R语言_数据分析及数值分析
文章目录
- 1 自定义R语言函数
- 1.1 pca()---主成分算法
- 1.2 fa()---因子分析算法
- 2 数据简单处理
- 3 主成分分析
- 4 主因子估计法做因子分析
1 自定义R语言函数
1.1 pca()—主成分算法
msa.pca<-function(X,cor=FALSE,m=2,scores=TRUE,ranks=TRUE,sign=TRUE,plot=TRUE){
if(m<1) return
PC=princomp(X,cor=cor)
Vi=PC$sdev^2
Vari=data.frame('Variance'=Vi[1:m],'Proportion'=(Vi/sum(Vi))[1:m],
'Cumulative'=(cumsum(Vi)/sum(Vi))[1:m])
cat("\n")
Loadi=as.matrix(PC$loadings[,1:m])
Compi=as.matrix(PC$scores[,1:m])
if(sign)
for (i in 1:m)
if(sum(Loadi[,i])<0){
Loadi[,i] = -Loadi[,i]
Compi[,i] = -Compi[,i]
}
pca<-NULL
pca$vars=Vari
if(m<=1) pca$loadings = data.frame(Comp1=Loadi)
else pca$loadings = Loadi;
if(scores & !ranks) pca$scores=round(Compi,4)
if(scores & plot){
plot(Compi);abline(h=0,v=0,lty=3)
text(Compi,row.names(X))
# par(mar=c(4,4,2,3))
# biplot(Compi,Loadi); abline(h=0,v=0,lty=3)
# par(mar=c(4,4,1,1))
}
if(scores & ranks){
pca$scores=round(Compi,4)
Wi=Vi[1:m];Wi
Comp=Compi%*%Wi/sum(Wi)
Rank=rank(-Comp)
pca$ranks=data.frame(Comp=round(Comp,4),Rank=Rank)
}
pca
}
1.2 fa()—因子分析算法
fa<-function(X,m=2,scores=TRUE,rotation="varimax",common=TRUE,ranks=TRUE){
if(m<1) return
cat("\n")
S=cor(X);
p<-nrow(S); diag_S<-diag(S); sum_rank<-sum(diag_S)
rowname = names(X)
colname<-paste("Factor", 1:p, sep="")
A<-matrix(0, nrow=p, ncol=p, dimnames=list(rowname, colname))
eig<-eigen(S)
for (i in 1:p)
A[,i]<-sqrt(eig$values[i])*eig$vectors[,i]
for (i in 1:p) { if(sum(A[,i])<0) A[,i] = -A[,i] }
h<-diag(A%*%t(A))
rowname<-c("Variance","Proportion","Cumulative")
B<-matrix(0, nrow=3, ncol=p, dimnames=list(rowname, colname))
for (i in 1:p){
B[1,i]<-sum(A[,i]^2)
B[2,i]<-B[1,i]/sum_rank
B[3,i]<-sum(B[1,1:i])/sum_rank
}
W=B[2,1:m]*100;
Vars=data.frame('Variance'=B[1,],'Proportion'=B[2,]*100,
'Cumulative'=B[3,]*100)
A=A[,1:m]
if(rotation == "varimax" & m>1){
#cat("\n Factor Analysis for Princomp in Varimax: \n\n");
VA=varimax(A); A=VA$loadings;
s2=apply(A^2,2,sum);
k=rank(-s2); s2=s2[k];
W=s2/sum(B[1,])*100;
Vars=data.frame('Variance'=s2,'Proportion'=W,'Cumulative'=cumsum(W))
rownames(Vars) <- paste("Factor", 1:m, sep="")
A=A[,k]
for (i in 1:m) { if(sum(A[,i])<0) A[,i] = -A[,i] }
A=A[,1:m];
colnames(A) <- paste("Factor", 1:m, sep="")
}
fit<-NULL
fit$vars<-round(Vars[1:m,],3)
