在Centos7上搭建Hadoop集群(二)
Hadoop环境准备完成后(即centos7上配置完jdk,并且解决相关影响因素后),进行Hadoop集群环境的搭建,使用java version "1.8.0_40" , hadoop-2.7.3版本进行相关环境的配置。
关于内部配置文件出现格式错乱的可以看我博客:在centos7搭建hadoop集群二 (使用csdn编辑器有点不熟练,所以还请谅解)
[上传hadoop,并解压]
使用Xftp在 第一台台服务器 /user/local/hadoop/ 路径下上传 hadoop-2.7.3.tar.gz (没有hadoop文件夹就创建一个),之后进行解压,先 su root 使用超级用户身份,(后边的hadoop配置完后会拷贝到另外两台)
名令: tar -zxvf hadoop-2.7.3.tar.gz
解压后使用 rm -f hadoop-2.7.3.tar.gz 删除多余的安装包减少空间

[配置hosts文件]
-
查看并更改服务器用户名:
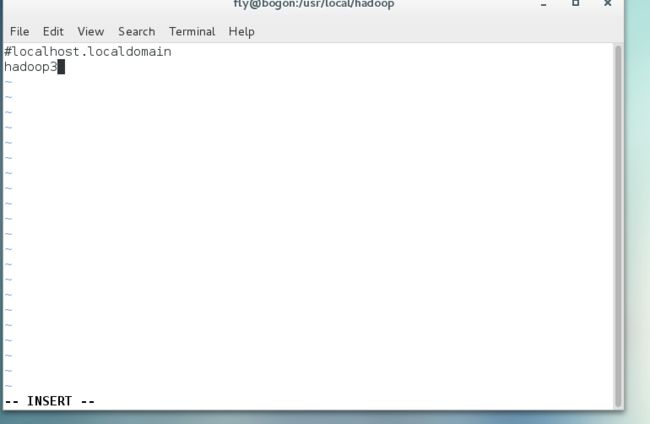
使用hostname,可以看到三台服务器都是bogon或是其他,但三台服务器名都一样,这是因为其与两台是克隆过去的,因此未来方便我们将三台服务分别命名为 Master,hadoop1,hadoop2,命名方法: vi /etc/hostname
查看ip: 名令: ifconfig
服务器名 Master hadoop1 hadoop2 ip地址 192.168.63.221 192.168.63.222 192.168.63.223 -
修改/etc/hosts文件:
文件后边添加:
192.168.63.221 Master
192.168.63.222 hadoop1
192.168.63.223 hadoop2
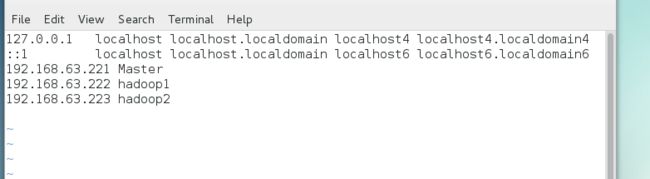
三台服务器都需要更改,目的是为了添加映射
-
测试,三台机子互ping:
特别说明,我们在上篇文章中三台可以互ping通的原因是三台服务器是一样的,我们更改服务器名字后,就发生了改变。因此需要为三台机子添加映射。
[配置Hadoop]
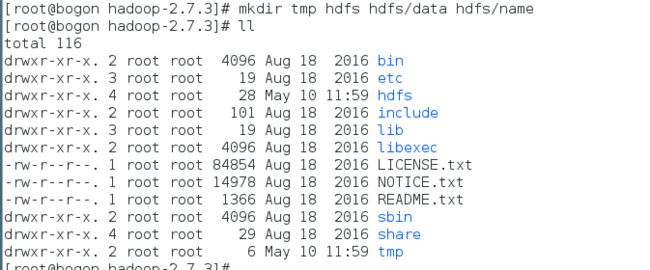
在hadoop-2.7.3目录下创建四个目录:tmp、hdfs、hdfs/data、hdfs/name
配置hadoop集群是需要在每一台服务器上都配置,这里我们只在主服务器上完成配置,配置完成之后我们将配置好的hadoop复制到其他服务器即可。
第一台服务器即 Master我们称为主服务器
配置hadoop 中的所有步骤均在主服务器上操作。
可以使用mkdir命令来创建目录。后面我们配置hadoop的时候会用到这些目录,三个目录的作用如下:
tmp目录用来存储hadoop的临时文件,
hdfs/data目录用来存储hdfs的文件块
