本文为博主翻译自:Jinwon的Variational Autoencoder based Anomaly Detection using Reconstruction Probability,如侵立删
http://dm.snu.ac.kr/static/docs/TR/SNUDM-TR-2015-03.pdf
摘要
我们提出了一种利用变分自动编码器重构概率的异常检测方法。重建概率是一种考虑变量分布变异性的概率度量。重建概率具有一定的理论背景,使其比重建误差更具有原则性和客观性,而重建误差是自动编码器(AE)和基于主成分(PCA)的异常检测方法所采用的。实验结果表明,所提出的方法形成了基于自动编码器的方法和基于主成分的方法。利用变分自动编码器的生成特性,可以推导出数据重构,分析异常的根本原因。
1 简介
异常或异常值是与剩余数据显着不同的数据点。 霍金斯将异常定义为一种观察结果,它与其他观察结果有很大的偏差,从而引起人们怀疑它是由不同的机制产生的[5]。 分析和检测异常非常重要,因为它揭示了有关数据生成过程特征的有用信息。 异常检测应用于网络入侵检测,信用卡欺诈检测,传感器网络故障检测,医疗诊断等众多领域[3]。
在许多异常检测方法中,光谱异常检测技术试图找到原始数据的低维嵌入,其中异常和正常数据预期彼此分离。 在找到那些较低维度的嵌入之后,它们被带回原始数据空间,这被称为原始数据的重建。 通过使用低维表示重建数据,我们期望获得数据的真实性质,而没有不感兴趣的特征和噪声。 数据点的重建误差(原始数据点与其低维重建之间的误差)被用作检测异常的异常分数。 基于主成分分析(PCA)的方法属于这种检测异常的方法[3]。
随着深度学习的出现,自动编码器还用于通过堆叠层来形成深度自动编码器来执行降维。 通过减少隐藏层中的单元数量,预计隐藏单元将提取很好地表示数据的特征。此外,通过堆叠自动编码器,我们可以以分层方式应用降维,在更高的隐藏层中获得更抽象的特征,从而更好地重建数据。
在这项研究中,我们提出了一种使用变分自动编码器(VAE)的异常检测方法[8]。 变分自动编码器是一种将变分推理与深度学习相结合的概率图形模型。 因为VAE以概率上合理的方式减小尺寸,所以理论基础是坚定的。 VAE相对于自动编码器和PCA的优势在于它提供概率测量而不是重建误差作为异常分数,我们称之为重建概率。 概率比重建误差更具原则性和客观性,并且不需要模型特定阈值来判断异常。
2 背景
2.1 异常检测
异常检测方法可以大致分为基于统计,基于邻近和基于偏差[1]三种类型。
统计异常检测假定数据是根据指定的概率分布建模的。诸如高斯混合的参数模型或诸如核密度估计的非参数模型可用于定义概率分布。 如果数据点从模型生成的概率低于某个阈值,则将数据点定义为异常。这种模型的优点在于它给出概率作为判断异常的决策规则,这是客观的,理论上合理的。
基于邻近度的异常检测假设异常数据与大量数据隔离。以这种方式对异常建模有三种方式,即基于聚类,基于密度和基于距离。对于基于聚类的异常检测,将聚类算法应用于数据以识别数据中存在的密集区域或聚类。接下来,评估数据点与每个聚类的关系以形成异常分数。这样的标准包括到聚类质心的距离和最近聚类的大小。如果到集群质心的距离高于阈值或者最近集群的大小低于阈值,则将数据点定义为异常。基于密度的异常检测将异常定义为位于数据的稀疏区域中的数据点。例如,如果数据点的局部区域内的数据点的数量低于阈值,则将其定义为异常。基于距离的异常检测使用与给定数据点的相邻数据点相关的测量。可以以这样的方式使用K-最近邻距离,其中具有大k-最近邻距离的数据点被定义为异常。
基于偏差的异常检测主要基于光谱异常检测,其使用重建误差作为异常分数。 第一步是使用降维方法(如主成分分析或自动编码器)重建数据。 使用k个最重要的主成分重建输入并测量其原始数据点和重建之间的差异导致重建误差,其可以用作异常分数。 具有高重建误差的数据点被定义为异常。
2.2 AE与异常检测
