基于python的Lasagne包对minist的代码解读
本例是基于python的Lasagne包中对minist数据集的卷积神经网络的代码的一个解读,其中英文部分因为怕自己理解错误,所以保留了下来;由于该部分代码主要还是基于theano进行开发,所以里面的很多函数都是借鉴或直接用了theano中的函数,要想真正理解还是需要学习一下theano,包括其中对于变量和函数设计的理念,其实都是很有意味的!
theano: http://deeplearning.net/software/theano/#
lasagne下载地址 https://github.com/Lasagne/Lasagne
#!/usr/bin/env python
"""
Usage example employing Lasagne for digit recognition using the MNIST dataset.
This example is deliberately structured as a long flat file, focusing on how
to use Lasagne, instead of focusing on writing maximally modular and reusable
code. It is used as the foundation for the introductory Lasagne tutorial:
http://lasagne.readthedocs.org/en/latest/user/tutorial.html
More in-depth examples and reproductions of paper results are maintained in
a separate repository: https://github.com/Lasagne/Recipes
"""
from __future__ import print_function
import sys
import os
import time
import numpy as np
import theano
import theano.tensor as T
import lasagne
# 导入该导入的模块
# ################## Download and prepare the MNIST dataset ##################
# This is just some way of getting the MNIST dataset from an online location
# and loading it into numpy arrays. It doesn't involve Lasagne at all.
def load_dataset():
# We first define a download function, supporting both Python 2 and 3.
if sys.version_info[0] == 2:
from urllib import urlretrieve
else:
from urllib.request import urlretrieve
def download(filename, source='http://yann.lecun.com/exdb/mnist/'):
print("Downloading %s" % filename)
urlretrieve(source + filename, filename)
# We then define functions for loading MNIST images and labels.
# For convenience, they also download the requested files if needed.
import gzip
def load_mnist_images(filename):
if not os.path.exists(filename):
download(filename)
# Read the inputs in Yann LeCun's binary format.
with gzip.open(filename, 'rb') as f:
data = np.frombuffer(f.read(), np.uint8, offset=16)
# The inputs are vectors now, we reshape them to monochrome 2D images,
# following the shape convention: (examples, channels, rows, columns)
data = data.reshape(-1, 1, 28, 28)
# The inputs come as bytes, we convert them to float32 in range [0,1].
# (Actually to range [0, 255/256], for compatibility to the version
# provided at http://deeplearning.net/data/mnist/mnist.pkl.gz.)
return data / np.float32(256)
def load_mnist_labels(filename):
if not os.path.exists(filename):
download(filename)
# Read the labels in Yann LeCun's binary format.
with gzip.open(filename, 'rb') as f:
data = np.frombuffer(f.read(), np.uint8, offset=8)
# The labels are vectors of integers now, that's exactly what we want.
return data
# We can now download and read the training and test set images and labels.
X_train = load_mnist_images('train-images-idx3-ubyte.gz')
y_train = load_mnist_labels('train-labels-idx1-ubyte.gz')
X_test = load_mnist_images('t10k-images-idx3-ubyte.gz')
y_test = load_mnist_labels('t10k-labels-idx1-ubyte.gz')
# We reserve the last 10000 training examples for validation.
X_train, X_val = X_train[:-10000], X_train[-10000:]
y_train, y_val = y_train[:-10000], y_train[-10000:]
# We just return all the arrays in order, as expected in main().
# (It doesn't matter how we do this as long as we can read them again.)
return X_train, y_train, X_val, y_val, X_test, y_test
# 读取数据集,该处使用前10000维作为训练,后10000维作为验证集
# ##################### Build the neural network model #######################
# This script supports three types of models. For each one, we define a
# function that takes a Theano variable representing the input and returns
# the output layer of a neural network model built in Lasagne.
#下面定义了三种网络结构:多层感知机、自定义多层感知机、卷积神经网络
def build_mlp(input_var=None):
