Keras:我的第一个LSTM二分类网络模型
目标
使用Keras训练一个简单的LSTM二分类网络模型,用于找到数列中是否包含3个连续递增或者递减的子数列。比如 [ 0.1, 0.2, 0.3, 0.5, 0.3, 0.2 ] 数列对应的标签为[ 0, 0, 1, 1 , 0, 1 ]。
特征
设 [x1, x2, x3]中x3的特征为: [ x3, x2, x2 > x1 ? 1 : 0 ]。即数列中的当前数据与前一个数据,以前前一个数据的状态(前一个数据递增状态为1,递减状态为0)。
数据生成
数据生成代码如下所示:
import pandas as pd
import numpy as np
from random import random
from keras.models import Sequential
from keras.preprocessing.sequence import pad_sequences
from keras.layers import Dense, Dropout, LSTM, Embedding
def loadDataRandom(len):
X = []
Y = []
prev = 0
cur = 0
prevState = 0
for i in range(len):
prev = cur
cur = random()
curState = 0
if cur > prev:
curState = 1
else:
curState = 0
y = 0
if curState == prevState:
y = 1
X.append([cur, prev, prevState])
Y.append(y)
# print(cur, prev, curState, prevState, y)
prevState = curState
return np.array(X), np.array(Y)
模型
构建的训练模型如下代码所示,其中:
def create_model(input_length):
model = Sequential()
model.add(LSTM(units=50, activation='relu', return_sequences=True, input_shape=(input_length, 1)))
model.add(Dropout(0.2))
model.add(LSTM(units=50, activation='relu', return_sequences=False))
model.add(Dropout(0.2))
model.add(Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
model.summary()
return model
- 模型使用两个LSTM()与Dropout()层串联。
- 如果LSTM层后面还有LSTM层,则return_sequences参数为True, 否则为False。
- 模型最后的Dense()全连接层的激活函数为’sigmoid’。
- 模型使用’binary_crossentropy’二分类损失函数。
- 模型使用’adam’梯度下降算法。
训练
模型训练代码如下所示:
X_train, y_train = loadDataRandom(1000)
X_train = X_train.reshape((X_train.shape[0], X_train.shape[1], 1))
print(X_train.shape, y_train.shape)
model = create_model(len(X_train[0]))
hist = model.fit(X_train, y_train, batch_size=64, validation_split = 0.2, epochs=200, shuffle=False, verbose=1)
pyplot.plot(hist.history['loss'], label='loss')
pyplot.plot(hist.history['accuracy'], label='acc')
pyplot.plot(hist.history['val_accuracy'], label='val_acc')
pyplot.legend()
pyplot.show()
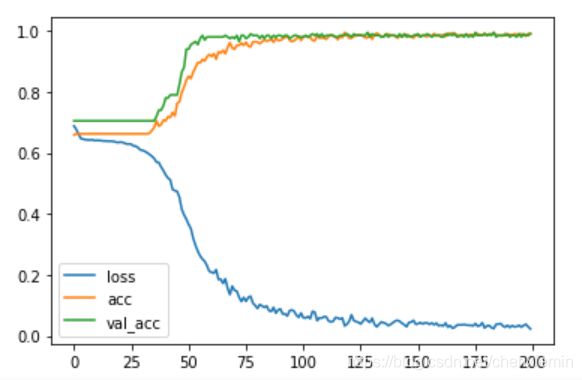
- validation_split参数将X_train数据集拆分成 8:2的训练集与测试集。
- create_model(len)接受的参数len为特征的数量,本例中len=3。
验证
模型的验证代码如下图所示,最后的结果y_val与yVal几乎相同。
X_val, y_val = loadDataRandom(10)
X_val = X_val.reshape((X_val.shape[0], X_val.shape[1], 1))
yVal = model.predict(X_val, verbose=0)
print(X_val, y_val, yVal)
[output]
y_val:
[0 0 0 0 1 0 0 1 0 1]
yVal:
[[0.0000000e+00]
[5.0663948e-07]
[1.6391277e-06]
[2.9802322e-08]
[9.9996734e-01]
[0.0000000e+00]
[3.5762787e-07]
[9.9998260e-01]
[0.0000000e+00]
[9.9592280e-01]]
总结
- 如果说,这个例子不太恰当,用if…else…去判断更合适,好吧,我同意。
- 如果将特诊集合改为[ x3, x2,x1 ]也是可以的。最后的特征没有使用x1,是为了突出LSTM的“状态”属性。
- 将特征集合改成[ x3, x2 ]发现accuracy停留再 0.8左右不再上升,感觉完全依赖LSTM()模型中存储的“状态”似乎不是很靠谱。如有大神有办法在[x3, x2]特征下可以训练出好的结果,望不吝赐教。