hdfs/name目录用来存储元数据信息
创建成功后配置core-site.xml文件
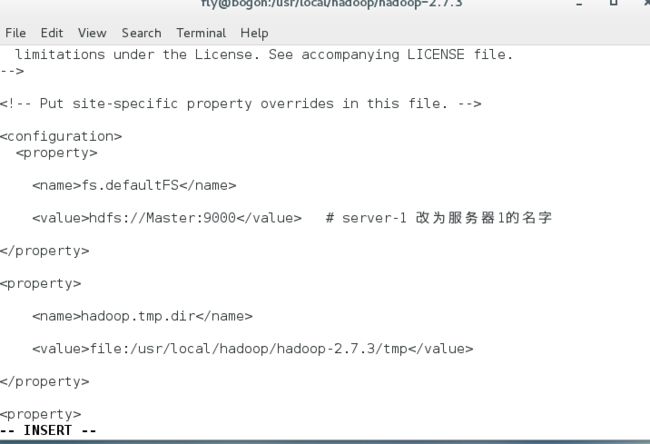
进入hadoop-2.7.3目录下的etc/hadoop目录下,修改core-site.xml文件,在配置中增加如下配置项,在
fs.defaultFS :远程访问hdfs系统文件的方式,一般使用hdfs://
hadoop.tmp.dir:hadoop临时目录,使用我们之前创建的tmp目录,格式file:
添加代码:
fs.defaultFS
hdfs://server-1:9000 # server-1 改为服务器1的名字
hadoop.tmp.dir
file:/usr/local/zhitu/hadoop-2.7.3/tmp
io.file.buffer.size 131702
如图:
[配置hdfs-site.xml文件]
进入hadoop-2.7.3目录下的etc/hadoop目录下,修改hdfs-site.xml文件,该文件主要是hdfs系统的相关配置,在配置中增加如下配置项:
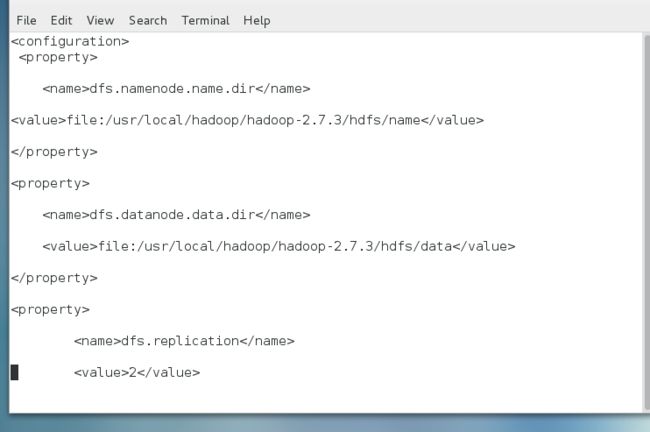
dfs.namenode.name.dir :使用之前我们创建的hdfs/name目录
dfs.datanode.data.dir:使用之前我们创建的hdfs/data目录
dfs.replication: 文件保存的副本数
dfs.namenode.secondary.http-address:http访问hdfs系统的地址(一般使用服务器名称)和端口
dfs.webhdfs.enabled:是否开启web访问hdfs系统。设置为true可以让外部系统使用http协议访问hdfs系统。
参考配置如下:Master为NameNode服务器名称(请根据现场实际情况配置)。
dfs.namenode.name.dirfile:/usr/local/zhitu/hadoop-2.7.3/hdfs/name dfs.datanode.data.dir file:/usr/local/zhitu/hadoop-2.7.3/hdfs/data dfs.replication 2 dfs.namenode.secondary.http-address server-1:9001dfs.webhdfs.enabledtrue
如图:
[配置mapred-site.xml文件]
mappred.xml文件中主要配置mapreduce相关的配置。
进入hadoop-2.7.3目录下的etc/hadoop目录下,将文件mapred-site.xml.template使用mv命令重命名为mapred-site.xml,并修改该文件增加如下配置项:
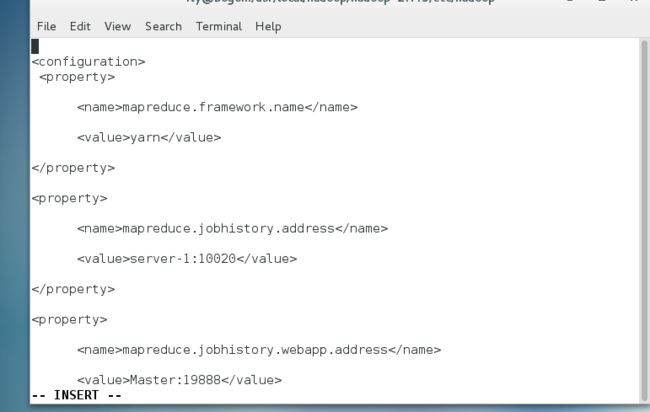
mapreduce.framework.name :运行mapreduce使用的框架,2.0以上的都是用的yarn
mapreduce.jobhistory.address:历史服务器的地址
mapreduce.jobhistory.webapp.address: 历史服务器的web访问地址
先用mv改名: mv mapred-site.xml.template mapred-site.xml
参考配置如下:Master为NameNode服务器名称(请根据现场实际情况配置)。
mapreduce.framework.name yarn mapreduce.jobhistory.address server-1:10020 mapreduce.jobhistory.webapp.address server-1:19888
如图:
[配置yarn-site.xml文件]
yarn-site.xml文件中主要配置yarn框架相关的配置。
进入hadoop-2.7.3目录下的etc/hadoop目录下,修改yarn-site.xml文件,增加如下配置项:
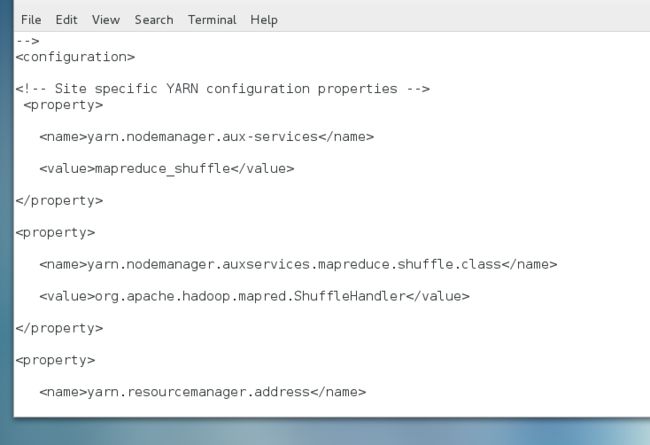
yarn.nodemanager.aux-services:NodeManager上运行的附属服务。需配置成mapreduce_shuffle,才可运行MapReduce程序
yarn.nodemanager.auxservices.mapreduce.shuffle.class:mapreduce执行shuffle使用的class
yarn.resourcemanager.address:resourceManager的地址,客户端通过该地址向RM提交应用程序,杀死应用程序等
yarn.resourcemanager.scheduler.address:ResourceManager 对ApplicationMaster暴露的访问地址。ApplicationMaster通过该地址向RM申请资源、释放资源
yarn.resourcemanager.resource-tracker.address: ResourceManager 对NodeManager暴露的地址.。NodeManager通过该地址向RM汇报心跳,领取任务等
yarn.resourcemanager.admin.address:ResourceManager 对管理员暴露的访问地址。管理员通过该地址向RM发送管理命令。
yarn.resourcemanager.webapp.address:ResourceManager对外web ui地址。用户可通过该地址在浏览器中查看yarn框架中运行的任务状态
yarn.nodemanager.resource.memory-mb:NodeManager运行所需要的内存,单位MB。
参考配置如下:Master为NameNode服务器名称(请根据现场实际情况配置)。
yarn.nodemanager.aux-services mapreduce_shuffle yarn.nodemanager.auxservices.mapreduce.shuffle.class org.apache.hadoop.mapred.ShuffleHandler yarn.resourcemanager.address server-1:8032 yarn.resourcemanager.scheduler.address server-1:8030 yarn.resourcemanager.resource-tracker.address server-1:8031 yarn.resourcemanager.admin.address server-1:8033 yarn.resourcemanager.webapp.address server-1:8088 yarn.nodemanager.resource.memory-mb 1536
如图:
[修改slaves,增加从服务器]
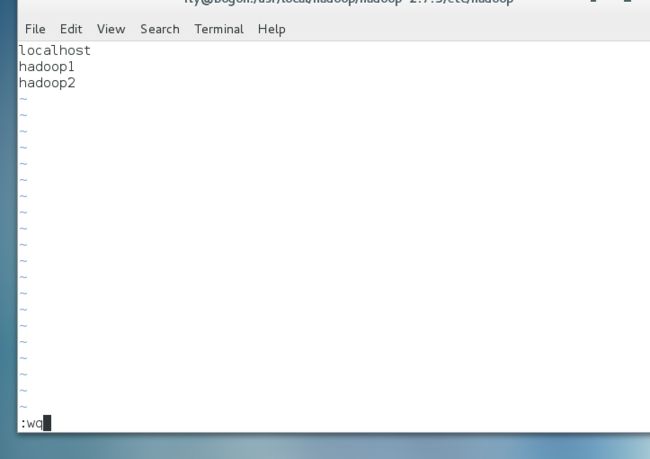
进入hadoop-2.7.3目录下的etc/hadoop目录下,修改slaves文件,将其中的localhost去掉,并所有的从服务器名称添加进去,每台服务器名称占一行。
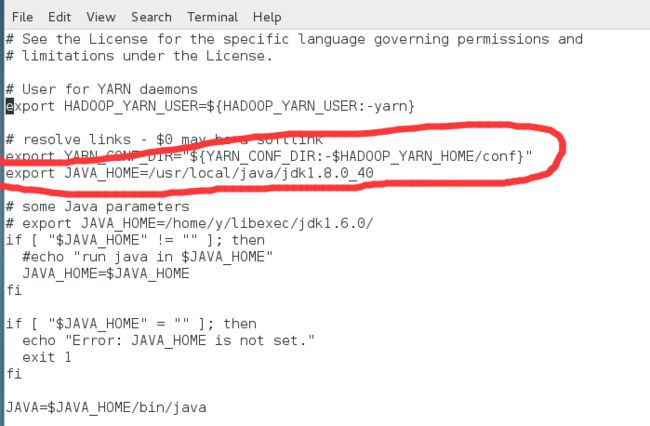
[配置hadoop-env.sh、yarn-env.sh的JAVA_HOME]
进入hadoop-2.7.3目录下的etc/hadoop目录下,修改hadoop-env.sh、yarn-env.sh 两个文件,增加JAVA_HOME的环境变量配置。查看jdk目录可使用命令echo $JAVA_HOME。
hadoop-env.sh:

yarn-env.sh:
[配置主服务器免登录访问从服务器]
-
为每个节点分别产生公、私密钥配置
以下操作我们选取namenode服务器Master作为示例,成功之后,也在另外两台服务器上执行相同的操作!!!
开始之前我们可以先测试下,用ssh命令登录本机或者其他服务器,无论是本机还是其他主机,都是需要输入密码的。

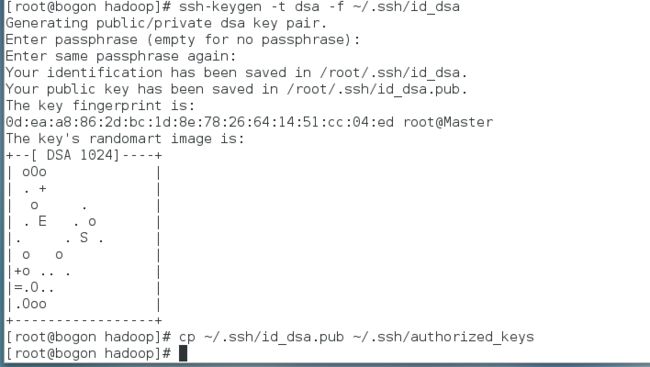
使用ssh-keygen命令可以为本服务器生成公钥(id_dsa.pub)和私钥(Id_dsa),要求输入passphrased的时候直接敲回车。
参考命令:
ssh-keygen -t dsa -f ~/.ssh/id_dsa
再使用cp命令,将公钥文件复制成authorized_keys文件。
参考命令:
cp ~/.ssh/id_dsa.pub ~/.ssh/authorized_keys
此时,在本服务器上生成公钥和私钥的步骤基本完成,使用 ssh 命令登录本机不会再要求输入密码(如果是第一次登录会要求确认是否继续连接)
成功之后,也在另外两台服务器上执行相同的操作!!!
-
让主结点能通过SSH免密码登录两个子结点
将主服务器的公钥文件内容添加到从服务器的authorized_keys文件里,就可以实现主服务器免密码登录从服务器了。
以下操作均在主服务器上执行。
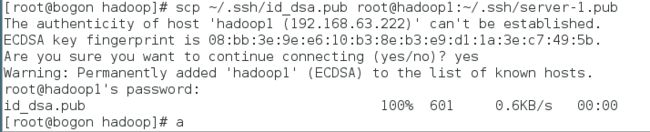
使用scp命令,将主服务器的公钥文件id_dsa.pub复制到从服务器上,并命令为server-1.pub(此文件名可以自己随意起)。
参考命令如下(root为登录从服务器的用户名,hadoop1为从服务器的名称,请根据自己实际情况修改):
scp ~/.ssh/id_dsa.pub root@hadoop1:~/.ssh/server-1.pub
输入此命令后,会要求输入server-2服务器的root账号密码,输入密码即可。
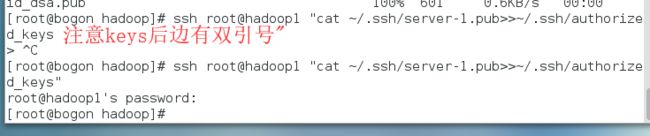
再将上一步生成的server-1.pub文件内容追加到server-2的authorized_keys文件中,可以登录到server-2上去操作,也可以在server-1上使用ssh命令远程操作。这里我们使用ssh命令,在Master上远程操作,参考命令如下(root为登录从服务器的用户名,hadoop1为从服务器的名称,server-1.pub为我们上一步生成的文件,请根据自己实际情况修改):
ssh root@hadoop1 "cat ~/.ssh/server-1.pub>>~/.ssh/authorized_keys"
输入此命令后,会要求输入server-2服务器的root账号密码,输入密码即可。
如果不出问题,此时server-1服务就可以通过SSH免密码访问server-2了。
 成功登录!
成功登录!按照上面的方法,让server-1可以ssh免密码访问另外一台从服务器!!!!
向hadoop2拷贝
[将Hadoop复制到各从服务器]
通过以上步骤我们基本已经配置好了hadoop的集群配置,现在我们需要将我们配置好的文件复制到其他的服务器上。将文件copy到从服务器上的方法有很多,建议使用scp命令。
参考:在主服务器上执行以下两条命令(其中root为登录从服务器的用户名,hadoop1,hadoop2为从服务器的名称,请根据自己实际情况修改):
scp -r /usr/local/hadoop/hadoop-2.7.3/ root@hadoop1:/usr/local/hadoop/
scp -r /usr/local/hadoop/hadoop-2.7.3/ root@hadoop2:/usr/local/hadoop/
[格式化namenode]
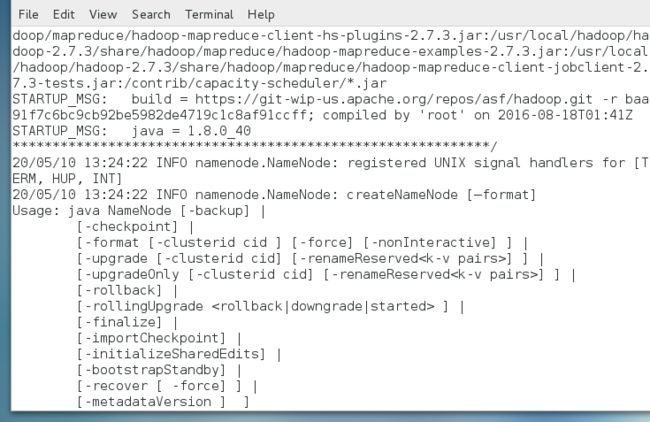
在主服务器上,进入hadoop-2.7.3目录下,格式化namenode。
参考命令:
bin/hdfs namenode –format
[启动Hadoop并验证]
1,启动:
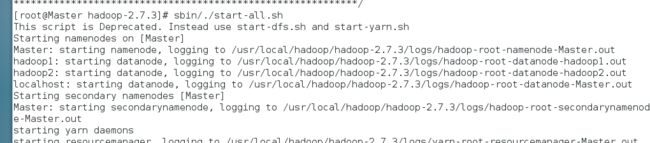
在主服务器上,进入hadoop-2.7.3目录下,启动Hadoop集群。
参考命令:
sbin/./start-all.sh
2,验证:
jps命令为jdk提供的查看java进程的命令,hadoop服务如果启动成功了,可以在主服务器上查看到NameNode ,SecondaryNameNode,ResourceManager 三个服务,从服务器上看到到NodeManager, DataNode 两个服务。
参考命令:
cd /user/local/hadoop/hadoop2.7.3/
jps

启动后发现没有namenode ,额头大![]()
问题解决看下一篇:hadoop启动后没有namenode