【深度学习】笔记6:使用caffe中的CIFAR10网络模型和自己的图片数据训练自己的模型(步骤详解)
(一)准备自己的图片数据库
1)我的训练图片图片和测试图片的来源:
我的图片来源于徐其华的博客,(http://www.cnblogs.com/denny402/p/5083300.html).这是一个小型的图片数据库,这个图片数据库有500张图片;训练样本400张,测试样本100张;分为5类:bus,dinosaur,elephant,rose,horse(大巴,恐龙,大象,鲜花,马)。
图片的size==(384*256);图片格式为JPG格式.由于我在此块使用的是CIFAR-10模型,而在CIFAR10模型中,训练样本和测试样本的图片size==(32*32)(pixel),因此在我们开始训练自己的模型之前,我们首先需要对所有的图片进行预处理.其中最重要的预处理操作就是:图片尺寸的归一化.
在此块,我基于OpenCv写了一个预处理Demo程序,具体的程序如下所示:
/*******************************************************************************************************************
*文件功能:
* 1--针对CIFRA-10模型,进行的图片处理程序,将图片处理成32*32的大小
* 2--用于更改图片的图片名,后缀图片格式,图片的大小
* win10+vs2013+OpenCv2.4.8
*时间地点:
* 陕西师范大学 2016.10.28
********************************************************************************************************************/
#include
#include
#include
#include
#include
#include
#include
using namespace std;
using namespace cv;
int main()
{
char strFilename[100]; //【1】定义一个字符数组保存----图片的存储路径
char strWindowname[100]; //【2】定义一个字符数组保存----用于动态更新窗口的窗口名
char strFilenameAft[100]; //【3】定义一个字符数组保存----用于给处理之后的图片动态的命名
int j = 1;
for (int i = 720; i <=799; i++)
{ //【4】将图片的路径名动态的写入到strFilename这个地址的内存空间
sprintf_s(strFilename, "D:\\mydata\\train\\%d.jpg", i);
sprintf_s(strFilenameAft, "D:\\mydata\\aft_train\\horse%d.jpeg", j);
sprintf_s(strWindowname, "srcImg%d", j);
//===========================================================================================
//【模块1】将图片读入内存,并显示
//===========================================================================================
IplImage* pImg = cvLoadImage(strFilename); //【1】从指定的路径,将图片加载到内存中
cvNamedWindow(strWindowname, CV_WINDOW_AUTOSIZE); //【2】创建一个显示图片的窗口
cvMoveWindow(strWindowname, 200, 200); //【3】将显示窗口固定在(200,200)这个位置显示都进来的图片
cvShowImage(strWindowname, pImg); //【4】显示图片
//===========================================================================================
//【模块2】高斯金字塔下采样
// 1----将图片size调节到32*32左右,并显示
// 2----384*256:经过连续三次下采样,变为48*32
//============================================================================================
IplImage* pPyrDownImg = cvCreateImage(cvSize(pImg->width / 2, pImg->height / 2), pImg->depth, pImg->nChannels);
IplImage* pPyrDownImg1 = cvCreateImage(cvSize(pPyrDownImg->width / 2, pPyrDownImg->height / 2), pPyrDownImg->depth, pPyrDownImg->nChannels);
IplImage* pPyrDownImg2 = cvCreateImage(cvSize(pPyrDownImg1->width / 2, pPyrDownImg1->height / 2), pPyrDownImg1->depth, pPyrDownImg1->nChannels);
cvPyrDown(pImg, pPyrDownImg, CV_GAUSSIAN_5x5); //【1】384*256--->192*128
cvPyrDown(pPyrDownImg, pPyrDownImg1, CV_GAUSSIAN_5x5);//【2】192*128--->96*64
cvPyrDown(pPyrDownImg1,pPyrDownImg2, CV_GAUSSIAN_5x5);//【3】96*64----->48*32
cvNamedWindow("【PyrDown】", CV_WINDOW_AUTOSIZE);
cvMoveWindow ("【PyrDown】", 500, 200);
cvShowImage("【PyrDown】", pPyrDownImg2);
//============================================================================================
//【模块3】设置ROI区域裁剪图片----利用ROI区域将图片裁剪为:32*32
//============================================================================================
cvSetImageROI(pPyrDownImg2, cvRect(8, 0, 32, 32));//【1】设置一个32*32的ROI区域
cvNamedWindow("【ROI_Img】");
cvMoveWindow ("【ROI_Img】", 700, 200);
cvShowImage ("【ROI_Img】", pPyrDownImg2);
cvSaveImage (strFilenameAft, pPyrDownImg2); //【2】将修改图片size之后的图片保存在指定的文件夹下
++j;
cv::waitKey(10);
//============================================================================================
//【模块4】释放内存空间
//============================================================================================
cvReleaseImage(&pPyrDownImg);
cvReleaseImage(&pImg); //【1】释放掉存储图片的内存
cvDestroyWindow(strWindowname); //【2】销毁窗口的内存
cvDestroyWindow("【ROI_Img】");
cvDestroyWindow("【PyrDown】");
}
return 0;
}
使用上面程序对Image进行图片尺寸归一化,命名的统一等操作.