自动编码器是通过无监督学习训练的神经网络,其被训练以学习接近其原始输入的重建。 自动编码器由两部分组成,编码器和解码器。 具有单个隐藏层的神经网络分别具有如等式(1)和等式(2)中的编码器和解码器。 W和b是神经网络的权重和偏差,σ是非线性变换函数。
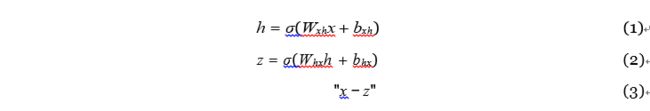
等式(1)中的编码器通过非线性之后的仿射映射将输入矢量x映射到隐藏表示h。 等式(2)中的解码器通过与编码器相同的变换将隐藏表示h映射回原始输入空间作为重建。 原始输入矢量x和重建z之间的差异被称为重建误差,如等式(3)中所示。 自动编码器学习最小化该重建误差。 普通自动编码器的训练算法如算法1所示,其中fθ和gφ是自动编码器的多层神经网络。
通过使用自动编码器的隐藏表示作为另一个自动编码器的输入,我们可以堆叠自动编码器以形成深度自动编码器[16]。 为了避免隐藏单元的简单查找表格表示,自动编码器减少了隐藏单元的数量。 还开发了具有各种其他正则化的自动编码器。 压缩自动编码器使用激活梯度作为惩罚项,并尝试使用仅响应数据真实性质的稀疏激活来建模数据[13]。 去噪自动编码器使用向原始输入向量x添加噪声并使用该有噪声输入x作为输入向量。 结果输出,噪声输入的重建和原始输入之间的差异被用作重建误差。 简而言之,这是训练自动编码器从嘈杂的输入x再现原始输入x。 这允许自动编码器对具有白噪声的数据具有鲁棒性,并且仅捕获有意义的数据模式[16]。

基于自动编码器的异常检测是基于偏差的使用半监督学习的异常检测方法。 它使用重建误差作为异常分数。 具有高重建的数据点被认为是异常。 仅使用具有普通实例的数据来训练自动编码器。 训练之后,自动编码器将非常好地重建正常数据,而自动编码器未遇到的异常数据则会重建失败。 算法2演示出了使用自动编码器的重建误差的异常检测算法。

2.3 变分自编码器
变分自动编码器(VAE)是一种定向概率图形模型(DPGM),其后置由神经网络近似,形成类似自动编码器的架构。 图1显示了典型的定向图形模型。 在VAE中,有向图形模型z的最高层被视为生成过程开始的潜在变量。 g(z)表示数据生成的复杂过程,其导致数据x,其在神经网络的结构中建模。 VAE的目标函数是数据边际可能性的变化下界,因为边际可能性是难以处理的。 边际可能性是各个数据点![]() 的边际可能性之和,其中各个数据点的边际可能性可以如下重写:
的边际可能性之和,其中各个数据点的边际可能性可以如下重写:
![]()
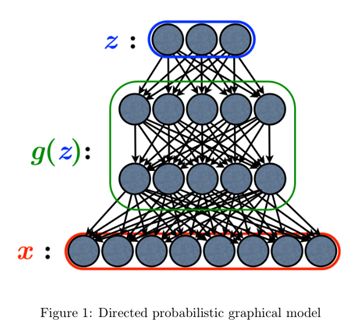
qφ(z | x)是近似后验,pθ(z)是潜在变量z的先验分布。 等式(4)右边的第一项是近似后验和先验的KL散度。 等式(4)右边的第二项是数据点i的边际似然的变化下界。 由于KL发散项总是大于0,所以可以如下重写等式(4)。
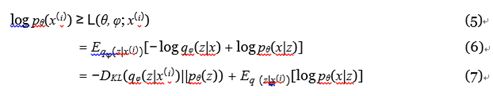
pθ(x | z)是给定潜在变量z的数据x的似然性。 等式(7)的第一项是潜在可变z的近似后验和先验之间的KL散度。 该术语迫使后验分布与先前分布相似,作为正则化项。 等式(7)的第二项可以通过后验分布qφ(z | x)和似然pθ(x | z)的x重构来理解。
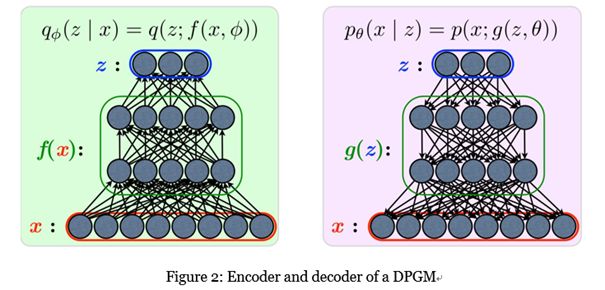
VAE通过使用神经网络模拟近似后验qφ(z | x)的参数。这是VAE与自动编码器相关的地方。如图2所示,在自动编码器类比中,近似后验qφ(z | x)是编码器,定向概率图模型pθ(x | z)是解码器。值得强调的是,VAE模拟分布的参数而不是值本身。也就是说,编码器中的f(x,φ)输出近似后验qφ(z | x)的参数并获得潜在变量z的实际值,从q(z; f(x,φ))中采样是必须的。因此,VAE的编码器和解码器可以被称为概率编码器和解码器。作为神经网络的f(x,φ)表示数据x和潜在变量z之间的复杂关系。为了得到重构x,给定样本z,通过g(z,θ)获得pθ(x | z)的参数,其中从pθ(x; g(z,θ))对重建x进行采样。总而言之,它是在VAE中建模的分布参数,而不是值本身。分布的选择对任何类型的参数分布都是开放的。对于潜在变量z的分布,即pθ(z)和qφ(z | x),常见的选择是各向同性法线,因为假设潜变量空间中变量之间的关系比原始输入数据空间。似然pθ(x | z)的分布,图3取决于数据的性质。如果数据是二进制形式,则使用伯努利分布。如果数据是连续的,则使用多变量高斯。图3显示了整个VAE的结构。
VAE和自动编码器之间的主要区别在于VAE是一种可以提供校准概率的随机生成模型,而自动编码器是一种没有概率基础的确定性判别模型。 这是显而易见的,因为VAE模拟分布的参数,如上所述。
反向传播用于训练VAE。 由于等式(7)的第二项应通过蒙特卡罗方法计算,因此必须使用蒙特卡罗梯度法。 然而,众所周知,用于优化变分下界的传统蒙特卡罗梯度方法存在非常高的方差,因此不适合使用[10]。 VAE通过使用重新参数化技巧克服了这一点,该技巧使用来自标准正态分布的随机变量而不是原始分布中的随机变量。 随机变量z~qφ(z | x)通过确定性变换hφ(s,x)重新定量,其中s来自标准正态分布。
![]()
重新计量应确保z~遵循qφ(z | x)的分布。 这比直接使用蒙特卡罗梯度法更稳定。 用于训练VAE的算法在算法3中示出。

3 提议方案
我们提出了一种异常检测方法,该方法使用VAE来计算我们称之为重建概率的概率的异常分数。
3.1 算法
该方法的算法在算法4中。异常检测任务是一个半监督框架,仅使用正常实例的数据来训练VAE。概率编码器fφ和解码器gθ分别对潜在变量空间和原始输入变量空间中的各向同性正态分布进行参数化。为了测试,从训练的VAE的概率编码器中抽取许多样本。对于来自编码器的每个样本,概率解码器输出均值和方差参数。使用这些参数,计算从分布产生原始数据的概率。平均概率用作异常分数,称为重建概率。这里计算的重建概率是等式(7)的右手侧的第二项Eqφ(z|x)[log pθ(x|z)]的蒙特卡洛估计。具有高重建概率的数据点被归类为异常。

3.2 重建概率
通过导出原始输入变量分布的参数的随机潜变量来计算重建概率。正在重建的是输入变量分布的参数,而不是输入变量本身。这基本上是从近似后验分布中提取的给定潜在变量生成数据的概率。因为从潜在变量分布中抽取了许多样本,这允许重建概率考虑潜在变量空间的可变性,这是所提出的方法与基于自动编码器的异常检测之间的主要区别之一。可以使用适合数据的输入变量空间的其他分布。对于连续数据,可以如算法4中那样使用正态分布。对于二进制数据,可以使用伯努利分布。在潜在可变空间分布的情况下,优选诸如各向同性正态分布的简单连续分布。这可以通过光谱异常检测的假设来证明,与输入变量空间相比,潜变量空间更加简单。
3.3 与基于自动编码器的异常检测的区别
重建概率与自动编码器的重建误差有两种不同。 首先,潜在变量是随机变量。 在自动编码器中,潜在变量由确定性映射定义。然而,由于VAE使用概率编码器来模拟潜在变量的分布而不是潜在变量本身,因此可以从采样过程考虑潜在空间的可变性。与自动编码器相比,这扩展了VAE的表现力,即使正常数据和异常数据可能共享相同的平均值,变化也可能不同。 据推测,异常数据将具有更大的方差并且显示出更低的重建概率。由于自动编码器的确定性映射可以被认为是映射到狄拉克δ分布的平均值,因此自动编码器缺乏解决可变性的能力。
其次,重建是随机变量。重建概率不仅考虑重建与原始输入之间的差异,而且还考虑通过考虑分布函数的方差参数来重建的可变性。 该属性使得能够根据变量方差对重建具有选择性灵敏度。 具有大方差的变量将容忍重建中的大差异和原始数据作为正常行为,而具有小方差的变量将显著降低重建概率。这也是自动编码器由于其确定性而缺乏的特征。
第三,重建是概率测量。基于自动编码器的异常检测使用重建误差作为异常分数,如果输入变量是异构的,则难以计算。为了总结异构数据的差异,需要加权和。问题是,没有一种通用的客观方法来确定适当的权重,因为权重将根据您拥有的数据而有所不同。此外,即使在确定权重之后,确定重建误差的阈值也是麻烦的。没有明确的目标切割阈值。相反,重建概率的计算不需要加权异构数据的重建误差,因为每个变量的概率分布允许它们通过其自身的可变性单独地计算。对于任何数据,1%的概率总是1%。因此,确定重建误差的阈值比重建误差更客观,合理且易于理解。
4 实验结果
将基于VAE的具有重建概率的异常检测与基于自动编码器和基于PCA的方法的其他基于重建的方法进行比较。
4.1 数据集准备
用于异常检测的数据集是MNIST数据集[9]和KDD杯1999网络入侵数据集(KDD)[6]。 数据集根据其类标签分为普通数据和异常数据。 为了应用半监督学习,训练数据由80%的正常数据组成,测试数据由剩余的20%的正常数据和所有异常数据组成。 因此,模型仅使用正常数据进行训练,并使用正常和异常数据进行测试。
对于MNIST数据集,训练模型,每个数字类别标记为异常,其他数字标记为正常。 这导致数据集具有10个不同的异常。 我们将被标记为异常的数字类i称为异常数字i。 数据总数为60,000,每个数字的实例数相同。 仅应用最小最大缩放作为预处理,以使每个像素值在0和1之内。
KDD杯数据集由五个主要类别组成,分别是DoS,R2L,U2R,Probe和Normal。前4个类是异常,而Normal类是正常的。前4个类中的每一个都被视为异常。对于每个异常类,正常数据以两种不同的方式定义。第一种是将普通数据定义为仅具有Normal类的数据。由于模型仅使用正常数据进行训练,因此每个异常类产生相同的模型。普通数据的另一个定义是除指定的异常类之外的所有数据。这为每个异常类产生不同的训练数据,并且还具有比正常数据的前一个定义更多的训练数据。我们将第一种定义普通数据的方法称为普通方法,第二种方法除了异常方法外都会被调用。表1中显示了每个类的实例数。对于分类变量,使用一个热编码将其转换为数值。对于数值变量,将0均值和单位方差的标准化应用为预处理。
4.2 模型准备
对于VAE,编码器和解码器都是具有400维度的单个隐藏层。 潜在尺寸为200维。 对于自动编码器(AE),我们使用了两个隐藏层去噪自动编码器,分别用于第一和第二隐藏层的400,200维度。 通过堆叠前一层输出来训练第二层。 对于PCA,我们使用线性PCA(PCA)和具有高斯内核的内核PCA(kPCA)。 使用交叉验证估计高斯核的参数。 VAE使用重建概率作为异常分数,而其他模型使用重建误差作为异常分数。
4.3 效果评估
接收器操作特性曲线下面积(AUC ROC)和精确召回曲线(AUC PRC)和f1得分曲线下的平均精度或面积用于评估。 通过从验证数据集f1得分确定二元决策的阈值来获得f1得分。
4.3.1 MNIST 数据集
表2显示了异常数据集的每个模型的性能。 VAE在大多数时候都优于其他型号。 对于所有型号,性能较低当数字1,7和9是异常数字时。 详细的VAE的其他性能测量结果如表3所示。可以看出,数字1和7,9是异常数字的情况在AUC PRC中表现出低的性能,并且f1得分也是如此。 这似乎与数据结构本身难以重建的方式有关。 分析重建揭示了这个结果的可能原因。
4.3.2 重建 MNIST dataset
图4显示了每个异常数字具有低重建概率的数据样本及其重建。 也就是说,它显示了每个异常数字数据的检测到的异常。 可以很容易地注意到,除了1,7和9之外,VAE不能很好地重建异常数字的数据,正确地导致将其定义为异常。 对于异常数字1,可以看出1未被检测为异常。 图7和9也类似地跟随被判断为异常的其他数字。 如果我们看到数据样本及其重建对于图5中所示的每个异常数字具有高重建概率,则可以理解VAE不对这些数字起作用的原因。即,这些数据样本被判断为正常数据。
除异常数字1之外的所有异常数字仅显示具有最高重建概率的1的样本。 即使在1处于异常数据中并且没有给予训练数据的情况下,如异常数字1显示1具有7和9具有高重建概率。
由此可以推断,由于1是单个垂直笔划的结构非常简单,因此VAE从数据的其他部分学习了该结构。例如,如果以刚性方式书写而没有太多曲率,则几乎任何数字,4中心,7和9右侧包括垂直笔划。这可能为VAE提供了学习结构组件的数据。即使在这个实验中使用的VAE是一个相当浅的有三个隐藏层,但它似乎仍然作为一个分层模型捕获构成数据结构的功能。当查看图5中所示的异常数字1的样本时,这是显而易见的,其中当1不存在时,7和9似乎具有高重建概率。异常数字7和9的低性能可以以类似的含义理解。垂直笔划占7和9的很大一部分,因为与其他数字相比,它与垂直笔划相比具有较少的突出部分,如图5所示。另外对于7,似乎是一种特殊的书写方式7(第二个水平方向)数字7)中间的笔划似乎被检测为异常。

Figure 4: Reconstruction of digits with low reconstruction
上排部分是异常数字0到4的重建。下排部分,5到9.每个部分的左列是原始数据,右列是重建

Figure 5: Reconstruction of digits with high reconstruction probability
与图4相同的
4.4 KDD 数据集
表4和表5显示了异常数据集上每个模型的VAE性能。 表4是仅使用Normal类数据训练的模型。 无论异常类如何,所有模型都使用相同的数据集进行训练。 表5是使用除异常类数据之外的所有数据训练的模型,这意味着模型的训练数据因异常类而不同。 VAE的表现优于其他模型,除了训练的情况,只有普通类,探测作为他们处于同等水平的异常类。 PCA似乎缺乏性能,暗示数据的线性关系不足以捕获数据的底层结构。 内核PCA也没有太大成功。
4.4.1 正态唯一法与异常例外法的比较
除了异常类是DoS的情况之外,异常除了方法之外表现出更好的性能。 这可能是因为DoS类是具有最多实例的类。 表1显示DoS类数据占总数据的近80%。 不使用DoS类数据来训练VAE会严重影响VAE,从而导致模型无法将DoS类数据与其他类区分开来。 对于其他异常类,结合其他数据,最值得注意的是,庞大的DoS类数据有助于提高常规方法的性能,其中仅具有正常数据的模型是训练数据。 还可以看出异常自动编码器除异常类R2L,U2R和几乎匹配探测器外,异常的自动编码器在异常类方法中表现出比VAE更好的性能。 这举例说明了公理,更多数据通常比更好的算法更好。
4.4.2 异常等级比较
表6和表7显示了VAE的其他性能评估指标。 DoS显示出高AUC ROC和高AUC PRC。 但对于R2L和U2R,AUC ROC评分良好,但AUC PRC评分较差。 这是由于R2L和U2R类的大小。 AUC ROC没有考虑实际的数据数量,而是考虑了数据的百分比。 这使得非常小的异常数据在AUC ROC方面表现更好。 但是,AUC PRC考虑了异常类的实际数据。 由于数据太少,模型很难将它们与普通数据区分开来。 U2R只有520个样本,占总数据的0.001%。 这使得AUC PRC非常低。 即使f1得分(AUC PRC的峰值)比AUC PRC大得多,但与其他异常类别相比仍然较低。
5 结论
我们已经使用来自变分自动编码器的重建概率引入了异常检测方法。 重建概率通过考虑变异性的概念来结合变分自动编码器的概率特性。 作为概率测量的重建概率使其成为比自动编码器和基于PCA的方法的重建误差更客观和原则性的异常分数。 实验结果表明,该方法优于基于自动编码器和基于PCA的方法。 由于其生成特征,还可以导出数据的重建以分析异常的根本原因。
翻译的比较初略,错误的比较多,希望大佬们谅解。
参考
[1] Charu C Aggarwal. Outlier analysis. Springer Science & Business Media, 2013.
[2] Pierre Baldi and Kurt Hornik. Neural networks and principal component analysis: Learning from examples without local minima. Neural networks, 2(1):53–58, 1989.
[3] Varun Chandola, Arindam Banerjee, and Vipin Kumar. Anomaly detection: A survey.
ACM computing surveys (CSUR), 41(3):15, 2009.
[4] Junyoung Chung, Kyle Kastner, Laurent Dinh, Kratarth Goel, Aaron C Courville, and Yoshua Bengio. A recurrent latent variable model for sequential data. In Advances in Neural Information Processing Systems, pages 2962–2970, 2015.
[5] Douglas M Hawkins. Identification of outliers, volume 11. Springer, 1980.
[6] Seth Hettich and SD Bay. The uci kdd archive [http://kdd. ics. uci. edu]. irvine, ca: University of california. Department of Information and Computer Science, page 152, 1999.
[7] Diederik P Kingma, Shakir Mohamed, Danilo Jimenez Rezende, and Max Welling. Semi- supervised learning with deep generative models. In Advances in Neural Information Pro- cessing Systems, pages 3581–3589, 2014.
[8] Diederik P Kingma and Max Welling. Auto-encoding variational bayes. arXiv preprint arXiv:1312.6114, 2013.
[9] Yann LeCun and Corinna Cortes. Mnist handwritten digit database. AT&T Labs [Online]. Available: http://yann. lecun. com/exdb/mnist, 2010.
[10] John Paisley, David Blei, and Michael Jordan. Variational bayesian inference with stochastic search. arXiv preprint arXiv:1206.6430, 2012.
[11] Danilo Jimenez Rezende, Shakir Mohamed, and Daan Wierstra. Stochastic backpropagation and approximate inference in deep generative models. arXiv preprint arXiv:1401.4082, 2014.
[12] Salah Rifai, Gr´egoire Mesnil, Pascal Vincent, Xavier Muller, Yoshua Bengio, Yann Dauphin, and Xavier Glorot. Higher order contractive auto-encoder. In Machine Learning and Knowl- edge Discovery in Databases, pages 645–660. Springer, 2011.
[13] Salah Rifai, Pascal Vincent, Xavier Muller, Xavier Glorot, and Yoshua Bengio. Contractive auto-encoders: Explicit invariance during feature extraction. In Proceedings of the 28th International Conference on Machine Learning (ICML-11), pages 833–840, 2011.
[14] Tara N Sainath, Brian Kingsbury, and Bhuvana Ramabhadran. Auto-encoder bottleneck features using deep belief networks. In Acoustics, Speech and Signal Processing (ICASSP), 2012 IEEE International Conference on, pages 4153–4156. IEEE, 2012.
[15] Takaaki Tagawa, Yukihiro Tadokoro, and Takehisa Yairi. Structured denoising autoencoder for fault detection and analysis. In Proceedings of the Sixth Asian Conference on Machine Learning, pages 96–111, 2014.
[16] Pascal Vincent, Hugo Larochelle, Isabelle Lajoie, Yoshua Bengio, and Pierre-Antoine Man- zagol. Stacked denoising autoencoders: Learning useful representations in a deep network with a local denoising criterion. The Journal of Machine Learning Research, 11:3371–3408, 2010.