2019独角兽企业重金招聘Python工程师标准>>> 
转自: https://zhuanlan.zhihu.com/p/27777266
异常检测 (anomaly detection),或者又被称为“离群点检测” (outlier detection),是机器学习研究领域中跟现实紧密联系、有广泛应用需求的一类问题。但是,什么是异常,并没有标准答案,通常因具体应用场景而异。如果要给一个比较通用的定义,很多文献通常会引用 Hawkins在文章开头那段话。很多后来者的说法,跟这个定义大同小异。这些定义虽然笼统,但其实暗含了认定“异常”的两个标准或者说假设:
- 异常数据跟样本中大多数数据不太一样。
- 异常数据在整体数据样本中占比比较小。
为了刻画异常数据的“不一样”,最直接的做法是利用各种统计的、距离的、密度的量化指标去描述数据样本跟其他样本的疏离程度。而 Isolation Forest (Liu et al. 2011) 的想法要巧妙一些,它尝试直接去刻画数据的“疏离”(isolation)程度,而不借助其他量化指标。Isolation Forest 因为简单、高效,在学术界和工业界都有着不错的名声。
算法介绍
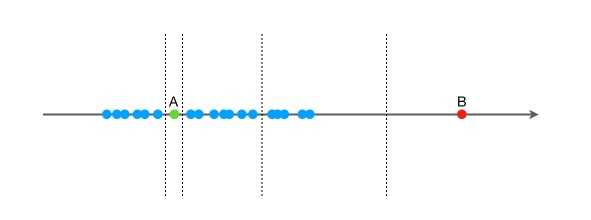
我们先用一个简单的例子来说明 Isolation Forest 的基本想法。假设现在有一组一维数据(如下图所示),我们要对这组数据进行随机切分,希望可以把点 A 和点 B 单独切分出来。具体的,我们先在最大值和最小值之间随机选择一个值 x,然后按照
我们把数据从一维扩展到两维。同样的,我们沿着两个坐标轴进行随机切分,尝试把下图中的点A'和点B'分别切分出来。我们先随机选择一个特征维度,在这个特征的最大值和最小值之间随机选择一个值,按照跟特征值的大小关系将数据进行左右切分。然后,在左右两组数据中,我们重复上述步骤,再随机的按某个特征维度的取值把数据进行细分,直到无法细分,即:只剩下一个数据点,或者剩下的数据全部相同。跟先前的例子类似,直观上,点B'跟其他数据点比较疏离,可能只需要很少的几次操作就可以将它细分出来;点A'需要的切分次数可能会更多一些。
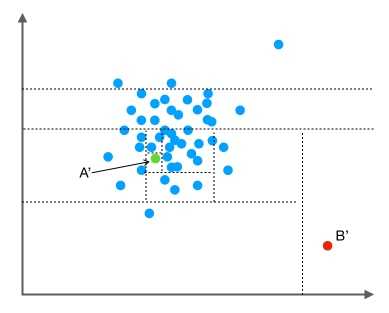
按照先前提到的关于“异常”的两个假设,一般情况下,在上面的例子中,点B和点B' 由于跟其他数据隔的比较远,会被认为是异常数据,而点A和点A' 会被认为是正常数据。直观上,异常数据由于跟其他数据点较为疏离,可能需要较少几次切分就可以将它们单独划分出来,而正常数据恰恰相反。这其实正是 Isolation Forest(IF)的核心概念。IF采用二叉树去对数据进行切分,数据点在二叉树中所处的深度反应了该条数据的“疏离”程度。整个算法大致可以分为两步:
- 训练:抽取多个样本,构建多棵二叉树(Isolation Tree,即 iTree);
- 预测:综合多棵二叉树的结果,计算每个数据点的异常分值。
训练:构建一棵 iTree 时,先从全量数据中抽取一批样本,然后随机选择一个特征作为起始节点,并在该特征的最大值和最小值之间随机选择一个值,将样本中小于该取值的数据划到左分支,大于等于该取值的划到右分支。然后,在左右两个分支数据中,重复上述步骤,直到满足如下条件:
- 数据不可再分,即:只包含一条数据,或者全部数据相同。
- 二叉树达到限定的最大深度。
预测:计算数据 x 的异常分值时,先要估算它在每棵 iTree 中的路径长度(也可以叫深度)。具体的,先沿着一棵 iTree,从根节点开始按不同特征的取值从上往下,直到到达某叶子节点。假设 iTree 的训练样本中同样落在 x 所在叶子节点的样本数为 T.size,则数据 x 在这棵 iTree 上的路径长度 h(x),可以用下面这个公式计算:
![]()
公式中,e 表示数据 x 从 iTree 的根节点到叶节点过程中经过的边的数目,C(T.size) 可以认为是一个修正值,它表示在一棵用 T.size 条样本数据构建的二叉树的平均路径长度。一般的,C(n) 的计算公式如下:
![]()
其中,H(n-1) 可用 ln(n-1)+0.5772156649 估算,这里的常数是欧拉常数。数据 x 最终的异常分值 Score(x) 综合了多棵 iTree 的结果:
![]()
公式中,E(h(x)) 表示数据 x 在多棵 iTree 的路径长度的均值, 表示单棵 iTree 的训练样本的样本数, 表示用条数据构建的二叉树的平均路径长度,它在这里主要用来做归一化。
从异常分值的公式看,如果数据 x 在多棵 iTree 中的平均路径长度越短,得分越接近 1,表明数据 x 越异常;如果数据 x 在多棵 iTree 中的平均路径长度越长,得分越接近 0,表示数据 x 越正常;如果数据 x 在多棵 iTree 中的平均路径长度接近整体均值,则打分会在 0.5 附近。
算法应用
Isolation Forest 算法主要有两个参数:一个是二叉树的个数;另一个是训练单棵 iTree 时候抽取样本的数目。实验表明,当设定为 100 棵树,抽样样本数为 256 条时候,IF 在大多数情况下就已经可以取得不错的效果。这也体现了算法的简单、高效。
Isolation Forest 是无监督的异常检测算法,在实际应用时,并不需要黑白标签。需要注意的是:(1)如果训练样本中异常样本的比例比较高,违背了先前提到的异常检测的基本假设,可能最终的效果会受影响;(2)异常检测跟具体的应用场景紧密相关,算法检测出的“异常”不一定是我们实际想要的。比如,在识别虚假交易时,异常的交易未必就是虚假的交易。所以,在特征选择时,可能需要过滤不太相关的特征,以免识别出一些不太相关的“异常”。
参考文献
1. F. T. Liu, K. M. Ting and Z. H. Zhou,Isolation-based Anomaly Detection,TKDD,2011