没有使用程序处理之前的图片(384*256),图片的命名也不统一,如下图所示:
使用程序处理之后的图片,全部变为32*32的JPEG格式的图片,并且图片的命名也进行了统一:
2)建立自己的数据文件夹
在./caffe/data/目录下建立自己的数据文件夹myself,并且在myself文件夹下建立train文件夹和val文件夹.train文件夹用于存放训练样本,val文件夹用于存放测试样本(验证集),如下图所示:
然后,将你处理好的训练样本图片放在./caffe/data/myself/train/这个文件夹下面,测试样本放在./caffe/data/myself/val/这个文件夹下面.
3)编写train.txt和val.txt文本
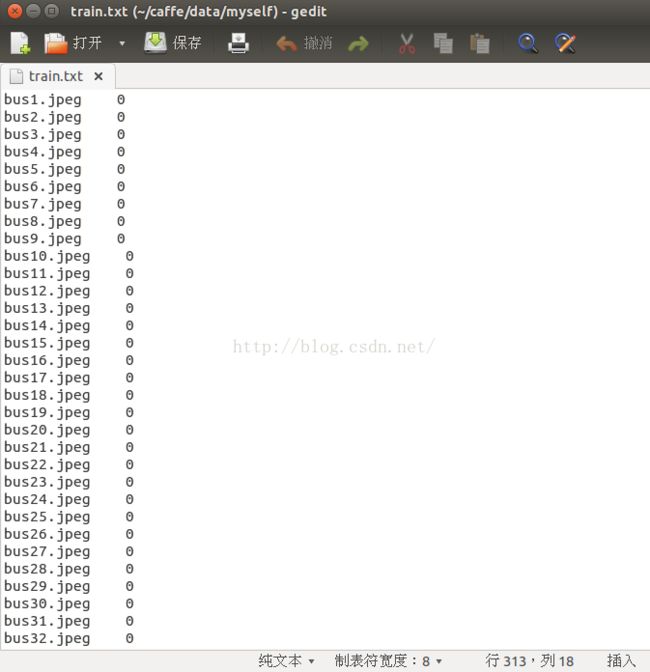
1----train.txt----存放训练图片的图片名和类别标签,一行一张图片,如下所示:
(这块要特别注意的一点是:在下面这两个文本文件中,图片名和标签之间的距离,只能是一个空格键),如果这两者之间的距离多于或者少于一个[空格键的话],那么,在图片数据---》LMDB数据格式这一步一般不会报错,但是,当计算均值的时候,会出现错误或者问题)
(比如下面文本文档,我使用了4个空格,就出现了这种问题,现在大家把他们之间的距离调整为一个空格,就可以运行了)
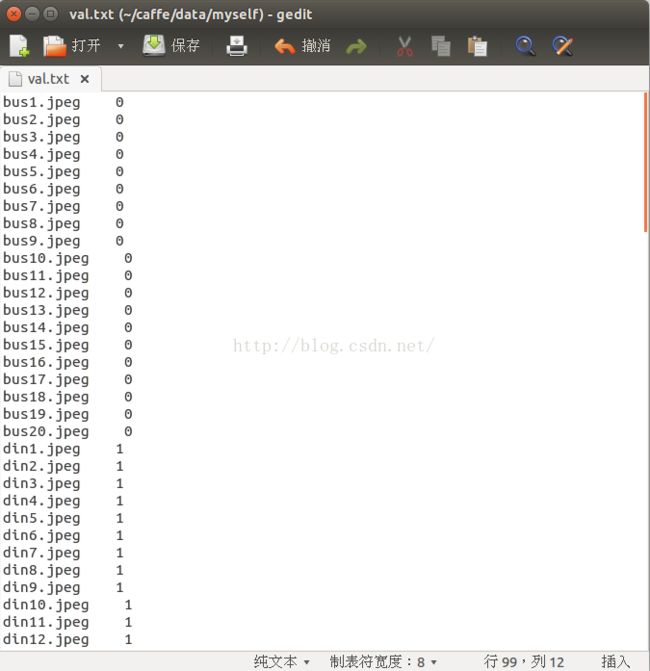
2----val.txt------存放测试样本的图片名和类别标签,一行代表一张图片,如下图所示:
(二)将图片数据转换为LMDB格式的数据:
在./caffe/examples/文件夹下面,建立myself文件夹,并且将:./caffe/examples/imagenet/文件夹下面的create_imagenet.sh这个shell脚本copy到myself文件夹下,打开,将里面的内容更改为下面的形式,如图所示:
#!/usr/bin/env sh
# Create the myself lmdb inputs
# N.B. set the path to the myself train + val data dirs
set -e