if(m<=1) fit$loadings <- data.frame("Factor1"=round(A,4))
else fit$loadings <- round(A,4)
if(common){
fit$common <- round(apply(A^2,1,sum),4)
}
Z=as.matrix(scale(X));
PCs=Z%*%solve(S)%*%A
fit$scores <- round(PCs,4)
if(ranks){
W=apply(fit$loadings^2,2,sum)
Wi=W/sum(W);
F=PCs%*%Wi
fit$ranks=data.frame(Factor=round(F,4),Rank=rank(-F))
}
fit
}
2 数据简单处理
> d = read.table("clipboard", header = TRUE)
> cor(d)
食品 衣着 设备 医疗 交通 教育 居住 杂项
食品 1.0000000 0.2569697 0.7252526 0.3853672 0.8990457 0.8284572 0.7145260 0.7218909
衣着 0.2569697 1.0000000 0.4537807 0.5765121 0.3575064 0.5420120 0.4045314 0.6277509
设备 0.7252526 0.4537807 1.0000000 0.5831419 0.7823418 0.8924742 0.7744004 0.7220538
医疗 0.3853672 0.5765121 0.5831419 1.0000000 0.4665789 0.6291140 0.6911234 0.6254195
交通 0.8990457 0.3575064 0.7823418 0.4665789 1.0000000 0.8795439 0.7853531 0.7517683
教育 0.8284572 0.5420120 0.8924742 0.6291140 0.8795439 1.0000000 0.8133081 0.8435436
居住 0.7145260 0.4045314 0.7744004 0.6911234 0.7853531 0.8133081 1.0000000 0.7183218
杂项 0.7218909 0.6277509 0.7220538 0.6254195 0.7517683 0.8435436 0.7183218 1.0000000
3 主成分分析
> PC = pca(X, cor = TRUE)
> PC
$`vars`
Variance Proportion Cumulative
Comp.1 5.701168 0.7126460 0.7126460
Comp.2 1.028668 0.1285835 0.8412295
$loadings
Comp.1 Comp.2
食品 0.3530160 -0.42913372
衣着 0.2494594 0.67707366
设备 0.3738401 -0.08881424
医疗 0.3016294 0.47157654
交通 0.3760539 -0.32423582
教育 0.4040134 -0.06946256
居住 0.3709635 -0.05611496
杂项 0.3743738 0.11849177
$scores
Comp.1 Comp.2
北京 6.1223 1.5225
天津 3.0101 0.5368
河北 -0.8875 0.6923
山西 -1.1037 0.6014
内蒙古 0.5333 1.8477
辽宁 0.0944 0.6552
吉林 -0.3271 1.4247
黑龙江 -1.6886 0.9959
上海 7.0847 -1.0693
江苏 1.1413 -0.4537
浙江 3.8211 0.1721
安徽 -1.1234 -0.3518
福建 1.1717 -1.3776
江西 -1.6694 -0.5485
山东 0.4811 0.8085
河南 -1.2772 0.6479
湖北 -1.0095 -0.1165
湖南 -0.3651 0.2007
广东 4.0320 -2.4805
广西 -1.6274 -1.2306
海南 -1.8731 -2.3528
重庆 0.3940 0.4623
四川 -1.1538 -0.5181
贵州 -2.0140 -0.6595
云南 -2.4295 -0.4178
西藏 -2.7204 -1.0105
陕西 -0.8880 0.1170
甘肃 -1.3245 0.1445
青海 -1.7685 0.2089
宁夏 -1.3173 0.4960
新疆 -1.3181 1.0527
$ranks
Comp Rank
北京 5.4192 2
天津 2.6321 5
河北 -0.6460 14
山西 -0.8431 16
内蒙古 0.7343 8
辽宁 0.1801 11
吉林 -0.0593 12
黑龙江 -1.2783 24
上海 5.8383 1
江苏 0.8975 6
浙江 3.2634 3
安徽 -1.0054 20
福建 0.7820 7
