深度解说Dropout之《Dropout: A Simple Way to Prevent Neural Networks from Overfitting》读后总结
深度解说Dropout之《Dropout: A Simple Way to Prevent Neural Networks from Overfitting》读后总结
- 前言
- 文章主要内容与贡献
- 详细解释了Dropout
- Dropout神经网络模型描述
- 利用对Dropout进行了深入的说明
- 对特征的影响
- 对稀疏性的影响
- Dropout的丢失率的影响
- 数据集大小的影响
- 将Dropout应用于线性回归(Linear Regression)
- 做了许多的实验来验证Dropout的有效性
- MNIST
- 街景房屋编号数据集(Street View House Numbers data set,SVHN)
- CIAR-10和CIFAR-100
- ImageNet
- Timit
- Reuters-RCV1
- 替代剪接数据集(Alternative Splicing data set)
前言
这是一些对于论文《Dropout: A Simple Way to Prevent Neural Networks from Overfitting》的简单的读后总结,首先先奉上该文章的下载超链接:Dropout
这篇文章是由多伦多计算机科学大学学系(Department of Computer Science, University of Toronto)的人员合作完成的,作者分别是Nitish Srivastava、Geoffrey Hinton、Alex Krizhevsky、Ilya Sutskever和Ruslan Salakhutdinov,编辑是Yoshua Bengio。可以发现其中集结了许多大神,例如2018年图灵奖获得者、深度学习创始人的Geoffrey Hinton,ALexNet的发明者Alex Krizhevsky,2018年图灵奖获得者Yoshua Bengio。
Dropout出现于大众的视野中始于2012年的ALexNet,该文章同样是由Geoffrey Hinton的团队所写的论文, 第一作者是Alex Krizhevsky。本博文此次所要解读的论文则是于2014年Geoffrey Hinton的团队专门为Dropout所写的一篇论文,这篇论文有30页,远比当初7页的ALexNet要长,从这就可以知道这篇论文对Dropout进行了非常详细的解读,同时做了非常多的实验来对其进行验证。Dropout这个方法进入了大众的视野后就一直被大众所喜爱,大部分网络中都运用了Dropout来防止网络过拟合,并且效果都很好。
文章主要内容与贡献
该文章的贡献为:
- 详细解释了Dropout;
- 对Dropout进行了泛化的说明;
- 做了许多的实验来验证Dropout的有效性。
详细解释了Dropout
下图是有无Dropout的网络的区别:

其中,图(a)是标准神经网络,图(b)是应用了Dropout的神经网络。由上可知,Dropout简化了神经网络。将Dropout应用到神经网络中,就等于从神经网络中抽取一个“变薄”的网络。变薄的网络由从Dropout中幸存下来的所有单元组成(图(b))。具有 n n n个单元的神经网络可以被看作是 2 n 2^n 2n个可能的稀疏神经网络的集合。这些网络都共享权重,使得参数的总数仍然是 O ( n 2 ) O(n^2) O(n2)或更小。对于每个训练案例的每次表示,采样和训练一个新的稀疏网络。因此,带Dropout的神经网络训练可以看作是训练一组具有广泛的权重分担的 2 n 2^n 2n个变薄的网络,其中每个细化的网络被训练得非常少。
在测试时,不可能显式地将预测从指数级的许多稀疏模型中平均下来。该文章使用了一种非常简单的近似平均方法,其在实际应用中效果很好,即在测试时使用一个不加Dropout的神经网络即可。训练和测试时的权重应为下图所示:

在测试时权重需要乘以丢失率 p p p,如此可以确保输出的数值范围与训练时一致。通过这种缩放,可以将具有共享权重的 2 n 2^n 2n个网络组合成一个单独的神经网络,以便在测试时使用。
Dropout神经网络模型描述
考虑一个有L个隐藏层的神经网络, l ∈ { 1 , … , L } l\in\{1,\dots,L\} l∈{1,…,L},设 z ( l ) z^{(l)} z(l)是第 l l l层的输入向量, y ( l ) y^{(l)} y(l)是第 l l l层的输出向量,其中 y ( 0 ) = x y^{(0)}=x y(0)=x是网络的输入向量。 W ( l ) W^{(l)} W(l)是第 l l l层的权重, b ( l ) b^{(l)} b(l)是第 l l l层的偏置。标准神经网络的前馈运算如下图(a)所示,带Dropout的神经网络前馈运算如下图(b)所示:

l ∈ { 1 , … , L − 1 } l\in\{1,\dots,L-1\} l∈{1,…,L−1}是,任意隐藏单元 i i i的标准神经网络的前馈运算的方程如下所示:

其中,f是任意激活函数,例如ReLU。
带Dropout的神经网络前馈运算的方程如下所示:

其中, ∗ * ∗是元素级乘法,对任意层 l l l, r ( l ) r^{(l)} r(l)是一个独立Bernoulli随机变量的向量,每个变量的概率p为1。此举相当于从大的网络中取样子网络,反向传播时则是做的当前子网络的反向传播。在测试时,权重被缩放为 W test ( L ) = p W ( L ) W^{(L)}_\text{test}=pW^{(L)} Wtest(L)=pW(L)。通常来说会在反向传播时限制 ∣ ∣ w ∣ ∣ 2 ≤ c ||w||_2\le{c} ∣∣w∣∣2≤c,此时c通常取 2 , 3 , 4 2,3,4 2,3,4,此举可以限制权重的大小,即最大范数正则化(max-norm regularization)。
采用Dropout后可适当增加学习率。
利用对Dropout进行了深入的说明
对特征的影响
在MNIST上学习到的特性,它有一个隐藏层自动编码器,有256个校正线性单元,如下图所示:
其中,图(a)是没有Dropout的神经网络提取的特征,图(b)是丢失率 p = 0.5 p=0.5 p=0.5时的带Dropout的神经网络提取的特征。由上图可知,Dropout破坏了隐藏层单元之间的协同适应性,使得带Dropout的神经网络提取的特征更明确,增加了模型的泛化能力。
对稀疏性的影响
下图中的两个模型使用的都是ReLU,

其中,图(a)是没有Dropout的神经网络提取的特征,图(b)是丢失率 p = 0.5 p=0.5 p=0.5时的带Dropout的神经网络提取的特征。由上图可知,Dropout使得网络中只有极少数单位具有较高的激活能力。
Dropout的丢失率的影响
Dropout有一个可调的超参数p(在网络中保留一个单元的概率)。比较是在两种情况下进行的。
- 隐藏单位的数量保持不变。
- 隐藏单元的数量被更改,以便在Dropout后保留的隐藏单元的预期数量保持不变。
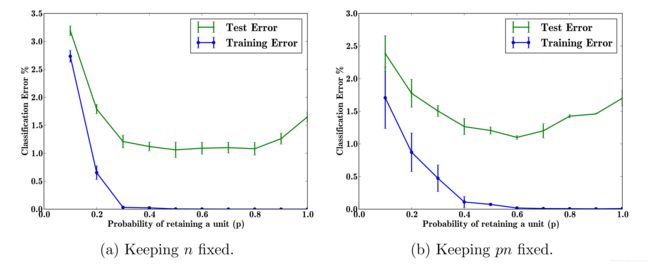
其中,图(a)是第一种情况,在第一种情况下,使用不同数量的辍学来训练相同的网络架构。网络结构为784-2048-2048-2048-10。没有在输入时使用Dropout。由图可知,随着p的增加,测试误差先降后升,在 p ∈ [ 0.4 , 0.8 ] p\in[0.4,0.8] p∈[0.4,0.8]时效果最好。
图(b)是第二种情况,此时 p n pn pn保持不变,因此p越大,n越小,反之亦然。由该图可知,随着p的增加,测试误差先降后升,在 p = 0.6 p=0.6 p=0.6时效果最好。
数据集大小的影响
一个好的正则化器应该能在小数据集上训练大量参数的模型获得良好的泛化误差。下图是在MNIST数据集上进行训练得到的结果:

其中,实验从MNIST训练集中随机选取100、500、1K、5K、10K和50K的数据集。所有数据集的网络结构皆为784-1024-1024-2048-10。Dropout的丢失率为0.5。由上图可知,在小数据集(100,500)上,Dropout并没有改善性能,数据量变大时,Dropout就有了明显的改善网络的效果,但数据量过大是Dropout对网络的改进并不明显。
将Dropout应用于线性回归(Linear Regression)
此处位于文章的第22页,第9章,由于不是重点就不多说,简而言之,原始的模型如下所示:
![]()
加入了Dropout后,变为如下所示:
![]()
其中,R是一个随机Bernoulli矩阵, ∗ * ∗是逐元素相乘。
可以简化为:
![]()
其中,
![]()
采用Dropout的线性回归和特定的岭回归是等价的。将p和w结合,可化为:
![]()
此时的p相当于2范数的正则化参数。
做了许多的实验来验证Dropout的有效性
该文章针对不同领域数据集的分类问题,训练了Dropout神经网络,与不使用Dropout的神经网络相比,Dropout提高了所有数据集的泛化性能。下表简要描述了数据集:

数据集是:
- MNIST:一组手写体数字的标准数据集。
- Timit:用于语音清洗识别的标准语音基准。
- CIAR-10和CIFAR-100:微小的自然图像。
- 街景房屋编号数据集(Street View House Numbers data set,SVHN):谷歌街景收集的房屋号码图片。
- ImageNet:大量自然图像的集合。
- Reuters-RCV1:路透社新闻报道集。
- 替代剪接数据集(Alternative Splicing data set):预测替代基因剪接的RNA特征。
MNIST
在MNIST上的实验结果如下:
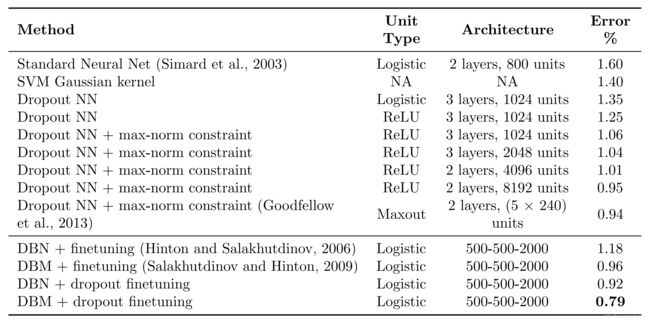
由上表可知,使用Dropout的神经网络有明显的性能优势。
下图表明了,使用Dropout的神经网络误差降低得更多且最终能更低。

下表是不同正则化方法在MNIST上的比较:

由上表可知,最优的组合为Dropout+Max-norm。
街景房屋编号数据集(Street View House Numbers data set,SVHN)
部分实验图片如下所示:

实验结果如下所示:

由上表可知,使用Dropout的神经网络有明显的提升了性能。
CIAR-10和CIFAR-100
部分实验图片如下所示:
实验结果如下所示:

由上表可知,使用Dropout的神经网络有明显的提升了性能。
ImageNet
部分预测结果如下所示:

由上可知,在能预测正确的情况下,几乎是100%的确定结果的,在top-1不能预测正确的情况下,正确结果也会出现在top-5中。
下表是在ILSVRC-2010测试集上的结果:

下表是在ILSVRC2012验证/测试集的结果:

由以上两表可知,使用Dropout的神经网络有明显的提升了性能。
Timit
下表是TIMIT核心测试集上的电话错误率:

由上表可知,使用Dropout的神经网络有明显的提升了性能。
Reuters-RCV1
该文章作者的最佳神经网络不使用Dropout,误差率为31.05%。增加Dropout后,将误差降低到29.62%。与图像和语音数据集相比,在文字数据集上的改进要小得多。
替代剪接数据集(Alternative Splicing data set)
下表是选择拼接数据集的结果:
其中,编码质量(Code Quality)越大越好,此处带Dropout的神经网络仅次于贝叶斯神经网络。