详解文本分类之DeepCNN的理论与实践
导读
最近在梳理文本分类的各个神经网络算法,特地一个来总结下。下面目录中多通道卷积已经讲过了,下面是链接,没看的可以瞅瞅。我会一个一个的讲解各个算法的理论与实践。目录暂定为:
多通道卷积神经网络(multi_channel_CNN)
深度卷积神经网络(deep_CNN)
基于字符的卷积神经网络(Char_CNN)
循环与卷积神经网络并用网络(LSTM_CNN)
树状LSTM神经网络(Tree-LSTM)
Transformer(目前常用于NMT)
etc..
之后的以后再补充。今天我们该将第二个,深度卷积神经网络(DeepCNN)。
DeepCNN
DeepCNN即是深度卷积神经网络,就是有大于1层的卷积网络,也可以说是多层卷积网络(Multi_Layer_CNN,咳咳,我就是这么命名滴!)我们来直接上图,看看具体长得啥样子:
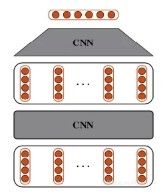
我大概描述下这个过程,比如sent_len=10,embed_dim=100,也就是输入的矩阵为(10*100),假设kernel num=n,用了上下padding,kernel size=(3*100),那么卷积之后输出的矩阵为(n*10),接着再将该矩阵放入下个卷积中,放之前我们先对这个矩阵做个转置,你肯定要问为什么?俺来告诉你我自己的认识,有两点:
硬性要求:这个矩阵第一个维度为10是句子长度产生的,所以是变量,我们习惯将该维度的大小控制为定量,比如第一个输入的值就是(sent_len,embed_dim),embed_dim就为定量,不变。所以转置即可。
理论要求:(n*10)中的n处于的维度的数据表示的是上个数据kernel对这个数据的10个数据第一次计算,第二次计算... 第10次计算,也就可以表示为通过kernel对上个数据的每个词和它的上下文进行了新的特征提取。n则表示用n个kernel对上个句子提取了n次。则最终的矩阵为(n*10),我们要转成和输入的格式一样,将第二维度依然放上一个词的表示。所以转置即可。
n 可以设置100,200等。
然后对最终的结果进行pooling,cat,然后进过线性层映射到分类上,进过softmax上进行预测输出即可。
上述仅仅说的是两层CNN的搭建,当然你可以搭建很多层啦。
实践
下面看下具体的pytotch代码如何实现
类Multi_Layer_CNN的初始化
def __init__(self, opts, vocab, label_vocab):
super(Multi_Layer_CNN, self).__init__()
random.seed(opts.seed)
torch.manual_seed(opts.seed)
torch.cuda.manual_seed(opts.seed)
self.embed_dim = opts.embed_size
self.word_num = vocab.m_size
self.pre_embed_path = opts.pre_embed_path
self.string2id = vocab.string2id
self.embed_uniform_init = opts.embed_uniform_init
self.stride = opts.stride
self.kernel_size = opts.kernel_size
self.kernel_num = opts.kernel_num
self.label_num = label_vocab.m_size
self.embed_dropout = opts.embed_dropout
self.fc_dropout = opts.fc_dropout
self.embeddings = nn.Embedding(self.word_num, self.embed_dim)
if opts.pre_embed_path != '':
embedding = Embedding.load_predtrained_emb_zero(self.pre_embed_path, self.string2id)
self.embeddings.weight.data.copy_(embedding)
else:
nn.init.uniform_(self.embeddings.weight.data, -self.embed_uniform_init, self.embed_uniform_init)
# 2 convs
self.convs1 = nn.ModuleList(
[nn.Conv2d(1, self.embed_dim, (K, self.embed_dim), stride=self.stride, padding=(K // 2, 0)) for K in self.kernel_size])
self.convs2 = nn.ModuleList(
[nn.Conv2d(1, self.kernel_num, (K, self.embed_dim), stride=self.stride, padding=(K // 2, 0)) for K in self.kernel_size])
in_fea = len(self.kernel_size)*self.kernel_num
self.linear1 = nn.Linear(in_fea, in_fea // 2)
self.linear2 = nn.Linear(in_fea // 2, self.label_num)
self.embed_dropout = nn.Dropout(self.embed_dropout)
self.fc_dropout = nn.Dropout(self.fc_dropout)def forward(self, input):
out = self.embeddings(input)
out = self.embed_dropout(out) # torch.Size([64, 39, 100])
l = []
out = out.unsqueeze(1) # torch.Size([64, 1, 39, 100])
for conv in self.convs1:
l.append(torch.transpose(F.relu(conv(out)).squeeze(3), 1, 2)) # torch.Size([64, 39, 100])
out = l
l = []
for conv, last_out in zip(self.convs2, out):
l.append(F.relu(conv(last_out.unsqueeze(1))).squeeze(3)) # torch.Size([64, 100, 39])
out = l
l = []
for i in out:
l.append(F.max_pool1d(i, kernel_size=i.size(2)).squeeze(2)) # torch.Size([64, 100])
out = torch.cat(l, 1) # torch.Size([64, 300])
out = self.fc_dropout(out)
out = self.linear1(out)
out = self.linear2(F.relu(out))
return out数据对比

可以看出多层(深层)CNN还是在有提升的。
原文发布时间为:2018-11-8
原文作者:zenRRan
本文来自云栖社区合作伙伴“深度学习自然语言处理”,了解相关信息可以关注“深度学习自然语言处理”。