# 定义了含有800个元件的两个隐含层,一个10个元件的softmax,输入层dropout为0.2,
# 隐含层为0.5;
# 输入层的shape中:
# None表示batch size是可以变的,没有被特别指定;
# 接下来三个参数为输入数据维度,然后dropout掉0.2
# 隐藏层使用神经元max(0,x);输出层为softmax
# This creates an MLP of two hidden layers of 800 units each, followed by
# a softmax output layer of 10 units. It applies 20% dropout to the input
# data and 50% dropout to the hidden layers.
# Input layer, specifying the expected input shape of the network
# (unspecified batchsize, 1 channel, 28 rows and 28 columns) and
# linking it to the given Theano variable `input_var`, if any:
l_in = lasagne.layers.InputLayer(shape=(None, 1, 28, 28),
input_var=input_var)
# Apply 20% dropout to the input data:
l_in_drop = lasagne.layers.DropoutLayer(l_in, p=0.2)
# Add a fully-connected layer of 800 units, using the linear rectifier, and
# initializing weights with Glorot's scheme (which is the default anyway):
l_hid1 = lasagne.layers.DenseLayer(
l_in_drop, num_units=800,
nonlinearity=lasagne.nonlinearities.rectify,
W=lasagne.init.GlorotUniform())
#
# We'll now add dropout of 50%:
l_hid1_drop = lasagne.layers.DropoutLayer(l_hid1, p=0.5)
# Another 800-unit layer:
l_hid2 = lasagne.layers.DenseLayer(
l_hid1_drop, num_units=800,
nonlinearity=lasagne.nonlinearities.rectify)
# 50% dropout again:
l_hid2_drop = lasagne.layers.DropoutLayer(l_hid2, p=0.5)
# Finally, we'll add the fully-connected output layer, of 10 softmax units:
l_out = lasagne.layers.DenseLayer(
l_hid2_drop, num_units=10,
nonlinearity=lasagne.nonlinearities.softmax)
# Each layer is linked to its incoming layer(s), so we only need to pass
# the output layer to give access to a network in Lasagne:
return l_out
def build_custom_mlp(input_var=None, depth=2, width=800, drop_input=.2,
drop_hidden=.5):
# 定义了含有800个元件的两个隐含层,一个10个元件的softmax,输入层dropout为0.2,
# 隐含层为0.5;
# 输入层的shape中:
# None表示batch size是可以变的,没有被特别指定;
# 接下来三个参数为输入数据维度,然后dropout:0.2
# 隐藏层使用线性整流,神经元max(0,x);输出层为softmax
# 该步基本用的都是上面mlp的函数,其中隐含层的层数由depth决定,隐含层每层神经元个数
# 有width决定
# By default, this creates the same network as `build_mlp`, but it can be
# customized with respect to the number and size of hidden layers. This
# mostly showcases how creating a network in Python code can be a lot more
# flexible than a configuration file. Note that to make the code easier,
# all the layers are just called `network` -- there is no need to give them
# different names if all we return is the last one we created anyway; we
# just used different names above for clarity.
# Input layer and dropout (with shortcut `dropout` for `DropoutLayer`):
network = lasagne.layers.InputLayer(shape=(None, 1, 28, 28),
input_var=input_var)
if drop_input:
network = lasagne.layers.dropout(network, p=drop_input)
# Hidden layers and dropout:
nonlin = lasagne.nonlinearities.rectify
for _ in range(depth):
network = lasagne.layers.DenseLayer(
network, width, nonlinearity=nonlin)
if drop_hidden:
network = lasagne.layers.dropout(network, p=drop_hidden)
# Output layer:
softmax = lasagne.nonlinearities.softmax
network = lasagne.layers.DenseLayer(network, 10, nonlinearity=softmax)
return network
def build_cnn(input_var=None):