江西 -1.4981 26
山东 0.5311 9
河南 -0.9830 19
湖北 -0.8730 17
湖南 -0.2786 13
广东 3.0365 4
广西 -1.5667 27
海南 -1.9464 29
重庆 0.4045 10
四川 -1.0566 22
贵州 -1.8070 28
云南 -2.1220 30
西藏 -2.4590 31
陕西 -0.7344 15
甘肃 -1.1000 23
青海 -1.4662 25
宁夏 -1.0402 21
新疆 -0.9558 18
#绘图
biplot(PC$scores,PC$loadings)

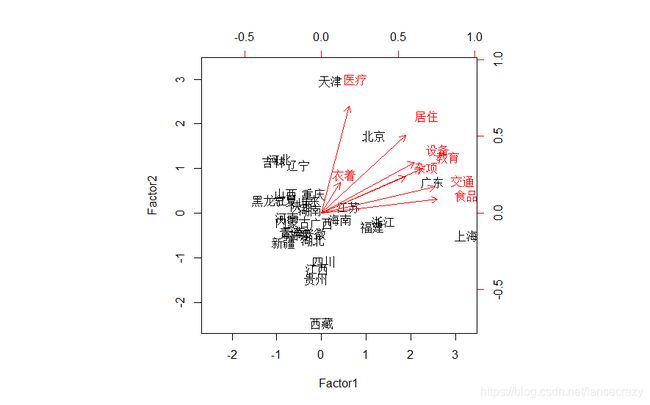
4 主因子估计法做因子分析
fp = fa(d, 3, rotation = 'varimax')
> fp
$`vars`
Variance Proportion Cumulative
Factor1 4.016 50.204 50.204
Factor2 1.680 20.999 71.203
Factor3 1.538 19.224 90.426
$loadings
Factor1 Factor2 Factor3
食品 0.9463 0.1159 0.0808
衣着 0.1527 0.2499 0.9368
设备 0.7580 0.4145 0.2473
医疗 0.2249 0.8743 0.3625
交通 0.9231 0.2125 0.1572
教育 0.8252 0.3638 0.3555
居住 0.6864 0.6337 0.1166
杂项 0.6843 0.2980 0.5446
$common
食品 衣着 设备 医疗 交通 教育 居住 杂项
0.9154 0.9633 0.8075 0.9463 0.9220 0.9396 0.8863 0.8537
$scores
Factor1 Factor2 Factor3
北京 1.1809 1.7412 2.0290
天津 0.2046 2.9618 -0.7387
河北 -0.9265 1.2088 -0.4632
山西 -0.7897 0.4327 -0.0522
内蒙古 -0.6201 -0.1896 2.1005
辽宁 -0.5131 1.0768 -0.1141
吉林 -1.0477 1.1584 0.4543
黑龙江 -1.1602 0.2922 0.2628
上海 3.2545 -0.5022 1.4097
江苏 0.6052 0.1425 -0.2101
浙江 1.3890 -0.1951 1.4370
安徽 -0.1541 -0.4470 -0.3505
福建 1.1476 -0.3018 -0.7813
江西 -0.0832 -1.2579 -0.1148
山东 -0.2627 0.2887 0.7222
河南 -0.7577 -0.0927 0.3236
湖北 -0.1878 -0.5959 0.0212
湖南 -0.2446 0.0655 0.0409
广东 2.5034 0.6980 -1.7414
广西 0.0188 -0.2303 -1.5152
海南 0.4320 -0.1480 -2.7440
重庆 -0.1677 0.4392 0.2490
四川 0.0560 -1.0855 -0.0582
贵州 -0.1109 -1.4756 -0.1668
云南 -0.6155 -0.4253 -0.8160
西藏 0.0120 -2.4631 -0.0009
陕西 -0.4242 0.1703 -0.2714
甘肃 -0.4563 -0.4664 0.0892
青海 -0.6605 -0.4281 -0.0065
宁夏 -0.7857 0.2793 -0.1067
新疆 -0.8359 -0.6509 1.1126
$ranks
Factor Rank
北京 1.4913 2
天津 0.6443 5
河北 -0.3321 18
山西 -0.3491 20
内蒙古 0.0583 10
辽宁 -0.0591 11
吉林 -0.2161 13
黑龙江 -0.5204 29
上海 1.9899 1
江苏 0.3244 7
浙江 1.0313 4
安徽 -0.2639 17
福建 0.4010 6
江西 -0.3627 21
山东 0.0747 8
河南 -0.3734 23
湖北 -0.2382 15
湖南 -0.1119 12
广东 1.1817 3
广西 -0.3651 22
海南 -0.3779 24
重庆 0.0618 9
四川 -0.2333 14
贵州 -0.4397 27
云南 -0.6139 31
西藏 -0.5655 30
陕西 -0.2536 16
甘肃 -0.3427 19
青海 -0.4675 28
宁夏 -0.3940 26
新疆 -0.3787 25
# 绘图
> biplot(fp$scores[,1:2],fp$loadings[,1:2])
> biplot(fp$scores[,c(1,3)],fp$loadings[,c(1,3)])
#也可以选取2,3两项 biplot(fp$scores[,2:3],fp$loadings[,2:3])