- 预处理
数据集使用Facebook上的BABI数据集
将文件提取成可训练的数据集,包括:文章 问题 答案
def get_data(infile):
stories,questions,answers = [],[],[]
story_text = []
fin = open(infile,'rb')
for line in fin:
line = line.decode('utf-8').strip()
lno,text = line.split(' ',1)
if '\t' in text:
question,answer,_ = text.split('\t')
stories.append(story_text)
questions.append(question)
answers.append(answer)
story_text = []
else:
story_text.append(text)
fin.close()
return stories,questions,answers
data_train = get_data('qa1_single-supporting-fact_train.txt')
data_test = get_data('qa1_single-supporting-fact_test.txt')
print('\nTrain observations:',len(data_train[0]),
'Test observations:',len(data_test[0]),'\n')输出:
Train observations: 10000 Test observations: 1000- 如何实现
1.预处理:创建字典并将文章,问题和答案映射到词表,进一步映射成向量形式
2.模型创建和验证:训练模型并在验证数据集上测试
3.预测结果:测试集测试数据的结果 - 代码
from __future__ import division,print_function
import collections
import itertools
import nltk
import numpy as np
import matplotlib.pyplot as plt
import os
import random
def get_data(infile):
stories,questions,answers = [],[],[]
story_text = []
fin = open(infile,'rb')
for line in fin:
line = line.decode('utf-8').strip()
lno,text = line.split(' ',1) # 去掉前面的数字标记
if '\t' in text: # 有制表符的是 问题 和 答案
question,answer,_ = text.split('\t')
stories.append(story_text)
questions.append(question)
answers.append(answer)
story_text = []
else: # 没制表符的是文章
story_text.append(text)
fin.close()
return stories,questions,answers
data_train = get_data('qa1_single-supporting-fact_train.txt')
data_test = get_data('qa1_single-supporting-fact_test.txt')
print('\nTrain observations:',len(data_train[0]),
'Test observations:',len(data_test[0]),'\n')
print(data_train[0][1],data_train[1][1],data_train[2][1])
# ['Daniel went back to the hallway.', 'Sandra moved to the garden.'] Where is Daniel? hallway
print(np.array(data_train).shape)
# (3, 10000)
dictnry = collections.Counter() # 返回列表元素出现次数的 字典,这里没有参数是一个空字典
for stories,questions,answers in [data_train,data_test]:
for story in stories:
for sent in story:
for word in nltk.word_tokenize(sent):
dictnry[word.lower()] += 1
for question in questions:
for word in nltk.word_tokenize(question):
dictnry[word.lower()] += 1
for answer in answers:
for word in nltk.word_tokenize(answer):
dictnry[word.lower()] += 1
word2indx = {w:(i+1) for i,(w,_) in enumerate(dictnry.most_common())} # 按词频排序
word2indx['PAD'] = 0
indx2word = {v:k for k,v in word2indx.items()}
vocab_size = len(word2indx) # 一共有22个不重复单词
print('vocabulary size:',len(word2indx))
story_maxlen = 0
question_maxlen = 0
for stories,questions,answers in [data_train,data_test]:
for story in stories:
story_len = 0
for sent in story:
swords = nltk.word_tokenize(sent)
story_len += len(swords)
if story_len > story_maxlen:
story_maxlen = story_len
for question in questions:
question_len = len(nltk.word_tokenize(question))
if question_len > question_maxlen:
question_maxlen = question_len
print('Story maximum length:',story_maxlen,'Question maximum length:',question_maxlen)
# 文章单词最大长度为14,问题中的单词最大长度为4,长度不够的补0,维度相同便于并向计算
from keras.layers import Input
from keras.layers.core import Activation,Dense,Dropout,Permute
from keras.layers.embeddings import Embedding
from keras.layers.merge import add,concatenate,dot
from keras.layers.recurrent import LSTM
from keras.models import Model
from keras.preprocessing.sequence import pad_sequences
from keras.utils import np_utils
def data_vectorization(data,word2indx,story_maxlen,question_maxlen): # 词 => 词向量
Xs,Xq,Y = [],[],[]
stories,questions,answers = data
for story,question,answer in zip(stories,questions,answers):
xs = [[word2indx[w.lower()] for w in nltk.word_tokenize(s)] for s in story] #
xs = list(itertools.chain.from_iterable(xs))
xq = [word2indx[w.lower()] for w in nltk.word_tokenize(question)]
Xs.append(xs)
Xq.append(xq)
Y.append(word2indx[answer.lower()])
return pad_sequences(Xs,maxlen=story_maxlen),pad_sequences(Xq,maxlen=question_maxlen),\
np_utils.to_categorical(Y,num_classes=len(word2indx))
Xstrain,Xqtrain,Ytrain = data_vectorization(data_train,word2indx,story_maxlen,question_maxlen)
Xstest,Xqtest,Ytest = data_vectorization(data_test,word2indx,story_maxlen,question_maxlen)
print('Train story',Xstrain.shape,'Train question',Xqtrain.shape,'Train answer',Ytrain.shape)
print('Test story',Xstest.shape,'Test question',Xqtest.shape,'Test answer',Ytest.shape)
# 超参数
EMBEDDING_SIZE = 128
LATENT_SIZE = 64
BATCH_SIZE = 64
NUM_EPOCHS = 40
# 输入层
story_input = Input(shape=(story_maxlen,))
question_input = Input(shape=(question_maxlen,))
# Story encoder embedding
# 将正整数(索引)转换为固定大小的密集向量。
# 例如,[[4],[20]]->[[0.25,0.1],[0.6,-0.2]] 此层只能用作模型中的第一层
story_encoder = Embedding(input_dim=vocab_size,output_dim=EMBEDDING_SIZE,input_length=story_maxlen)(story_input)
story_encoder = Dropout(0.2)(story_encoder)
# Question encoder embedding
question_encoder = Embedding(input_dim=vocab_size,output_dim=EMBEDDING_SIZE,input_length=question_maxlen)(question_input)
question_encoder = Dropout(0.3)(question_encoder)
# 返回两个张量的点积
match = dot([story_encoder,question_encoder],axes=[2,2])
# 将故事编码为问题的向量空间
story_encoder_c = Embedding(input_dim=vocab_size,output_dim=question_maxlen,input_length=story_maxlen)(story_input)
story_encoder_c = Dropout(0.3)(story_encoder_c)
# 结合两个向量 match和story_encoder_c
response = add([match,story_encoder_c])
response = Permute((2,1))(response)
# 结合两个向量 response和question_encoder
answer = concatenate([response, question_encoder], axis=-1)
answer = LSTM(LATENT_SIZE)(answer)
answer = Dropout(0.2)(answer)
answer = Dense(vocab_size)(answer)
output = Activation("softmax")(answer)
model = Model(inputs=[story_input, question_input], outputs=output)
model.compile(optimizer="adam", loss="categorical_crossentropy",metrics=["accuracy"])
print(model.summary())
# 模型训练
history = model.fit([Xstrain,Xqtrain],[Ytrain],batch_size=BATCH_SIZE,epochs=NUM_EPOCHS,
validation_data=([Xstest,Xqtest],[Ytest]))
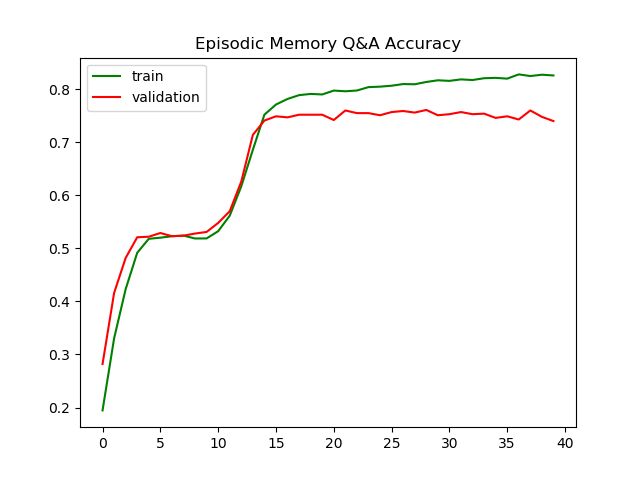
# 画出准确率和损失函数
plt.title('Episodic Memory Q&A Accuracy')
plt.plot(history.history['acc'],color='g',label='train')
plt.plot(history.history['val_acc'],color='r',label='validation')
plt.legend(loc='best')
plt.show()
# get predictions of labels
ytest = np.argmax(Ytest, axis=1)
Ytest_ = model.predict([Xstest, Xqtest])
ytest_ = np.argmax(Ytest_, axis=1)
# 随机选择几个问题测试
NUM_DISPLAY = 10
for i in random.sample(range(Xstest.shape[0]),NUM_DISPLAY):
story = " ".join([indx2word[x] for x in Xstest[i].tolist() if x != 0])
question = " ".join([indx2word[x] for x in Xqtest[i].tolist()])
label = indx2word[ytest[i]]
prediction = indx2word[ytest_[i]]
print(story, question, label, prediction)输出: