然会有极少量的消息可能丢失。通过同步双写技术可以完全避免单点(master-slave),同步双写势必会影响性能,适合对消息可靠性要求极高的场合,例如与Money相关的应用。注:RocketMQ从3.0版本开始支持同步双写。
同步刷盘和异步刷盘的区别
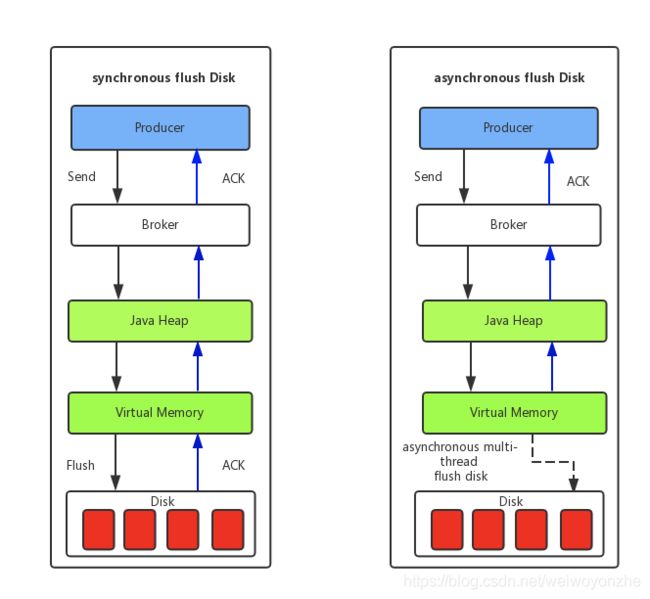
(1) 同步刷盘:如上图所示,只有在消息真正持久化至磁盘后RocketMQ的Broker端才会真正返回给Producer端一个成功的ACK响应。同步刷盘对MQ消息可靠性来说是一种不错的保障,但是性能上会有较大影响,一般适用于金融业务应用该模式较多。
(2) 异步刷盘:能够充分利用OS的PageCache的优势,只要消息写入PageCache即可将成功的ACK返回给Producer端。消息刷盘采用后台异步线程提交的方式进行,降低了读写延迟,提高了MQ的性能和吞吐量。
同步刷盘是在每条消息都确认落盘了之后才向发送者返回响应;而异步刷盘中,只要消息保存到Broker的内存就向发送者返回响应,Broker会有专门的线程对内存中的消息进行批量存储。所以异步刷盘的策略下,当机器突然掉电时,Broker内存中的消息因无法刷到磁盘导致丢失。
如何读老消息?
我们都知道,RocketMQ的数据是要落盘的,一般只有最新写入的数据才会在PageCache中。比如下游消费数据,因为一些原因停了一天之后,又突然起来消费数据。这个时候就需要读磁盘上的数据。然后RocketMQ的消息体是全部存储在一个append only的 commitlog 中的。如果这个集群中混杂了很多不同topic的数据的话,要读的两条消息就很有可能间隔很远。最坏情况就是一次磁盘IO读一条消息。这就基本等价于随机读取了。如果磁盘的IOPS(Input/Output Operations Per Second)扛不住,还会影响数据的写入,这个问题就严重了。
值得庆幸的是,RocketMQ提供了自动从Slave读取老数据的功能。这个功能主要由slaveReadEnable这个参数控制。默认是关的(slaveReadEnable = false bydefault)。推荐把它打开,主从都要开。这个参数打开之后,在客户端消费数据时,会判断,当前读取消息的物理偏移量跟最新的位置的差值,是不是超过了内存容量的一个百分比(accessMessageInMemoryMaxRatio= 40 by default)。如果超过了,就会告诉客户端去备机上消费数据。如果采用异步主从,也就是brokerRole等于ASYNC_AMSTER的时候,你的备机IO打爆,其实影响不太大。但是如果你采用同步主从,那还是有影响。所以这个时候,最好挂两个备机。因为RocketMQ的主从同步复制,只要一个备机响应了确认写入就可以了,一台IO打爆,问题不大。
Consumer的处理逻辑

消费端会通过RebalanceService线程,10秒钟做一次基于Topic下的所有队列负载。
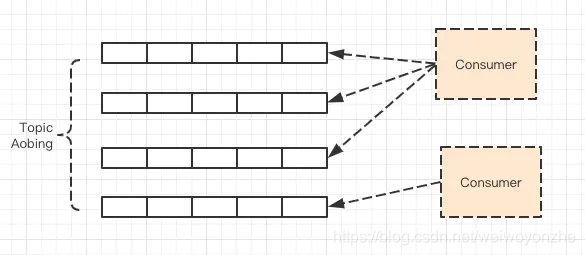
RocketMQ中的负载均衡
RocketMQ中的负载均衡都在Client端完成,具体来说的话,主要可以分为Producer端发送消息时候的负载均衡和Consumer端订阅消息的负载均衡。
Producer的负载均衡
Producer端在发送消息的时候,会先根据Topic找到指定的TopicPublishInfo,在获取了TopicPublishInfo路由信息后,RocketMQ的客户端在默认方式下selectOneMessageQueue()方法会从TopicPublishInfo中的messageQueueList中选择一个队列(MessageQueue)进行发送消息。具体的容错策略均在MQFaultStrategy这个类中定义。这里有一个sendLatencyFaultEnable开关变量,如果开启,在随机递增取模的基础上,再过滤掉not available的Broker代理。所谓的"latencyFaultTolerance",是指对之前失败的,按一定的时间做退避。例如,如果上次请求的latency超过550Lms,就退避3000Lms;超过1000L,就退避60000L;如果关闭,采用随机递增取模的方式选择一个队列(MessageQueue)来发送消息,latencyFaultTolerance机制是实现消息发送高可用的核心关键所在。
Consumer的负载均衡
消费者组下的消费者实例,怎么知道自己需要消费某个 Topic 下的哪些 MessageQueue 呢?

RocketMQ 针对 MessageQueue 提供了多种可选的分配策略,例如平均分配、轮询分配、固定分配等,在实际生产环境中可能还需要根据机房进行就近路由分配、粘滞分配(使得 MessageQueue 变动次数最小)等。
Reblance机制

消费速度慢的处理方式
- 提高消费并行度
绝大部分消息消费行为都属于 IO 密集型,即可能是操作数据库,或者调用 RPC,这类消费行为的消费速度在于后端数据库或者外系统的吞吐量,通过增加消费并行度,可以提高总的消费吞吐量,但是并行度增加到一定程度,反而会下降。所以,应用必须要设置合理的并行度。 如下有几种修改消费并行度的方法:
- 同一个 ConsumerGroup 下,通过增加 Consumer 实例数量来提高并行度(需要注意的是超过订阅队列数的 Consumer 实例无效)。可以通过加机器,或者在已有机器启动多个进程的方式。
- 提高单个 Consumer 的消费并行线程,通过修改参数 consumeThreadMin、consumeThreadMax实现。
2. 批量方式消费
某些业务流程如果支持批量方式消费,则可以很大程度上提高消费吞吐量,例如订单扣款类应用,一次处理一个订单耗时 1 s,一次处理 10 个订单可能也只耗时 2 s,这样即可大幅度提高消费的吞吐量,通过设置 consumer的 consumeMessageBatchMaxSize 返个参数,默认是 1,即一次只消费一条消息,例如设置为 N,那么每次消费的消息数小于等于N。
3. 跳过非重要消息
发生消息堆积时,如果消费速度一直追不上发送速度,如果业务对数据要求不高的话,可以选择丢弃不重要的消息。例如,当某个队列的消息数堆积到100000条以上,则尝试丢弃部分或全部消息,这样就可以快速追上发送消息的速度。
4.优化每条消息消费过程
举例如下,某条消息的消费过程如下:
- 根据消息从 DB 查询【数据 1】
- 根据消息从 DB 查询【数据 2】
- 复杂的业务计算
- 向 DB 插入【数据 3】
- 向 DB 插入【数据 4】
这条消息的消费过程中有4次与 DB的 交互,如果按照每次 5ms 计算,那么总共耗时 20ms,假设业务计算耗时 5ms,那么总过耗时 25ms,所以如果能把 4 次 DB 交互优化为 2 次,那么总耗时就可以优化到 15ms,即总体性能提高了 40%。所以应用如果对时延敏感的话,可以把DB部署在SSD硬盘,相比于SCSI磁盘,前者的RT会小很多。
Consumer消息消费的位点的理解
consumeFromWhere、consumeTimestamp
当建立一个新的消费者组时,需要决定是否需要消费已经存在于 Broker 中的历史消息
- CONSUME_FROM_LAST_OFFSET 将会忽略历史消息,并消费之后生成的任何消息。
- CONSUME_FROM_FIRST_OFFSET 将会消费每个存在于 Broker 中的信息。
- CONSUME_FROM_TIMESTAMP 来消费在指定时间戳后产生的消息。
强顺序消息的应对手段
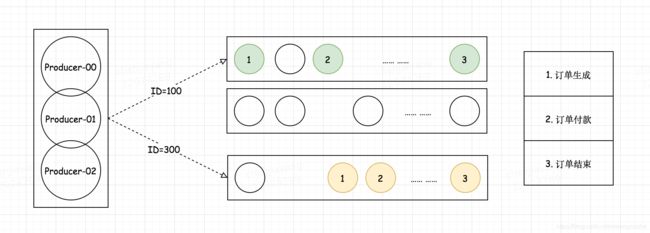
-
Provider中配置MessageQueueSelector,通过ID Hash到一个确定的队列,不过只能保障同一ID的局部有序
-
如果需要强有序,则只能有一个MessageQueue,不过一般可以通过业务层面优化转化为第一种
-
消费端保证消费的顺序性。首先对于一个ConsumerQueue一定只有一个Consumer可以消费,其次在Consumer内部,控制只有一个线程单线程消费,如果多线程可能会异常。
消费者使用 ThreadPoolExecutor 在内部对消息进行消费,所以你可以通过设置 setConsumeThreadMin 或 setConsumeThreadMax 来改变它。
RocketMQ消息磁盘满了怎么办
RocketMQ顺序写CommitLog文件、ComsumeQueue文件,所有的写操作都会落到最后一个文件上,因此在当前写文件之前的文件将不会有数据插入,也就不会有任何变动,因此可通过时间来做判断,比如超过72小时未更新的文件将会被删除。CommitLog默认大小为1M,超过会自动切换下一个文件。队列先进先出的特性,最早进入队列的一定会最早消费,当消息始终不能被成功消费,会进入死信队列,不存在消息一直不能被消费情况,最早的文件会过期成立。
根据每天产生文件的数量、broker的磁盘空间大小配置CommitLog文件大小,实现3天可以写满并消费完一个文件。
自动清理机制
消息存储在CommitLog之后,RocketMQ有自动清理机制,清理只会在以下任一条件成立才会批量删除消息文件(CommitLog):
- 消息文件过期(默认72小时),且到达清理时点(默认是凌晨4点),删除过期文件。
- 消息文件过期(默认72小时),且磁盘空间达到了水位线(默认75%),删除过期文件。
- 磁盘已经达到必须释放的上限(85%水位线)的时候,则开始批量清理文件(无论是否过期),直到空间充足。
注:若磁盘空间达到危险水位线(默认90%),出于保护自身的目的,broker会拒绝写入服务。
当被删除的文件存在引用时,会有一个文件删除缓存时间,在这段时间内,该文件不会被删除,主要是留给引用该文件程序一些时间,当超过了文件删除缓存时间后,每次都会将该文件的引用减少1000,直到减少小于等于0后才释放该文件引用的相关资源,然后将该文件放入一个“文件删除集合”中
注意:过期消息会被清理,意味着消息MQ不是一个持久化消息组件
Client端MQ的优雅停机问题
// 关闭消费者时等待消息消耗的最大时间,0表示没有等待。
awaitTerminationMillisWhenShutdown = 0;
DefaultMQPushConsumerImpl提供shutdown方法可以实现优雅停止,停止成功会打印the consumer [{}] shutdown OK,经测试shutdown方法未被执行,因此需要增加如下方法:
// 注册线程停止钩子
Runtime.getRuntime().addShutdownHook(new Thread(consumer::shutdown));
当broker重启,consumer会有什么影响
没什么影响,consumer发现broker不可用,会负载均衡使用另外的broker
待研究
Consumer在Push模式下,流控策略
默认的流控是基于队列进行,Topic层面无限制,也可以基于Topic进一步限制,当topic参数配置后,pullThresholdForQueue或pullThresholdSizeForQueue会被覆盖
// 在队列级别上的流控制阈值,每个消息队列默认最多缓存1000条消息,
pullThresholdForQueue = 1000;
// 在队列级别上限制缓存的消息大小,每个消息队列默认最多缓存100 MiB消息,
pullThresholdSizeForQueue = 100;
// Topic级流量控制阀值,默认值-1(无限制)
pullThresholdForTopic = -1;
// 在Topic级别限制缓存的消息大小,默认值为-1 MiB(无限制)
pullThresholdSizeForTopic = -1;
Consumer的批量消费
// 最大消费数量
consumeMessageBatchMaxSize = 1;
// 批量拉大小
pullBatchSize = 32;