小白式机器学习 (一) | logistic regression(LR)对数几率回归 / 逻辑回归 公式推导
因为是傻瓜式教程,所以一定会非常详细!一些概念link到了Wiki的相应解释上。
欢迎捉虫~!
二分类和回归的关系
考虑 x⇒y x ⇒ y 表示的二分类或回归问题,其中 x x 是输入, y y 是输出。
1. 在二分类中, y y 的值取0或1,代表被分为正类或负类。在回归中, y y 的取值为连续值。
2. 在线性回归模型中, y=wTx=w⋅x y = w T x = w ⋅ x ,此处 w w 为参数向量, x x 为输入样本向量。
3. 进一步,广义线性回归模型可以写为 g(y)=w⋅x g ( y ) = w ⋅ x 或者 y=g−1(w⋅x) y = g − 1 ( w ⋅ x ) 的形式,其中 g g 为单调可微函数。所以在对数回归中,模型是 ln(y)=w⋅x l n ( y ) = w ⋅ x 。
sigmoid函数与LR的关系
sigmoid函数:在数学上是拥有性感的s形曲线样子的函数:
通常说的sigmoid函数指的是这个logistic函数: δ(z)=11+e−z=ez1+ez δ ( z ) = 1 1 + e − z = e z 1 + e z 。本文所指的sigmoid函数就是该logistic函数:
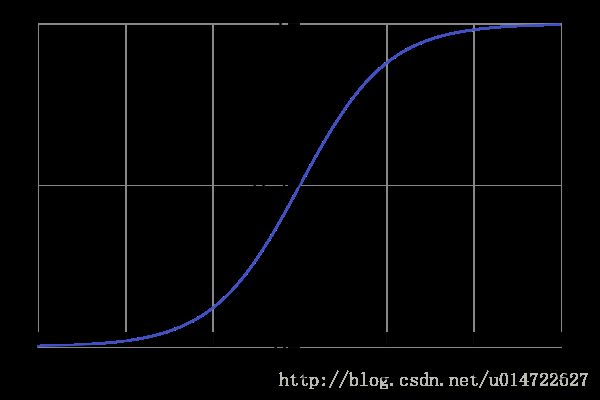
sigmoid函数具有以下特点:
- 值域在(0,1)
- 求导非常容易 δ′(z)=δ(1−δ(z)) δ ′ ( z ) = δ ( 1 − δ ( z ) ) (求导过程见附录,或Wiki)
我们希望在做二分类时,输出 y y 不再是非0即1的取值,而是希望输出一个有概率意义的 (0,1) ( 0 , 1 ) 之间的值,表示的是分为正类的概率(所以 1−y 1 − y 是分为负类的概率),然后再做二分类,所以我们挑选sigmoid函数作为广义线性回归的 g−1 g − 1 ,即
所以,现在 g(y)=ln(y1−y) g ( y ) = l n ( y 1 − y ) 。
前面说到,输出值 y y 代表分到正类的概率, 1−y 1 − y 代表分到负类的概率,那么 y1−y=正类概率负类概率 y 1 − y = 正 类 概 率 负 类 概 率 ,称为 几率, ln(y1−y) l n ( y 1 − y ) 称为 对数几率(logit)。 (2) ( 2 ) 的本质是用 w⋅x w ⋅ x 线性回归模型逼近对数几率,我们管这叫 对数几率回归( logit regression / logistics regression)。
条件概率
- y y 代表分到正类的概率,即为条件概率: P(y=1|x) P ( y = 1 | x ) 。
1−y 1 − y 代表分到负类的概率,即为条件概率: P(y≠1|x)=P(y=0|x)=1−P(y=1|x) P ( y ≠ 1 | x ) = P ( y = 0 | x ) = 1 − P ( y = 1 | x ) 。 - 我们有 P(y=1|x)=y=11+e−w⋅x P ( y = 1 | x ) = y = 1 1 + e − w ⋅ x
- 假设数据集共有 N N 个样本,记第i个样本输入(m维向量)和样本标签分别为 xi=[xi(1),xi(2),...,xi(m)]T,yi={0,1} x i = [ x i ( 1 ) , x i ( 2 ) , . . . , x i ( m ) ] T , y i = { 0 , 1 } 。条件概率其实和参数 w w 有关,那么正确分类的条件概率应该写为: P(y=yi|x=xi;w) P ( y = y i | x = x i ; w ) ,简记为 P(yi|xi;w) P ( y i | x i ; w ) 。
(意思是输入变量 x x 取 xi x i 时,输出 y y =真实标签 yi y i 的概率) 正确分类概率P(yi|xi;w)={P(y=1|xi;w),P(y=0|xi;w)=1−P(y=1|xi;w),if yi=1 if yi=0 正 确 分 类 概 率 P ( y i | x i ; w ) = { P ( y = 1 | x i ; w ) , if y i = 1 P ( y = 0 | x i ; w ) = 1 − P ( y = 1 | x i ; w ) , if y i = 0
ln[P(yi|xi;w)]={ln[P(y=1|xi;w)],ln[[P(y=0|xi;w)]=ln[1−P(y=1|xi;w)],if yi=1 if yi=0 l n [ P ( y i | x i ; w ) ] = { l n [ P ( y = 1 | x i ; w ) ] , if y i = 1 l n [ [ P ( y = 0 | x i ; w ) ] = l n [ 1 − P ( y = 1 | x i ; w ) ] , if y i = 0
- 也等价于 lnP(y=yi|xi;w)={yi=1}lnP(y=1|xi;w)+{yi=0}ln(1−P(y=1|xi;w)) l n P ( y = y i | x i ; w ) = { y i = 1 } l n P ( y = 1 | x i ; w ) + { y i = 0 } l n ( 1 − P ( y = 1 | x i ; w ) )
其中 {yi=1} { y i = 1 } 称为示性函数,当条件被满足就取1,否则取0。
在二分类型况下,怎么样的函数能满足这样的条件呢? yi y i 和 1−yi 1 − y i 就可以呀!
ln[P(yi|xi;w)]=(yi)ln[P(y=1|xi;w)]+(1−yi)ln[1-P(y=1|xi;w)](3) (3) l n [ P ( y i | x i ; w ) ] = ( y i ) l n [ P ( y = 1 | x i ; w ) ] + ( 1 − y i ) l n [ 1 - P ( y = 1 | x i ; w ) ]
从原始概率来看,即
最大似然求解
似然的解释见附录或Wiki
我们希望,求得参数 w w ,使“抽取的样本 xi x i 属于本身的标签 yi y i 的概率最大 ”即 P(yi|xi;w) P ( y i | x i ; w ) 尽量大。
换句话说,就是极大化对数似然 L(w) L ( w ) :
那么我们的目标就是
(4) ( 4 ) 中我们用到 ln(ab)=ln(a)+ln(b) l n ( a b ) = l n ( a ) + l n ( b ) ,是因为连乘比起连加,求最优的难度更大,所以用对数函数转换一下,方便求解。
将 (3) ( 3 ) 带入 (4) ( 4 ) ,得:
化简:
我们有 P(y=1|x;w)=y=11+e−w⋅x P ( y = 1 | x ; w ) = y = 1 1 + e − w ⋅ x
回忆 (2),ln(P(y=1|xi;w)1−P(y=1|xi;w)) ( 2 ) , l n ( P ( y = 1 | x i ; w ) 1 − P ( y = 1 | x i ; w ) ) 实际就是 w⋅xi w ⋅ x i 嘛!
最终目标函数成了最小化这个loss了,如何最小化?它关于x可导又连续,学过凸优化的都知道怎么做了吧?牛顿法、梯度下降等可以迭代求解最优。从搞神经网络的角度看,sigmoid是经典的激活函数,LR完全可以等价成一层的神经网络,激活函数是sigmoid!这里回忆一下,sigmoid函数的优良性质之一:导数好求。所以对于一切需要求梯度的方法,代码实现的难度就降低了。
附录
sigmoid函数求导
记 f=δ(x) f = δ ( x )
求导公式:(1f)′=−1f2; g(f)′=g′f⋅f′ 求 导 公 式 : ( 1 f ) ′ = − 1 f 2 ; g ( f ) ′ = g ′ f ⋅ f ′
似然
我们从机器学习的角度看
- 记 θ θ 为模型(参数)。
- 记 D D 为训练数据集,是真实数据空间的抽样集合,训练数据集越大,D的分布越接近真实数据空间的分布。
记 x x 为一个观测,也可以理解为一个训练样本,是真实数据空间的一个抽样,即随机变量X的一个取值。
似然/似然函数(likelihood):给定参数时,事件出现的可能性。
“似然”和“概率”可以算作同义词。通常,似然用于数据已知时描述模型参数(数据已知了还要描述数据出现的可能性,可不是就和参数有关嘛)。而概率通常用于描述未知的事件出现的可能性。似然的举例如下:- 当假设数据集中的每个样本在样本空间中都是独立的时候,参数 θ θ 相对于样本集 D={x1,x2,x3,...,xn} D = { x 1 , x 2 , x 3 , . . . , x n } 的似然为 L(θ)=P(x1,x2,x3,...,xn|θ)=∏niP(xi|θ) L ( θ ) = P ( x 1 , x 2 , x 3 , . . . , x n | θ ) = ∏ i n P ( x i | θ )
- 参数 θ θ 相对于一个观测 x x 的似然为 L(θ)=P(x|θ) L ( θ ) = P ( x | θ )
L(θ) L ( θ ) 是一个关于 θ θ 的函数。特别的,当 θ θ 是随机变量时, L(θ) L ( θ ) 是条件概率 P(X=x|θ) P ( X = x | θ ) ,也可以写为 P(X=x;θ) P ( X = x ; θ ) 。
- 贝叶斯推理的观点:
θ θ 是服从分布 pθ p θ 的随机变量,分布 pθ p θ 是关于模型的假设,称为先验,先验概率(piror probability)也记为 p(θ) p ( θ ) ;给定数据集能得到模型 θ θ 的概率 P(θ|D) P ( θ | D ) 称为后验概率(posterior probability);参数 θ θ 下数据集样本都在观测都出现的概率 P(x|θ) P ( x | θ ) 为似然(likelihood);数据集的联合概率为 P(D) P ( D ) 。
Reference:
周志华 -《机器学习》
ufldl - softmax
图片均来自维基百科