TensorFlow——训练自己的数据——CIFAR10(一)数据准备
参考教程:Tensorflow教程:深度学习 图像分类 CIFAR10数据集
Reading Data
所用函数
def read_cifar10(data_dir, is_train, batch_size, shuffle):`
Args:
data_dir: the directory of CIFAR10
is_train: boolen
batch_size:
shuffle: #是否打乱顺序
Returns:
label: 1D tensor, tf.int32
image: 4D tensor, [batch_size, height, width, 3], tf.float32变量声明
img_width = 32
img_height = 32
img_depth = 3
label_bytes = 1
image_bytes = img_width*img_height*img_depth #32x32x3=3072读取数据
#将以下操作放在一个作用域内,使得tensorboard更美观
with tf.name_scope('input'):
#如果是训练数据,则将文件的路径赋值给filenames,注意到data的命名规律为data_batch_n.bin
#os.path.join(“home”, "me", "mywork"),在linux返回“home/me/mywork",在windows上返回"home\me\mywork"
#好处是可以根据系统自动选择正确的路径分隔符"/"或"\"
if is_train:
filenames = [os.path.join(data_dir, '/data_batch_%d.bin' %ii)
for ii in np.arange(1, 5)]
else:
filenames = [os.path.join(data_dir, '/test_batch.bin')]
#产生一个队列,因为使用的是二进制,所以使用string_input_producer
#ps:之前猫狗大战是label+img,用的是slice_input_producer
filename_queue = tf.train.string_input_producer(filenames)
#读取数据,label_bytes=1,image_bytes=32*32*3=3072
reader = tf.FixedLengthRecordReader(label_bytes + image_bytes)
key, value = reader.read(filename_queue)
#对读取到的数据解码decode
#ps:猫狗大战的数据是img,用的解码器是tf.image.decode_jpeg
record_bytes = tf.decode_raw(value, tf.uint8)
#data包含了label和image,所以通过slice切片,把他们分开,这里切了个[0,1]
label = tf.slice(record_bytes, [0], [label_bytes])
label = tf.cast(label, tf.int32)
#切[1,3072]
image_raw = tf.slice(record_bytes, [label_bytes], [image_bytes])
#将二进制数据reshape为图像数据[0-depth,1-height,2-width]=[3,32,32]
image_raw = tf.reshape(image_raw, [img_depth, img_height, img_width])
#转换为[1-height,2-width,0-depth]
image = tf.transpose(image_raw, (1,2,0)) # convert from D/H/W to H/W/D
image = tf.cast(image, tf.float32)
# # data argumentation,图像增强(裁剪、旋转、缩放等),但据说效果不怎么样
# image = tf.random_crop(image, [24, 24, 3])# randomly crop the image size to 24 x 24
# image = tf.image.random_flip_left_right(image)
# image = tf.image.random_brightness(image, max_delta=63)
# image = tf.image.random_contrast(image,lower=0.2,upper=1.8)
#归一化操作从[0,255]到[-1,1]
image = tf.image.per_image_standardization(image) #substract off the mean and divide by the variance
#是否打乱顺序
if shuffle:
images, label_batch = tf.train.shuffle_batch(
[image, label],
batch_size = batch_size,
num_threads= 16,
capacity = 2000, #队列的容量
min_after_dequeue = 1500)#队列取出后的最小值
else:
images, label_batch = tf.train.batch(
[image, label],
batch_size = batch_size,
num_threads = 16,
capacity= 2000)
# return images, tf.reshape(label_batch, [batch_size])
## ONE-HOT ,将label转换成[1,0,0,0,0,0,0,0,0,0]的形式(第一个类为正确)
n_classes = 10
label_batch = tf.one_hot(label_batch, depth= n_classes)
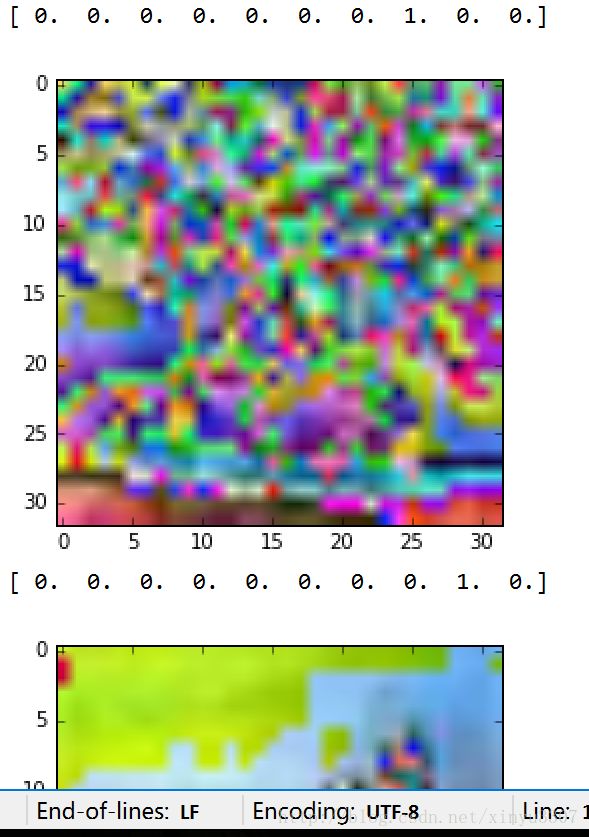
return images, tf.reshape(label_batch, [batch_size, n_classes])测试数据
把一个Batch显示出来
import matplotlib.pyplot as plt
#这里用自己的data路径
data_dir = 'D:/Study/Python/Projects/CIFAR10/data'
BATCH_SIZE = 2 #一个batch两张图
image_batch, label_batch = read_cifar10(data_dir,
is_train=True,
batch_size=BATCH_SIZE,
shuffle=True)
with tf.Session() as sess:
i = 0
#用coord和threads监控队列
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(coord=coord)
try:
while not coord.should_stop() and i<1:
img, label = sess.run([image_batch, label_batch])
# just test one batch
for j in np.arange(BATCH_SIZE):
print('label: %d' %label[j])
plt.imshow(img[j,:,:,:])
plt.show()
i+=1
except tf.errors.OutOfRangeError:
print('done!')
finally:
coord.request_stop()
coord.join(threads)结果
归一化和float类型导致图片显示失真