EXAMPLE=examples/myself
DATA=data/myself
TOOLS=build/tools
echo "Creating train lmdb..."
GLOG_logtostderr=1 $TOOLS/convert_imageset.bin \
--resize_height=32 \
--resize_width=32 \
--shuffle \
/home/wei/caffe/data/myself/train/ \
$DATA/train.txt \
$EXAMPLE/myself_cifar10_train_lmdb
echo "Creating val lmdb..."
GLOG_logtostderr=1 $TOOLS/convert_imageset.bin \
--resize_height=32 \
--resize_width=32 \
--shuffle \
/home/wei/caffe/data/myself/val/ \
$DATA/val.txt \
$EXAMPLE/myself_cifar10_val_lmdb
echo "Done."
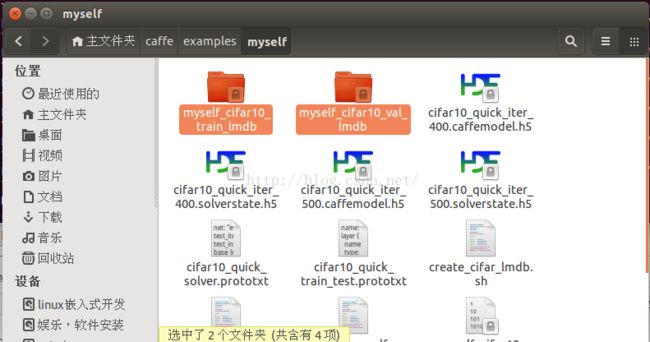
产生的连个数据库文件,如下图所示:
(三)计算图像的均值(减均值操作)
在./caffe/examples/myself/文件夹下面,创建make_myself_mean.sh这个shell脚本,并且编辑内容如下所示:
#!/usr/bin/env sh
# Compute the mean image from the myself training lmdb
# N.B. this is available in data/myself
TOOLS=./build/tools
DATA=./data/myself
EXAMPLE=./examples
$TOOLS/compute_image_mean.bin $EXAMPLE/myself/myself_cifar10_train_lmdb $EXAMPLE/myself/myself_cifar10_mean.binaryproto
echo "Done."
