GoogLeNet原理和实现
个人博客:http://www.chenjianqu.com/
原文链接:http://www.chenjianqu.com/show-58.html
终于把论文啃完了,这篇论文读的不太顺畅,主要还是我英语水平不够。本文是论文Going deeper with convolutions.Christian Szegedy,etc.2014的阅读笔记,某些地方参考了网上的其它资料。
论文笔记
1.解决了什么
提高大规模图像分类和检测的精度。
2.使用的方法
提出了Inception神经网络架构,该架构在计算量较小的情况下增加了网络的深度和宽度。
设计了基于Inception架构的22层的网络,被称为GoogLeNet。
3.实验结果
该模型获得ImageNet Challenge 2014图像分类第一名。
4.待解决的问题
网络不够深,迁移能力不足。
背景知识
1.CNN对视觉皮层的模仿
视觉皮层(visual cortex)包含了一系列复杂的细胞,这些细胞中的每个细胞只是对一个视觉区域内极小的一部分敏感,而对其他部分则可以视而不见,所以每一个这样的小部分区域我们称为receptive field(局部感受野)。而所有的receptive field的叠加就构成了visual field,而这些cell在当中就扮演了一个local filter(局部滤波器)的角色。 cell有两种类型,简单or复杂,简单的cell通过receptive field可以最大程度响应特定的边缘特征;复杂的cell相比而言有更大的receptive field。
对应到CNN中,图像作为一个visual field,而每一个hidden layer中cells就是各种滤波器,每个局部滤波器就是一个卷积核,通过局部滤波器对图像的subset产生响应,之后每个cell提取到的信息传递到更高层汇总后就是整个图像的信息。
2.稀疏连接
为了模仿visual cortex中的cell对visual field的局部敏感,CNN在探索spatial-local correlation 的时候,通过在相邻层的神经元间使用一种local connectivity的方式,如下图所示,m-1层作为输入层,hidden layer m中的输入是来自于m-1中的subset,每个单元units有着相同范围的receptive field。
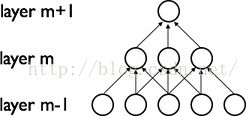
m层中的每个神经元的receptive field的宽度为3,能接受来自前一层3个神经元的输入,同理,在下一层m+1中,神经元同样接受来自m层3个神经元的输入,但是每个神经元对超出自己receptive field的神经元就不会产生连接,也就是不做出响应。
3.Hebbian原理
Hebbian认为“两个神经元或者神经元系统,如果总是同时兴奋,就会形成一种‘组合’,其中一个神经元的兴奋会促进另一个的兴奋”。比如狗看到肉会流口水,反复刺激后,脑中识别肉的神经元会和掌管唾液分泌的神经元会相互促进,“缠绕”在一起,以后再看到肉就会更快流出口水。
4.全连接层的作用
这里使用了global average pooling替代了全连接层,那么全连接层的作用是什么呢?以下来源于知乎:
全连接层(fully connected layers,FC)在整个卷积神经网络中起到“分类器”的作用。如果说卷积层、池化层和激活函数层等操作是将原始数据映射到隐层特征空间的话,全连接层则起到将学到的“分布式特征表示”映射到样本标记空间的作用。在实际使用中,全连接层可由卷积操作实现:对前层是全连接的全连接层可以转化为卷积核为1x1的卷积。目前由于全连接层参数冗余(仅全连接层参数就可占整个网络参数80%左右),所以在GoogLeNet上被替换为全局平均池化。
微调(fine tuning)是深度学习领域最常用的迁移学习技术。针对微调,若目标域(target domain)中的图像与源域中图像差异巨大(如相比ImageNet,目标域图像不是物体为中心的图像,而是风景照,见下图),不含FC的网络微调后的结果要差于含FC的网络。因此FC可视作模型表示能力的“防火墙”,特别是在源域与目标域差异较大的情况下,FC可保持较大的模型capacity从而保证模型表示能力的迁移。
模型提出
提高模型性能最简单的方法是增加网络的大小,包括深度(网络的层数)和宽度(每层的单元数)。单纯的增大模型的缺点是:
1.模型越大,参数越多,更容易过拟合。减小的过拟合的方法增加训练数据,但这一方法的成本很高。
2.参数越多,所需的计算资源越多。所以如果没有有效的使用增加的网络容量,比如大多数权重接近0,那么会浪费大量的计算资源。
解决上述问题的办法是用稀疏连接替代全连接,甚至对卷积层也替换为一个更稀疏的卷积。理论依据来源于Arota等论文[Provable bounds for learning some deep representations],论文认为如果数据集的概率分布可以用大规模、非常稀疏的深度学习网络表示,则优化网络的方法可以是逐层的分析层输出的相关性,对相关的输出做聚类操作。
为什么需要稀疏连接:人脑神经元的连接是稀疏的,研究者认为大型神经网络的合理的连接方式应该也是稀疏的,稀疏结构是非常适合神经网络的一种结构,尤其是对非常大型、非常深的神经网络,可以减轻过拟合并降低计算量,例如CNN就是稀疏连接。
但是当前计算机在非均匀的稀疏数据结构方面的数值计算很低效,而且非均匀的稀疏模型需要更加复杂的工程实现。此外,当前的方法仅仅是使用卷积来利用空间域的稀疏性。希望要找一个能利用额外的稀疏性同时基于密集矩阵的。解决稀疏矩阵乘法的方法就是将稀疏矩阵聚类成相对密集的子矩阵。
Inception架构就是试图逼近隐含在视觉网络中的稀疏结构,并利用密集、易实现的组件来实现这样的假设(隐含的稀疏结构)。
Inception架构
主要思想是找到可以逼近的卷积视觉网络内的最优局部稀疏结构,并可以通过易实现的模块实现这种结构。使用大的卷积核在空间上会扩散更多的区域,而对应的聚类就会变少,聚类的数目随着卷积核增大而减少,为了避免这个问题,Inception架构当前只使用1*1,3*3,5*5卷积核,这更多的是为了方便而不是必须的。此外,还有一个并行的stride=1,3x3的最大池化层。这几个卷积层的输出滤波器组将被concatenate成一个滤波器组。如下图:
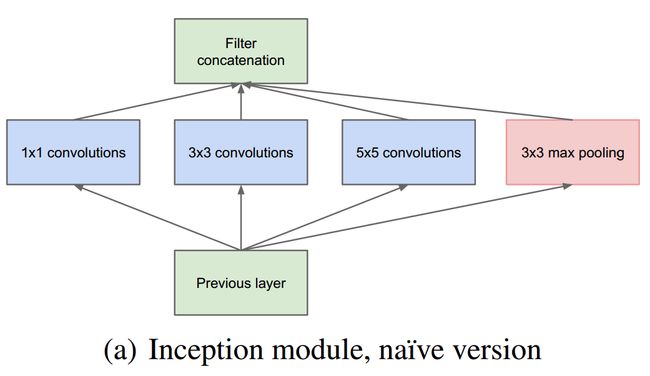
上面这个网络存在的问题是:首先5x5的卷积操作在计算有很多通道的feature map时所需的计算量是巨大的,而且池化层不能减少通道数,那么随着Inception堆叠数量的增加,将产生'通道爆炸'。因此要在架构里使用降维和投影:在计算3*3或5*5卷积前面加入1*1卷积用来压缩信息,而且1*1卷积使用ReLU,这增加了模型的非线性表示。如下图:
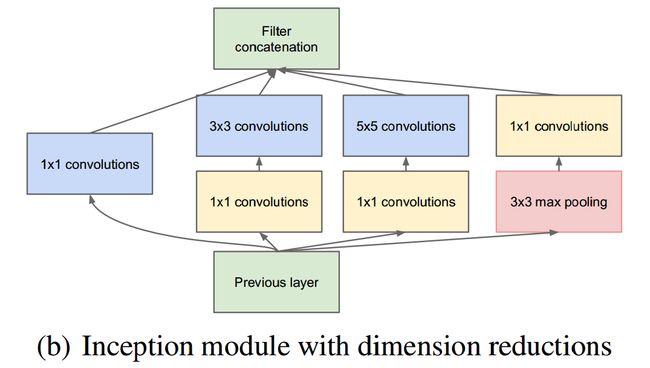
Inception的4个分支在最后通过一个聚合操作合并,构建出了很高效的符合Hebbian原理的稀疏结构。Inception中包含了三种不同尺寸的卷积和一个最大池化,增加了网络对不同尺度的适应性,这一部分与Multi-Scale的思想类似。总的来说Inception可以让网络的深度和宽度高效率地扩充,提高准确率且不致于过拟合。
在Inception中,通常1*1卷积的比例(输出通道数占比)最高,3*3卷积和5*5卷积稍低。
整个模型中,会有多个堆叠的Inception。在后几层,当更高的抽象特征被更高的层捕获时,它们的空间集中度预计会降低。因此,越靠后的Inception中,3*3和5*5这两个大面积的卷积核的占比(输出通道数)应该更多。
GoogLeNet
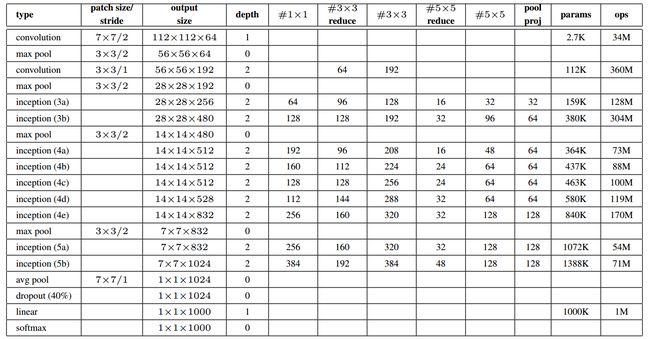
名字由来:纪念Yann LeCun的LeNet5。GoogLeNet网络是基于Inception架构搭建的22层的深度神经网络,配置表格如下:
-
所有的隐层(包括Inception内部)都使用ReLU激活函数;
-
输入为224x224x3的图像,with mean subtraction;
-
表格中#3x3 reduce和#5x5 reduce代表Inception中3x3和5x5卷积前1x1卷积的通道数。
-
表格中的pool proj表示Inception中池化后1x1卷积的通道数。
-
这里说的1x1投影层也用ReLU激活函数。
GoogLeNet有参数的层数为22层,加上pooling的话有27层。在模型的后面有一个average pooling层,相比于
由于网络比较深,而且中间层很重要,我们期望模型在较低阶段就可以拥有判别能力,因此在中间层增加辅助的分类器(auxiliary classifiers),不仅增加了反向传播的梯度,而且提供额外的正则化。这些辅助的分类器采用更小的卷积网络的形式,放在Inception (4a)和(4d)模块的输出之上。在训练过程中,他们的损失以折算权加入到网络的总损失中(辅助分类器的损失加权为0.3)。在推理时,这些辅助网络被丢弃。
辅助网络的配置如下:
1. An average pooling layer with 5×5 filter size and stride 3, resulting in an 4×4×512 output for the (4a), and 4×4×528 for the (4d) stage.
2. A 1×1 convolution with 128 filters for dimension reduction and rectified linear activation.
3. A fully connected layer with 1024 units and rectified linear activation.
4. A dropout layer with 70% ratio of dropped outputs.
5. A linear layer with softmax loss as the classifier (predicting the same 1000 classes as the
main classifier, but removed at inference time).
