CS231n笔记4-Data Preprocessing, Weights Initialization与Batch Normalization
Data Preprocessing, Weights Initialization与Batch Normalization
- Data Preprocessing Weights Initialization与Batch Normalization
- 数据预处理Data Preprocessing
- 权重初始化Weights Initialization
- 让权重初始化为0
- 0方差1e-2标准差
- 0方差1标准差
- Xavier Initialization
- 再改进
- 批归一化Batch Normalization
- 后言
这一节与下一节我们来介绍一下在网络学习的前期,我们可以利用的方法以及需要注意的问题,这一节我们专注于三点
- 数据预处理:Data Preprocessing
- 权重初始化:Weights Initialization
- 批归一化:Batch Normalization
数据预处理:Data Preprocessing
通常我们比较常见的数据预处理是先将数据处理成零均值(zero-centered),然后再处理成单位标准差(normalized data)。
下面给出Python的代码:
def zero_centered(X):
"""X的每一行代表一个数据
"""
return X-np.mean(X, axis=0);
def normalized(X):
"""X的每一行代表一个数据
"""
return X/np.std(X, axis=0);
def data_preprocess(X):
"""X的每一行代表一个数据
"""
return normalized(zero_centered(X));还有一种常见的预处理的模式,是先将数据进行PCA转化然后再白化数据,然而在做图像处理的时候,一般都不会用这种办法,甚至都不进行标准差单位化,而是仅仅把均值置零。
这里就不给出PCA->Whitened的代码,如果有需要,我会在后期再补充上来。
权重初始化:Weights Initialization
在深度学习中,最重要的一个部分就是权重,可以这么说,几乎所有的一起技巧也好,方法也好,都是在为学习到更好的权重服务,因此,涉及到权重的方方面面,我们都需要小心。下面我们要将的是一个关键的门槛,权重的初始化。
让权重初始化为0
回想一下,我们是如何计算前向神经网络的(忘了的读者可以看我之前的CS231n笔记),当权重为0时,每一层的计算机构都是一样的,最后只会导致结果也是完全一样,后向传播时每层的梯度也都是一样的。这样一来整个网络就是一个完全对称的网络,失去了特征提取的能力,因此显然不能让权重初始化为0。
0方差,1e-2标准差
这个初始化解决了对称的问题,在小型的网络中也适用,但是会导致non-homogeneous distributions(先mark下,到时弄懂了再来补充,知道的读者也可以给我留言,非常感谢)。
接下来我们看下在tanh激活函数下,这种初始化在10层网络中每一层节点的均值与标准差的表现情况。
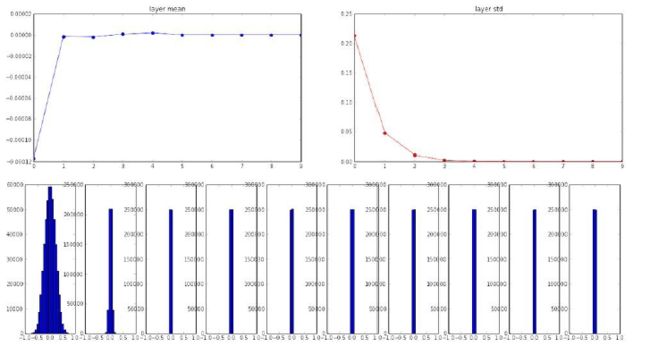
可以看出,一开始数据都还是有一定标准差的(注意图中的数据并非权重的数据),但是随着层数越往后,标准差逐渐消失为0,也就是说到了后面,数据约为0,导致前向传播失败。可以说,因为初始权重的取值太小了,导致计算是数据也变得很小,然后再往后乘上还是很小的权重,而导致最后全都变成了0。
思考
由于最后的值都变成了零,那么由于在BP过程中,我们需要乘于输入的步骤,因此,会导致梯度被扼杀。
0方差,1标准差
吸取上面的教训,我们这次把初始化权重的标准差放大到1来看下吧。下面是与之前一样的例子,不过此时初始权重标准差为1。
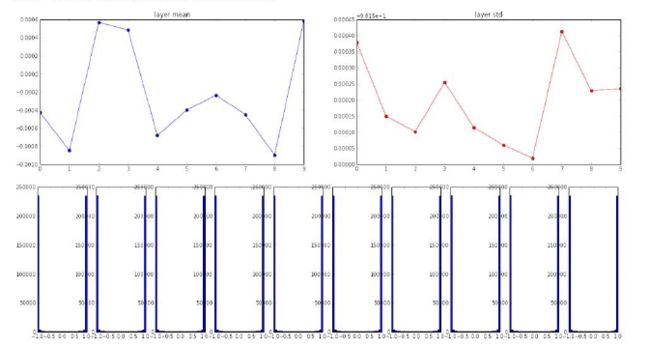
这时我们可以看到,由于初始权重太大了,而导致计算的数据也很大,从而全部处于饱和区(-1或1,别忘了我们这是在tanh激活函数下的例子,不了解的可以看我之前的cs231n笔记)。我们知道,一旦陷入了饱和区,就没有回头的余地了,因为梯度约为0,模型基本就稳定而不继续学习了。
Xavier Initialization
在试过上面的几种情况后,我们基本能看出,初始化权重的标准差不宜太大,也不宜太小,否则模型都会夭折。所以 Glorot et al.于2010年发表了一种有效的初始化方法,成为Xavier Initialization。相比之前的只靠蒙的做法,Xavier方法利用了权重的扇入度作为标准差的衡量。
下面给出Python代码