# 接下来定义了卷积神经网络:
# 输入层跟上面相同
# 卷积层使用32个卷积核,每个大小5x5,依然适用ReLU神经元,W初始化采用GlorotUniform()
# 函数(也就是uniform分布)赋值
# pooling层使用max_pooling的2x2
# 以上两层重复两次,之后接全连接层
# 全连接层依然采用DenseLayer函数定义,神经元用ReLU,采用0.5的dropout,一共用了256个神经元
# 输出层采用softmax,用了10个神经元,我理解为输出的类一共有10个,每一个类都有一个[0,1]的值,
# 代表属于该类的一个概率,
# 最后输出的是一个和为1的向量,同样对于其输入也有0.5的进行dropout
# As a third model, we'll create a CNN of two convolution + pooling stages
# and a fully-connected hidden layer in front of the output layer.
# Input layer, as usual:
network = lasagne.layers.InputLayer(shape=(None, 1, 28, 28),
input_var=input_var)
# This time we do not apply input dropout, as it tends to work less well
# for convolutional layers.
# Convolutional layer with 32 kernels of size 5x5. Strided and padded
# convolutions are supported as well; see the docstring.
network = lasagne.layers.Conv2DLayer(
network, num_filters=32, filter_size=(5, 5),
nonlinearity=lasagne.nonlinearities.rectify,
W=lasagne.init.GlorotUniform())
# Expert note: Lasagne provides alternative convolutional layers that
# override Theano's choice of which implementation to use; for details
# please see http://lasagne.readthedocs.org/en/latest/user/tutorial.html.
# Max-pooling layer of factor 2 in both dimensions:
network = lasagne.layers.MaxPool2DLayer(network, pool_size=(2, 2))
# Another convolution with 32 5x5 kernels, and another 2x2 pooling:
network = lasagne.layers.Conv2DLayer(
network, num_filters=32, filter_size=(5, 5),
nonlinearity=lasagne.nonlinearities.rectify)
network = lasagne.layers.MaxPool2DLayer(network, pool_size=(2, 2))
# A fully-connected layer of 256 units with 50% dropout on its inputs:
network = lasagne.layers.DenseLayer(
lasagne.layers.dropout(network, p=.5),
num_units=256,
nonlinearity=lasagne.nonlinearities.rectify)
# And, finally, the 10-unit output layer with 50% dropout on its inputs:
network = lasagne.layers.DenseLayer(
lasagne.layers.dropout(network, p=.5),
num_units=10,
nonlinearity=lasagne.nonlinearities.softmax)
return network
# ############################# Batch iterator ###############################
# This is just a simple helper function iterating over training data in
# mini-batches of a particular size, optionally in random order. It assumes
# data is available as numpy arrays. For big datasets, you could load numpy
# arrays as memory-mapped files (np.load(..., mmap_mode='r')), or write your
# own custom data iteration function. For small datasets, you can also copy
# them to GPU at once for slightly improved performance. This would involve
# several changes in the main program, though, and is not demonstrated here.
# Notice that this function returns only mini-batches of size `batchsize`.
# If the size of the data is not a multiple of `batchsize`, it will not
# return the last (remaining) mini-batch.
# 对于采用mini_batch进行迭代的过程,需要输入输入数据集,输入数据的标签,batch size的大小,
# 以及是否重新洗牌
# 如果索引将会被打乱,然后按照batch size分批次进行迭代;
def iterate_minibatches(inputs, targets, batchsize, shuffle=False):
assert len(inputs) == len(targets)
if shuffle:
indices = np.arange(len(inputs))
np.random.shuffle(indices)
for start_idx in range(0, len(inputs) - batchsize + 1, batchsize):
if shuffle:
excerpt = indices[start_idx:start_idx + batchsize]
else:
excerpt = slice(start_idx, start_idx + batchsize)
yield inputs[excerpt], targets[excerpt]
# ############################## Main program ################################
# Everything else will be handled in our main program now. We could pull out
# more functions to better separate the code, but it wouldn't make it any
# easier to read.
# 主函数:首先确定模型种类,然后根据种类确定相应的参数mlp没什么好说的,都是上面的参数;自定义
# mlp需要输入深度隐含层个数depth、每一层神经元个数width以及输入层dropout率和隐含层dropout率;
# 个人觉得这里是淘汰率;因为根据Hinton的dropout的文章保留率应该是0.5~1
# 对于cnn也与上面相同通过已经构造出来的网络得到预测值向量prediction,然后计算绝对交叉熵计算损失值,
# coding_list是
# softmax输出结果,而target_list是其结果的标签,即t_{i,j},因此其数学公式为math::
# L_i = - \\sum_j{t_{i,j} \\log(p_{i,j})}
# 取其样本正确结果预测值的对数就是损失值
# 更新权重的方法,本次代码默认采用nesterov_momentum,其中超参learning_rate=0.01, momentum=0.9
# 最后,认为预测值最大值就是其判断值,如果它与真标签一致就返回1,否则返回0,然后算出平均值,就是其准确度
# 如果是训练阶段,抛出损失值进入迭代更新;如果是测试集,就直接输出准确度和损失值
# 进入迭代阶段,本次一共进行500次迭代,首先是训练阶段一共迭代产生500batch,每个batch都要计算损失值,
# 然后迭代更新权重,之后再用500个
# batch进行验证,求出平均准确度并输出;这样进行500次迭代
# 进行完500次训练和验证之后,再产生500个测试集的batch进行测试,输出最后的500个准确度的平均值就是
# Final results
def main(model='mlp', num_epochs=500):
# Load the dataset
print("Loading data...")
X_train, y_train, X_val, y_val, X_test, y_test = load_dataset()
# Prepare Theano variables for inputs and targets
#byte: bscalar, bvector, bmatrix, brow, bcol, btensor3, btensor4
#16-bit integers: wscalar, wvector, wmatrix, wrow, wcol, wtensor3, wtensor4
#32-bit integers: iscalar, ivector, imatrix, irow, icol, itensor3, itensor4
#64-bit integers: lscalar, lvector, lmatrix, lrow, lcol, ltensor3, ltensor4
#float: fscalar, fvector, fmatrix, frow, fcol, ftensor3, ftensor4
#double: dscalar, dvector, dmatrix, drow, dcol, dtensor3, dtensor4
#complex: cscalar, cvector, cmatrix, crow, ccol, ctensor3, ctensor4
# 此处创建了一个以'inputs'为名的四维张量对象和一个以‘targets’为名的dtype=int32的一维向量
input_var = T.tensor4('inputs')
target_var = T.ivector('targets')
# Create neural network model (depending on first command line parameter)
print("Building model and compiling functions...")
if model == 'mlp':
network = build_mlp(input_var)
elif model.startswith('custom_mlp:'):
depth, width, drop_in, drop_hid = model.split(':', 1)[1].split(',')
network = build_custom_mlp(input_var, int(depth), int(width),
float(drop_in), float(drop_hid))
elif model == 'cnn':
network = build_cnn(input_var)
else:
print("Unrecognized model type %r." % model)
return
# Create a loss expression for training, i.e., a scalar objective we want
# to minimize (for our multi-class problem, it is the cross-entropy loss):
prediction = lasagne.layers.get_output(network)
loss = lasagne.objectives.categorical_crossentropy(prediction, target_var)
loss = loss.mean()
# We could add some weight decay as well here, see lasagne.regularization.
# Create update expressions for training, i.e., how to modify the
# parameters at each training step. Here, we'll use Stochastic Gradient
# Descent (SGD) with Nesterov momentum, but Lasagne offers plenty more.
params = lasagne.layers.get_all_params(network, trainable=True)
updates = lasagne.updates.nesterov_momentum(
loss, params, learning_rate=0.01, momentum=0.9)
# Create a loss expression for validation/testing. The crucial difference
# here is that we do a deterministic forward pass through the network,
# disabling dropout layers.
test_prediction = lasagne.layers.get_output(network, deterministic=True)
test_loss = lasagne.objectives.categorical_crossentropy(test_prediction,
target_var)
test_loss = test_loss.mean()
# As a bonus, also create an expression for the classification accuracy:
test_acc = T.mean(T.eq(T.argmax(test_prediction, axis=1), target_var),
dtype=theano.config.floatX)
# Compile a function performing a training step on a mini-batch (by giving
# the updates dictionary) and returning the corresponding training loss:
train_fn = theano.function([input_var, target_var], loss, updates=updates)
# Compile a second function computing the validation loss and accuracy:
val_fn = theano.function([input_var, target_var], [test_loss, test_acc])
# Finally, launch the training loop.
print("Starting training...")
# We iterate over epochs:
for epoch in range(num_epochs):
# In each epoch, we do a full pass over the training data:
train_err = 0
train_batches = 0
start_time = time.time()
for batch in iterate_minibatches(X_train, y_train, 500, shuffle=True):
inputs, targets = batch
train_err += train_fn(inputs, targets)
train_batches += 1
# And a full pass over the validation data:
val_err = 0
val_acc = 0
val_batches = 0
for batch in iterate_minibatches(X_val, y_val, 500, shuffle=False):
inputs, targets = batch
err, acc = val_fn(inputs, targets)
val_err += err
val_acc += acc
val_batches += 1
# Then we print the results for this epoch:
print("Epoch {} of {} took {:.3f}s".format(
epoch + 1, num_epochs, time.time() - start_time))
print(" training loss:\t\t{:.6f}".format(train_err / train_batches))
print(" validation loss:\t\t{:.6f}".format(val_err / val_batches))
print(" validation accuracy:\t\t{:.2f} %".format(
val_acc / val_batches * 100))
# After training, we compute and print the test error:
test_err = 0
test_acc = 0
test_batches = 0
for batch in iterate_minibatches(X_test, y_test, 500, shuffle=False):
inputs, targets = batch
err, acc = val_fn(inputs, targets)
test_err += err
test_acc += acc
test_batches += 1
print("Final results:")
print(" test loss:\t\t\t{:.6f}".format(test_err / test_batches))
print(" test accuracy:\t\t{:.2f} %".format(
test_acc / test_batches * 100))
# Optionally, you could now dump the network weights to a file like this:
# np.savez('model.npz', *lasagne.layers.get_all_param_values(network))
#
# And load them again later on like this:
# with np.load('model.npz') as f:
# param_values = [f['arr_%d' % i] for i in range(len(f.files))]
# lasagne.layers.set_all_param_values(network, param_values)
# 主函数部分是需要接受两个参数,一个是模型,一个是迭代次数,如果model='custom_mlp'需要
# 给出'custom_mlp:DEPTH,WIDTH,DROP_IN,DROP_HID'迭代次数默认500
if __name__ == '__main__':
if ('--help' in sys.argv) or ('-h' in sys.argv):
print("Trains a neural network on MNIST using Lasagne.")
print("Usage: %s [MODEL [EPOCHS]]" % sys.argv[0])
print()
print("MODEL: 'mlp' for a simple Multi-Layer Perceptron (MLP),")
print(" 'custom_mlp:DEPTH,WIDTH,DROP_IN,DROP_HID' for an MLP")
print(" with DEPTH hidden layers of WIDTH units, DROP_IN")
print(" input dropout and DROP_HID hidden dropout,")
print(" 'cnn' for a simple Convolutional Neural Network (CNN).")
print("EPOCHS: number of training epochs to perform (default: 500)")
else:
kwargs = {}
if len(sys.argv) > 1:
kwargs['model'] = sys.argv[1]
if len(sys.argv) > 2:
kwargs['num_epochs'] = int(sys.argv[2])
main(**kwargs)这里解释一下theano 的基本工作原理
Theano Graphs:
写theano代码的第一步就是用symbol来表示所有的数学公式或函数。
这些操作在theano中称为ops.
op :表示的就是一个计算单元。
在Theano内部会把theano的代码表示成图形,组成theano图的基本元件包括:
变量节点 :包括input、output node
操作节点:op nodes
应用节点:apply nodes : 每一个op 会需要有一个apply node,这个op是绑定在这个apply上,通过apply node把op需要的输入和输出以及op本身组合在一起,示意图:
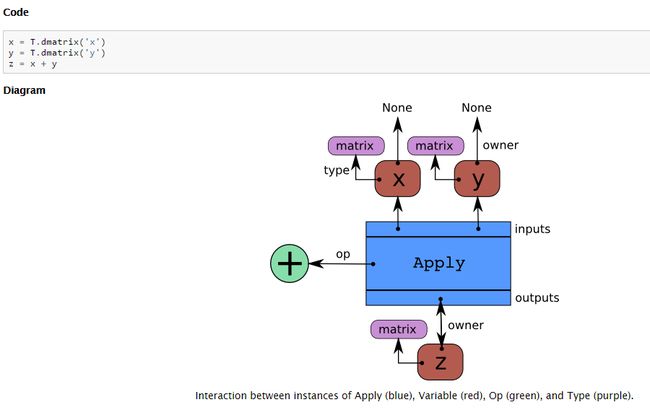
以上关于theano的部分建议看一下:http://blog.sina.com.cn/s/blog_80ce3a550102veyz.html
或者参考论文:http://arxiv.org/pdf/1211.5590v1.pdf