在终端执行这个脚本文件,则会产生一个名为:myself_cifar10_mean.binaryproto的均值文件,如下所示:
(四)创建网络模型,编写配置文件,编写训练脚本
1)创建网络模型
此快,我们使用CIFAR10网络模型,因此,将./examples/cifar10/文件夹下的cifar10_quick_train_test.prototxt网络模型配置文件copy到我们的文件夹./examples/myself/下面,并且进行如下的修改:
name: "CIFAR10_quick"
layer {
name: "cifar"
type: "Data"
top: "data"
top: "label"
include {
phase: TRAIN
}
transform_param { //【第1块修改的地方】下面是均值文件所在的路径,改为你自己的均值文件所在的路径
mean_file: "examples/myself/myself_cifar10_mean.binaryproto"
}
data_param { //【第2块修改的地方】下面改为训练样本生成的数据库所在的目录[注意:是训练样本数据库]
source: "examples/myself/myself_cifar10_train_lmdb"
batch_size: 10 //【第3块修改的地方】由于我们的训练样本只有400张图片,所以我们一次读入10张图片就可以了
backend: LMDB
}
}
layer {
name: "cifar"
type: "Data"
top: "data"
top: "label"
include {
phase: TEST
}
transform_param { //【第4块修改的地方】下面是均值文件所在的路径,改为你自己的均值文件所在的路径
mean_file: "examples/myself/myself_cifar10_mean.binaryproto"
}
data_param { //【第5块修改的地方】下面改为测试样本生成的数据库所在的目录[注意:是测试样本数据库]
source: "examples/myself/myself_cifar10_val_lmdb"
batch_size: 10 //【第6块修改的地方】由于我们的测试样本只有100张图片,所以我们一次读入10张图片就可以了
backend: LMDB
}
}
layer {
name: "conv1"
type: "Convolution"
bottom: "data"
top: "conv1"
param {
lr_mult: 1
}
param {
lr_mult: 2
}
中间的省略.......
layer {
name: "ip2"
type: "InnerProduct"
bottom: "ip1"
top: "ip2"
param {
lr_mult: 1
}
param {
lr_mult: 2
}
inner_product_param {
num_output: 5 //【第7块修改的地方】我们现在是5分类问题,所以将第二个全连接层改为5
weight_filler {
type: "gaussian"
std: 0.1
}
bias_filler {
type: "constant"
}
}
}
layer {
name: "accuracy"