W = np.random(fan_in, fan_out)/np.sqrt(fan_in)接下来我们看看这种初始化方法的表现

可以看出,在10层里,每一层的数值都有比较好的分布。
似乎这下我们是找到了比较好的方法了,然后我们用ReLU替换tanh看下结果如何。

由于此时ReLU并非以零为中心的,我们可以看到每一层都有大量的数据落到饱和区0处,这显然不是我们所希望看到的。
再改进!
针对上面的问题,2015年He et al.提出了在sqrt(fan_in)里的值再除以2用以改进效果,下面给出python代码
W = np.random(fan_in, fan_out)/np.sqrt(fan_in/2)然后我们来看下在ReLU下的表现

可以到相比之前,现在每一层的均值和方差都有比较好的改进,并且数据在坐标中的分布也比较平均,不会集聚在饱和区。
批归一化:Batch Normalization
然后可能就有读者吐槽了,既然希望每一层都有一个单位高斯分布,那为何不强制把它们处理成单位高斯分布区?
好,这时候loffe和Szegedy在2015年就提出了Batch Normalization的方法,注意这个并非权值初始化,这个是对每层的输出的数值的归一化处理,小心弄混了。
Batch Normalization的步骤与我们前面说到的数据预处理很想
1.zero-centered
2.normalized
3.允许网络对分布有所调整
注意到这里多了两个参数 γ 与 β ,因此我们一般也将BN的过程作为一层网络来处理
下面给出BN的python代码
"""代码来源:github,具体是哪个用户提供的我忘了记下来了"""
def batchnorm_forward(x, gamma, beta, bn_param):
"""
Forward pass for batch normalization.
During training the sample mean and (uncorrected) sample variance are
computed from minibatch statistics and used to normalize the incoming data.
During training we also keep an exponentially decaying running mean of the mean
and variance of each feature, and these averages are used to normalize data
at test-time.
At each timestep we update the running averages for mean and variance using
an exponential decay based on the momentum parameter:
running_mean = momentum * running_mean + (1 - momentum) * sample_mean
running_var = momentum * running_var + (1 - momentum) * sample_var
Note that the batch normalization paper suggests a different test-time
behavior: they compute sample mean and variance for each feature using a
large number of training images rather than using a running average. For
this implementation we have chosen to use running averages instead since
they do not require an additional estimation step; the torch7 implementation
of batch normalization also uses running averages.
Input:
- x: Data of shape (N, D)
- gamma: Scale parameter of shape (D,)
- beta: Shift paremeter of shape (D,)
- bn_param: Dictionary with the following keys:
- mode: 'train' or 'test'; required
- eps: Constant for numeric stability
- momentum: Constant for running mean / variance.
