基于线性支持向量机的深度学习
2015-2
摘要
最近,全连接神经网络和卷积神经网络在语音识别、图像分类、自然语言处理和生物信息学等广泛地任务中实现了最先进的性能。对于分类任务,这些深度学习模型大多采用softmax激活函数进行预测,最小化交叉熵损失。在本文中,我们展示了用线性支持向量机替换softmax层的一个小而一致的优势。学习基于边际损失最小化而不是交叉熵损失最小化。虽然在现有技术中已有多种神经网络和和支持向量机的组合,但我们使用L2支持向量机的结果显示,在流行的深度学习数据集MNIST.,CIFAR-10和ICML2013面部表情识别挑战方面取得了显著的进展。
1.引言
使用神经网络的深度学习在很多任务中都有最先进的表现。
…
在分类任务中,支持向量机是一个广泛替代softmax的替代品。
特别是,深度卷积网络首先使用监督\非监督目标进行训练,以学习良好的不变隐式表示。将数据样本中相应的隐藏变量作为输入,喂入到线性支持向量机中或内核中。
…
**在这篇文章中,我们展示了对于一些深度架构,线性支持向量机顶层替代softmax是有益的。**我们对支持向量机的原始问题进行了优化,可以对梯度进行反向传播来学习较低层次的特征。
本文用L2-SVM代替合页损失函数。与标准支持向量机的合页损失不同,L2支持向量机的合页损失是可微分的,并且严重惩罚错误。原始L2支持向量机目标是在SVMs发明的前3年提出的。
与使用softmax作为顶层的网络相比,我们在MNIST. CIFAR-10以及最近 kaggle的一项面部表情识别比赛上展示了优越的性能。对小批量随机梯度下降法进行了优化。通过比较3.4节中的两个模型,我们认为性能的提高主要是由于SVM损失函数具有较好的正则化效果,而不是参数优化的优势。
2.模型
2.1 softmax
2.2 Support Vector Machines
2.3 Multiclass SVMs
2.4 Deep Learning with SVMs
在本文中,我们利用L2支持向量机的目标训练深度神经网络进行分类。较低的层权值是通过从顶层SVM反向传播梯度来学习的。为了做到这一点,我们需要区分SVM目标与激活的倒数第二层。从这一点来看,反向传播算法与顶层使用softmax标准深度学习网络是完全相同的。我们发现L2-SVM在大多数情况下比L1-SVM稍好,我们将在实验部分使用L2-SVM。
3.实验
3.1 面部表情识别
比赛本身是在Kaggle上举办的,在最初的发展阶段有超过120支参赛队伍。
这些数据包括28,709张48×48的7种不同类型的表情。示例及其对应的表情标签如图1所示。验证集和测试集由3589幅图像组成,这是一个分类任务。

我们提交了获胜的解决方案,公共验证分数为69.4%,相应的私人测试分数为71.2%。我们的私人测试分数比第二名高出了2%。由于标签噪声和其他因素例如数据崩溃的影响,据估计,人的平均表现在65%-68%。
3.1.1 softmax VS DLSVM
我们比较了softmax与使用DLSVM进行深度学习的性能。这两个模型都使用了8分割/折叠交叉验证进行测试,其中包含一个镜像层、相似转换层、两个卷积滤波器和一个池化层。然后是一个包含3072个节点全连接层。隐藏层都是矫正过的线性类型。其他超参数如权重衰减,是通过交叉验证得到的。
我们还可以将Softmax与L2-SVMs的验证曲线看作权重更新的函数,如图2.
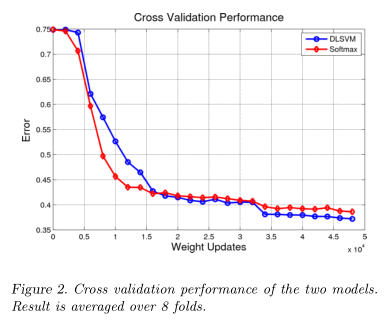
由于在训练的后半部分学习率降低,DLSVM保持了一个小而清晰地性能增益。
我们还绘制了两种模型的第一层卷积滤波器:
虽然通过观察这些过滤器并不能获得多少好处,但SVM训练的卷积层似乎有更多的纹理过滤器。
3.2 MNIST
……
我们使用一个简单的全连接模型,首先执行PCA从784维降到70维。每层512个单元的两个隐藏层后面是softmax或L2svm。然后将数据分成300个小批次,每个批次200个样品。我们使用带有动量的随机梯度下降法对着300个小批次进行了总共400代训练,共有120000参数更新。学习速率从0.1线性衰减到0.0,Softmax层上的L2权重代价设置成0.001。为了防止过拟合和临界状态的产生,在输入端加入了大量的高斯噪声。加入标准差为1.0(线性衰减为0)的噪声。我们的学习算法是置换不变的,不带任何无监督的预训练,得到这些结果:softmax 0.99% DLSVM:0.87%
对于上面的学习设置,MNIST上0.87%的错误可能(在此时)是最先进的。softmax和DLSVM之间的唯一区别是最后一层。这个实验主要是证明最后一个线性svm相对于softmax的有效性,我们还没有穷尽地探索其他常用的技巧,例如Dropout,权值不变、隐藏单元稀疏、增加更多的隐藏层、增加图层大小等。


3.3 CIFAR-10
加拿大高等研究院10数据集是一个10类对象数据集,包含5万张用于训练的图像和1万张用于测试的图像。彩色图像是32×32分辨率。我们训练了一个卷积神经网络,它是两个池化层和滤波器交替的神经网络。
两种模型的卷积网络部分都是相当标准的,第一个卷积层有3255个滤波器,带有Relu隐藏单元,第二个卷积层有6455个过滤器。两个模型都使用最大池化,并向下采样了2倍。
倒数第二层有3072个隐藏节点,使用Relu激活,退出率为0.2。采用L2-SVM的卷积层与使用Softmax的卷积层的区别主要体现在支持向量机的C常数、Softmax的权值衰减常数和学习速率上。我们通过验证分别为每个模型选择这些超参数的值。

在论文方面,最先进的(在写作时)结果是9.5%左右,然而,该模型的不同之处在于它包含了对比度归一化层以及使用贝叶斯优化来优化其超参数。
3.4 正则化或优化
为了弄清楚DLSVM的增益是由于目标函数的显著性还是由于能够更好地进行优化,我们观察了两个最终模型在其自身目标函数和其他目标下的损失。结果如表3:
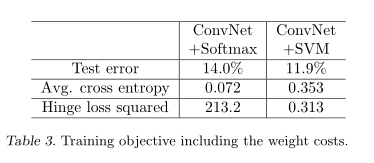
值得注意的是,交叉熵越低,中间一行的误差就越大。此外,我们还初始化了一个ConvNet+Softmax模型,其中DLSVM的权值误差为11.9%。随着进一步的训练,网络的错误率逐渐增加到14%。这说明DLSVM的增益很大程度上是因为一个更好的目标函数。
4. 结论
综上所述,我们已经证明了DLSVM在两个标准数据集和一个最近的数据集上比softmax更有效。从softmax切换到SVMs非常简单,似乎对分类任务非常有用。还需要进一步的研究来探索其他的多类支持向量机的公式,进一步理解增益获得的位置和倍数。