基于pytorch的图像分类(CIFAR-10数据集)
pytorch的图像分类实践
在学习pytorch的过程中我找到了关于图像分类的很浅显的一个教程上一次做的是pytorch的手写数字图片识别是灰度图片,这次是彩色图片的分类,觉得对于像我这样的刚刚开始入门pytorch的小白来说很有意义,今天写篇关于这个图像分类的博客.
收获的知识
1.torchvison
在深度学习中数据加载及预处理是非常复杂繁琐的,但PyTorch提供了一些可极大简化和加快数据处理流程的工具。同时,对于常用的数据集,PyTorch也提供了封装好的接口供用户快速调用,这些数据集主要保存在torchvison中,torchvison实现了常用的图像数据加载功能,例如Imagenet、CIFAR10、MNIST等,以及常用的数据转换操作,这极大地方便了数据加载,并且代码具有可重用性。
2.transform = transforms.Compose([
transforms.ToTensor(), # 转为Tensor
transforms.Normalize((0.5, 0.5, 0.5),(0.5, 0.5, 0.5)), # 归一化
])
根据我手上的中文文档,Compose方法大概是把多个transform组合起来使用


关于这个ToTensor()我自己跑了一下例子,这个方法就是根据图像的像素,色彩情况把一张图片转化为pytorch中的一个tensor便于数据化处理图像。
归一化我的博客以前写过就是一种处理数据的手段既可以让数据保留特征又可以控制数据在一个很小的范围,便于计算。
import torch
import torchvision
import numpy as np
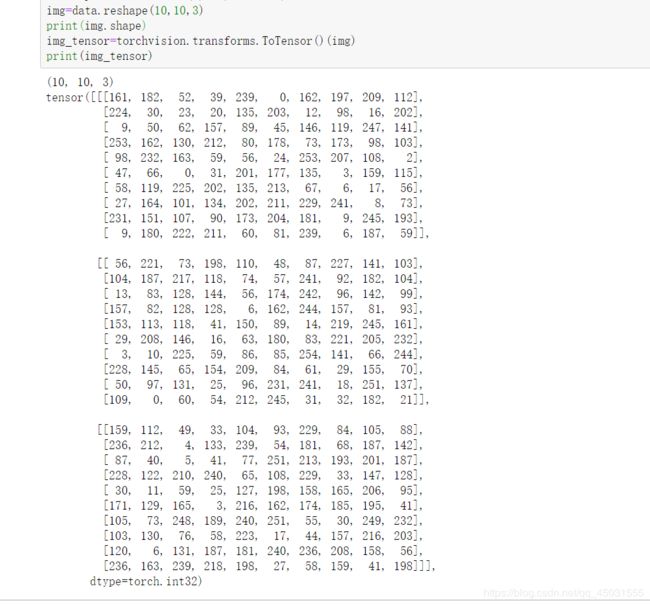
data=np.random.randint(0,255,size=300)
img=data.reshape(10,10,3)
print(img.shape)
img_tensor=torchvision.transforms.ToTensor()(img)
print(img_tensor)
截图:
3.pytorch中常用数据集的加载和使用
我是用的Jupter做的这个实践,首先先把数据集下载到本地,最好直接下载到jupter的路径里面,然后运行就可以发现开始下载了。


Dataset对象:我们事先会把下载好的数据集命名为 dataset和trainset

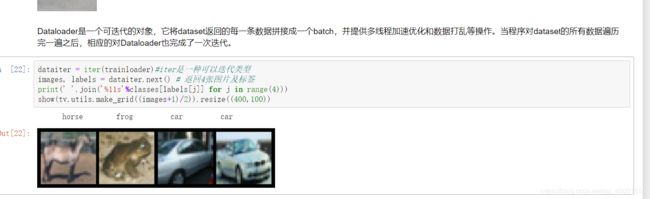
模型的训练
使用自己的网络
起初我看那个教程上的网络使用的LeNet,我就把上次做手写数字的模型拿过来改了一下,多加了两个全连接层
import torch as t
import torch.nn as nn
from torch.autograd import Variable
import torch.utils.data as Data
import torchvision as tv
import numpy
class CNN(nn.Module):#继承了nn.Model
def __init__(self):
#继承了 CNN 父类的的属性
super(CNN, self).__init__()#用父类的初始化方式来初始化所继承的来自父类的属性
#按照网络的前后顺序定义1号网络
self.conv1 = nn.Sequential( # input shape (3, 32, 32)
nn.Conv2d(#这里的nn.Conv2d使用一个2维度卷积
in_channels=3, #in_channels: 因CIFAR-10是3通道彩图这里用3
out_channels=16, # out_channels:卷积产生的通道数,有多少个out_channels,就需要多少个一维卷积(也就是卷积核的数量)
kernel_size=5, #kernel_size:卷积核的尺寸;卷积核的第二个维度由in_channels决定,所以实际上卷积核的大小为kernel_size * in_channels
stride=1, #步长,每次移动的单位格子
padding=2, #padding:对输入的每一条边,补充0的层数
), # output shape (16, 32, 32)
nn.ReLU(), #激活函数ReLU # activation
#在2X2的池化层里选出最大值
nn.MaxPool2d(kernel_size=2), # choose max value in 2x2 area, output shape (16, 16, 16)
)
#按照网络的前后顺序定义2号网络,
self.conv2 = nn.Sequential( # input shape (16, 16, 16)
#使用一个二维卷积
nn.Conv2d(16, 32, 5, 1, 2), # output shape (32, 16, 16)
nn.ReLU(), # activation
nn.MaxPool2d(2), # output shape (32, 8, 8)
)
#全连接层
self.fullconnect1 = nn.Linear(32 * 8 *8 , 120) #因为在pytorch中做全连接的输入输出都是二维张量,不同于卷积层要求输入4维张量
self.fullconnect2 = nn.Linear(120,84)
self.fullconnect3 = nn.Linear(84,10)
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
x = x.view(x.size(0), -1) # flatten the output of conv2 to (batch_size, 32 * 8 * 8)
x = self.fullconnect1(x)
x=self.fullconnect2(x)
x = self.fullconnect3(x)
return x
net=CNN()
print(net)
训练效果是很糟糕的:


10%就是在猜,那么这个模型和猜的差不多
继续使用自己的网络把全连接层改成一层
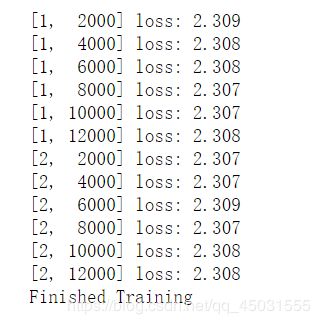
效果依旧很糟糕
使用教程的网络模型
import torch.nn as nn
import torch.nn.functional as F
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16*5*5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = F.max_pool2d(F.relu(self.conv1(x)), (2, 2))
x = F.max_pool2d(F.relu(self.conv2(x)), 2)
x = x.view(x.size()[0], -1)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
net = Net()
print(net)
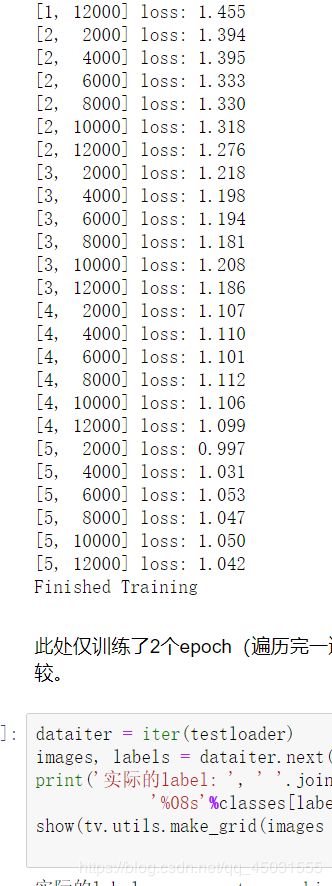
训练的结果好很多:

代码部分:
使用torchvision加载并预处理CIFAR-10数据集
定义网络
定义损失函数和优化器
训练网络并更新网络参数
测试网络
import torch as t
import torchvision as tv
import torchvision.transforms as transforms
from torchvision.transforms import ToPILImage
show = ToPILImage() # 可以把Tensor转成Image,方便可视化
# 第一次运行程序torchvision会自动下载CIFAR-10数据集,
# 大约100M,需花费一定的时间,
# 如果已经下载有CIFAR-10,可通过root参数指定
# 定义对数据的预处理
transform = transforms.Compose([
transforms.ToTensor(), # 转为Tensor
transforms.Normalize((0.5, 0.5, 0.5),(0.5, 0.5, 0.5)), # 归一化
])
# 训练集
trainset = tv.datasets.CIFAR10(
root='./CIFAR10/',
train=True,
download=False,
transform=transform)
trainloader = t.utils.data.DataLoader(
trainset,
batch_size=4,
shuffle=True,
num_workers=2)
# 测试集
testset = tv.datasets.CIFAR10(
'./CIFAR10/',
train=False,
download=True,
transform=transform)
#数据集按照 bitch_size(批处理大小设置),shuffle(是否进行洗牌)把数据封装成一个Batch Size大小的Tensor,用于后面的训练。
testloader = t.utils.data.DataLoader(
testset,
batch_size=4,
shuffle=False,
num_workers=2)#是否进行多进程加载数据
classes = ('plane', 'car', 'bird', 'cat',
'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
import torch.nn as nn
import torch.nn.functional as F
#定义神经网络
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5) #输入通道3,彩色图片的输入通道要改成三,输出通道为6,卷积核大小(5*5)
self.conv2 = nn.Conv2d(6, 16, 5) #第二个卷积层输入通道是上一个卷积的输出通道6,输出通道为16,卷积核大小(5*5)
self.fc1 = nn.Linear(16*5*5, 120) #全连接层1 fullconnect
self.fc2 = nn.Linear(120, 84)#全连接层2
self.fc3 = nn.Linear(84, 10)#全连接层3
def forward(self, x):
x = F.max_pool2d(F.relu(self.conv1(x)), (2, 2))
x = F.max_pool2d(F.relu(self.conv2(x)), 2)
x = x.view(x.size()[0], -1) #把数据对整齐,防止输入输出不匹配
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
net = Net()
print(net)
#定义损失函数和优化器
from torch import optim
criterion = nn.CrossEntropyLoss() # 交叉熵损失函数
optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)
#训练网络更新网络参数
t.set_num_threads(8)
for epoch in range(10):
running_loss = 0.0
for i, data in enumerate(trainloader, 0):
# 输入数据
inputs, labels = data
inputs, labels = Variable(inputs), Variable(labels)#转换成Variable 可以自动微分求导
# 梯度清零
optimizer.zero_grad()
# forward + backward
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
# 更新参数
optimizer.step()
# 打印log信息
running_loss += loss.item()
if i % 2000 == 1999: # 每2000个batch打印一下训练状态
print('[第%d轮, 第%5d张图片] 损失函数:loss: %.3f' \
% (epoch+1, i+1, running_loss / 2000))
running_loss = 0.0
print('Finished Training')
#测试网络
dataiter = iter(testloader)
images, labels = dataiter.next() # 一个batch返回4张图片
print('实际的label: ', ' '.join(\
'%08s'%classes[labels[j]] for j in range(4)))
#打印标签对应的正确照片,前提是得复原成归一化前的数据
show(tv.utils.make_grid(images / 2 - 0.5)).resize((400,100))
# 计算图片在每个类别上的分数
outputs = net(Variable(images))
# 得分最高的那个类
_, predicted = t.max(outputs.data, 1)
print('预测结果: ', ' '.join('%5s'\
% classes[predicted[j]] for j in range(4)))
correct = 0 # 预测正确的图片数
total = 0 # 总共的图片数
for data in testloader:
images, labels = data
outputs = net(Variable(images))
_, predicted = t.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum()
print('10000张测试集中的准确率为: %d %%' % (100 * correct / total))
运行截图:



网络层数太少,训练10轮效果和五轮差不多可能后面的训练造成了过拟合。大家也可以动手做一下上面的小实验。