- running_mean: Array of shape (D,) giving running mean of features
- running_var Array of shape (D,) giving running variance of features
Returns a tuple of:
- out: of shape (N, D)
- cache: A tuple of values needed in the backward pass
"""
mode = bn_param['mode']
eps = bn_param.get('eps', 1e-5)
momentum = bn_param.get('momentum', 0.9)
N, D = x.shape
running_mean = bn_param.get('running_mean', np.zeros(D, dtype=x.dtype))
running_var = bn_param.get('running_var', np.zeros(D, dtype=x.dtype))
out, cache = None, None
if mode == 'train':
# Forward pass
# Step 1 - shape of mu (D,)
mu = 1 / float(N) * np.sum(x, axis=0)
# Step 2 - shape of var (N,D)
xmu = x - mu
# Step 3 - shape of carre (N,D)
carre = xmu**2
# Step 4 - shape of var (D,)
var = 1 / float(N) * np.sum(carre, axis=0)
# Step 5 - Shape sqrtvar (D,)
sqrtvar = np.sqrt(var + eps)
# Step 6 - Shape invvar (D,)
invvar = 1. / sqrtvar
# Step 7 - Shape va2 (N,D)
va2 = xmu * invvar
# Step 8 - Shape va3 (N,D)
va3 = gamma * va2
# Step 9 - Shape out (N,D)
out = va3 + beta
running_mean = momentum * running_mean + (1.0 - momentum) * mu
running_var = momentum * running_var + (1.0 - momentum) * var
cache = (mu, xmu, carre, var, sqrtvar, invvar,
va2, va3, gamma, beta, x, bn_param)
elif mode == 'test':
mu = running_mean
var = running_var
xhat = (x - mu) / np.sqrt(var + eps)
out = gamma * xhat + beta
cache = (mu, var, gamma, beta, bn_param)
else:
raise ValueError('Invalid forward batchnorm mode "%s"' % mode)
# Store the updated running means back into bn_param
bn_param['running_mean'] = running_mean
bn_param['running_var'] = running_var
return out, cache
def batchnorm_backward(dout, cache):
"""
Backward pass for batch normalization.
For this implementation, you should write out a computation graph for
batch normalization on paper and propagate gradients backward through
intermediate nodes.
Inputs:
- dout: Upstream derivatives, of shape (N, D)
- cache: Variable of intermediates from batchnorm_forward.
Returns a tuple of:
- dx: Gradient with respect to inputs x, of shape (N, D)
- dgamma: Gradient with respect to scale parameter gamma, of shape (D,)
- dbeta: Gradient with respect to shift parameter beta, of shape (D,)
"""
dx, dgamma, dbeta = None, None, None
mu, xmu, carre, var, sqrtvar, invvar, va2, va3, gamma, beta, x, bn_param = cache
eps = bn_param.get('eps', 1e-5)
N, D = dout.shape
# Backprop Step 9
dva3 = dout
dbeta = np.sum(dout, axis=0)
# Backprop step 8
dva2 = gamma * dva3
dgamma = np.sum(va2 * dva3, axis=0)
# Backprop step 7
dxmu = invvar * dva2
dinvvar = np.sum(xmu * dva2, axis=0)
# Backprop step 6
dsqrtvar = -1. / (sqrtvar**2) * dinvvar
# Backprop step 5
dvar = 0.5 * (var + eps)**(-0.5) * dsqrtvar
# Backprop step 4
dcarre = 1 / float(N) * np.ones((carre.shape)) * dvar
# Backprop step 3
dxmu += 2 * xmu * dcarre
# Backprop step 2
dx = dxmu
dmu = - np.sum(dxmu, axis=0)
# Basckprop step 1
dx += 1 / float(N) * np.ones((dxmu.shape)) * dmu
return dx, dgamma, dbeta后言
在实践中,一般都是使用均值归零,权重初始化一般是由Xavier,然后BN方法一般都要使用,放在FC层或Conv层之后。相信看到这里,读者对权重的初始化和批归一化都有了一个比较直观的了解,下一节我们将讲下剩下的权重更新策略Weights Update的方法以及Dropout。