来感受一下GoogLeNet的网络结构图:
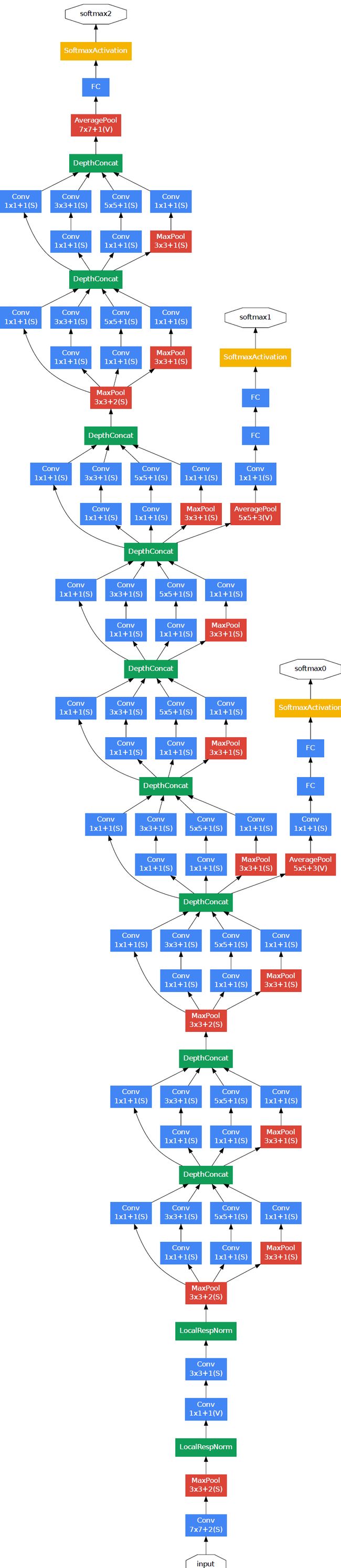
训练细节
使用asynchronous stochastic gradient descent,0.9的动量系数,学习率每8epochs下降4%。Infetence阶段使用Polyak averaging创建最终模型。
ImageNet比赛
ILSVRC 2014 Classification Challenge

ILSVRC 2014 Detection Challenge

代码实现
1.数据集处理,同上一篇博文VGGNet原理和实现
2.定义网络
由于我所用的数据集不是ImageNet-1k,故于这里定义的网络跟原文描述的略有不同。 此外,网络中没有加入LRN层。
from keras.models import *
from keras.layers import *
from keras import models
from keras import initializers
from keras.utils import plot_model
import keras.backend as K
normal_init=initializers.RandomNormal(mean=0.0, stddev=0.01, seed=None)
def ConvLayer(kernels,size,strides,name):
return Conv2D(kernels,size,strides=strides,padding='same',activation='relu',kernel_initializer=normal_init,bias_initializer='zeros',name=name)
def Inception(inputs,kernel1,kernel3_pj,kernel3,kernel5_pj,kernel5,kernel_pool_pj,name):
channel1=ConvLayer(kernel1,1,1,name+'_1x1')(inputs)
channel3_pj=ConvLayer(kernel3_pj,1,1,name+'_3_pj')(inputs)
channel3=ConvLayer(kernel3,3,1,name+'_3x3')(channel3_pj)
channel5_pj=ConvLayer(kernel5_pj,1,1,name+'_5_pj')(inputs)
channel5=ConvLayer(kernel5,5,1,name+'_5x5')(channel5_pj)
maxpooling=MaxPooling2D(pool_size=3,strides=1,padding='same',name=name+'_3x3_pooling')(inputs)
channel_pool=ConvLayer(kernel_pool_pj,1,1,name+'_pool_pj')(maxpooling)
outputs =Concatenate(axis=3)([channel1,channel3,channel5,channel_pool] ) #拼接
return outputs
def AuxiliaryClassfier(inputs,name):
net=AveragePooling2D(pool_size=(5, 5), strides=3,name=name+'_avg')(inputs)
net=ConvLayer(128,1,1,name+'_1x1')(net)
net=Flatten(name=name+'_flatten')(net)
net=Dense(512,activation='relu',kernel_initializer=normal_init,name=name+'_dense')(net)
net=Dropout(0.7)(net)
net=Dense(100,activation='softmax',kernel_initializer=normal_init,name=name+'_output')(net)
return net
X=Input(shape=(224,224,3),name='input')
net=ConvLayer(64,7,2,'conv1')(X)
net=MaxPooling2D(pool_size=3,strides=2,name='maxpooling1')(net)
#LRN
net=ConvLayer(64,1,1,'conv2')(net)
net=ConvLayer(192,3,1,'conv3')(net)
#LRN
net=MaxPooling2D(pool_size=3,strides=2,padding='same',name='maxpooling2')(net)
net=Inception(net,64,96,128,16,32,32,'inception3a')
net=Inception(net,128,128,192,32,96,64,'inception3b')
net=MaxPooling2D(pool_size=3,strides=2,padding='same',name='maxpooling3')(net)
net=Inception(net,192,96,208,16,48,64,'inception4a')
aux1=AuxiliaryClassfier(net,'aux1')
net=Inception(net,160,112,224,24,64,64,'inception4b')
net=Inception(net,128,128,256,24,64,64,'inception4c')
net=Inception(net,112,144,288,32,64,64,'inception4d')
aux2=AuxiliaryClassfier(net,'aux2')
net=Inception(net,256,160,320,32,128,128,'inception4e')
net=MaxPooling2D(pool_size=3,strides=2,padding='same',name='maxpooling4')(net)
net=Inception(net,256,160,320,32,128,128,'inception5a')
net=Inception(net,384,192,384,48,128,128,'inception5b')
net=GlobalAveragePooling2D(data_format=None,name='GAP')(net)
net=Dropout(0.4)(net)
outputs=Dense(100,activation='softmax',kernel_initializer=normal_init,name='output')(net)
model = Model(X, [outputs,aux1,aux2])
model.summary()
plot_model(model,to_file='GoogLeNet.png',show_shapes=True)3.定义数据生成器并训练网络
from keras.preprocessing import image
from keras import initializers
from keras import optimizers
import os
from keras.models import load_model
from keras import metrics
from keras import losses
MODEL_SAVE_PATH=r'D:/Jupyter/cv/GoogLeNet_log/googlenet.h5'
TRAIN_DATA_PATH=r'C:/dataset/images_normal'
VAL_DATA_PATH=r'F:\BaiduNetdiskDownload\mini-imagenet\image_normal_test'
BATCH_SIZE=32
EPOCHS=1
#定义训练集生成器
train_gen=image.ImageDataGenerator(
featurewise_center=True,#输入数据数据减去数据集均值
rotation_range=30,#旋转的度数范围
width_shift_range=0.2,#水平平移
height_shift_range=0.2,#垂直平移
shear_range=0.2,#斜切强度
horizontal_flip=True,#水平翻转
brightness_range=[-0.1,0.1],#亮度变化范围
zoom_range=[0.5,1.5],#缩放的比例范围
preprocessing_function=None,#自定义的处理函数
)
#定义多输出数据生成器
def generator_multi_output(imageGen,data_path,batch_size):
x=imageGen.flow_from_directory(
data_path,
target_size=(224,224),
batch_size=batch_size,
class_mode='categorical'
)
while True:
data,label=next(x)
yield data,[label,label,label]
#定义数据生成器对象
tg=generator_multi_output(train_gen,TRAIN_DATA_PATH,BATCH_SIZE)
#定义验证集生成器
val_datagen = image.ImageDataGenerator()
vg=generator_multi_output(val_datagen,VAL_DATA_PATH,BATCH_SIZE)
if(os.path.exists(MODEL_SAVE_PATH)==False):
#编译模型
model.compile(optimizer=optimizers.SGD(lr=1e-2,momentum=0.9,decay=1e-6),
metrics=['acc',metrics.top_k_categorical_accuracy],
#损失为三个交叉熵的加权
loss={
'aux1_output':losses.categorical_crossentropy,
'aux2_output':losses.categorical_crossentropy,
'output': losses.categorical_crossentropy
},
loss_weights={
'aux1_output':0.3,
'aux2_output': 0.3,
'output':1.
},
)
else:
model=load_model(MODEL_SAVE_PATH)
#训练模型
history=model.fit_generator(
tg,
steps_per_epoch=int(50000/BATCH_SIZE),#每回合的步数
epochs=EPOCHS,
#validation_data=validation_generator,
#validation_steps=int(10000/BATCH_SIZE),
shuffle=True,
)
#保存模型
model.save(filepath=MODEL_SAVE_PATH)参考文献
[1]Christian Szegedy,etc.Going deeper with convolutions.2014
[2] 魏秀参. 全连接层的作用是什么?.https://www.zhihu.com/question/41037974/answer/150522307 .2017-09-20
[3]张磊_0503. 深入理解GoogLeNet结构(原创).https://www.jianshu.com/p/bfc6da961059.2017-11.15
[4] tuyunbin1995. CNN学习笔记(1)稀疏连接和权值共享的理解.https://blog.csdn.net/tuyunbin1995/article/details/52888506.2016-10-22
[5] WangR0120. TensorFlow实战:Chapter-5(CNN-3-经典卷积神经网络(GoogleNet)). https://blog.csdn.net/WangR0120/article/details/80221117. 2018-05-07