type: "Accuracy"
bottom: "ip2"
bottom: "label"
top: "accuracy"
include {
phase: TEST
}
}
layer {
name: "loss"
type: "SoftmaxWithLoss"
bottom: "ip2"
bottom: "label"
top: "loss"
}(2)编写超参数配置文件:
我们也是用同样的方法,直接将./examples/cifar10/文件夹下的cifar10_quick_solver.prototxt这个超参数配置文件
copy到我们的目录下,然后,进行下面的修改就可以了:
#!/usr/bin/env sh
set -e
TOOLS=./build/tools
$TOOLS/caffe train \
--solver=examples/myself/cifar10_quick_solver.prototxt $@ //【1】改为你自己的网络模型配置文件的目录
net: "examples/myself/cifar10_quick_train_test.prototxt"
test_iter: 10 //【2】预测阶段迭代次数,我们设为10,这样就可以覆盖我们的100张测试样本
test_interval: 50 //【3】由于我们只有400张训练样本,所以我们将此改为50,每迭代50次,进行一次测试
base_lr: 0.001 //【4】权值学习率,其实就是在反向传播阶段,权值每次的调整量的程度
momentum: 0.9
weight_decay: 0.004
lr_policy: "fixed" //【5】在整个过程中,我们使用固定的学习率,当然,你也可以试一下可变学习率
display: 20
max_iter: 500 //【6】400张训练样本,所以我就将最大的迭代次数设为400
snapshot: 400
snapshot_format: HDF5
snapshot_prefix: "examples/myself/cifar10_quick"
solver_mode: CPU //【7】我用的是CPU,所以将此快设置为CPU(3)编写训练脚本
#!/usr/bin/env sh
set -e
TOOLS=./build/tools
$TOOLS/caffe train \
--solver=examples/myself/cifar10_quick_solver.prototxt $@然后,运行命令,训练自己的模型:如下图所示:
sudo sh ./examples/myself/train_quick.sh
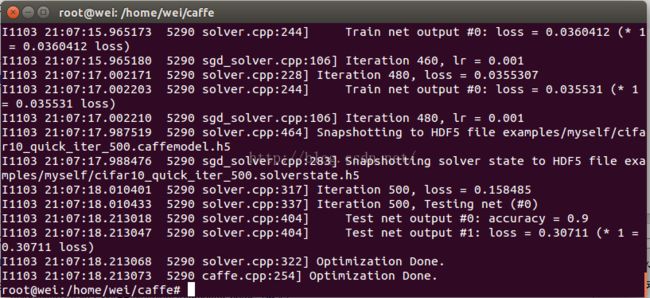
训练过程,如下所示:
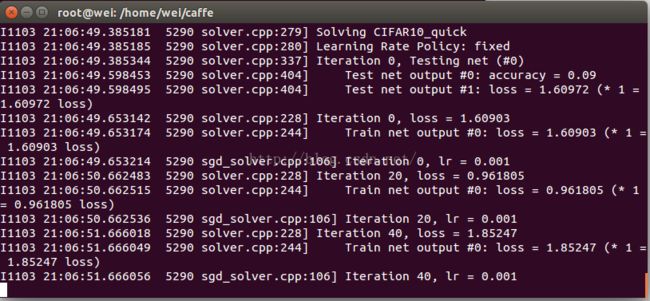
训练结果显示,正确率为90%,accuracy==0.9,如下图所示:
(五)训练结果的可视化
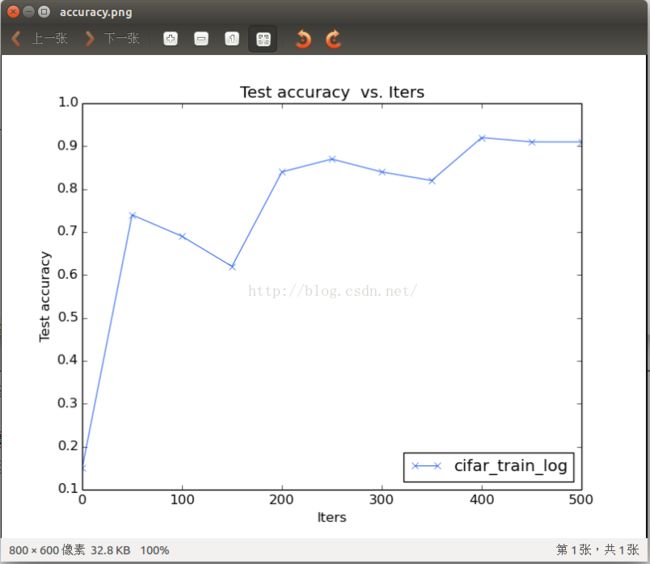
1---Accuracy曲线的可视化:
我们以迭代次数为X轴,以准确率为Y轴,输出的曲线如下所示:
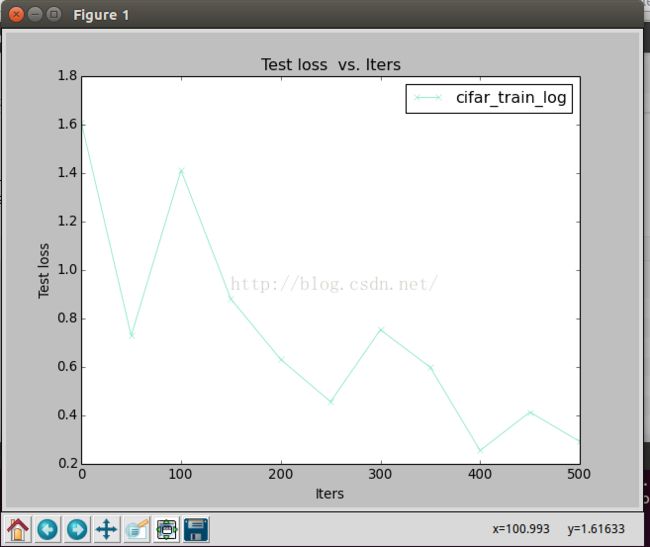
2---Loss曲线的可视化:
我们同样以迭代次数为X轴,以损失率为Y轴,可视化结果如下所示: