第四周(图论--DFS相关)
第四周(图论–DFS相关)
目录:
- 本周完成题目
- 主要过程思路
- 相关代码
- 感想与总结
一、本周完成题目
本周共完成2道题目,2道Medium。针对于本周所学的知识选择了Graph分类下的题目。 Graph
具体完成题目及难度如下表:
| # | Title | Difficulty |
|---|---|---|
| 133 | Clone Graph | Medium |
| 210 | Course Schedule II | Medium |
题目内容
1、Clone Graph
Clone an undirected graph. Each node in the graph contains a label and a list of its neighbors.
题目大意:给定一个无向图,复制该图。
2、Course Schedule II
There are a total of n courses you have to take, labeled from 0 to n - 1.
Some courses may have prerequisites, for example to take course 0 you have to first take course 1, which is expressed as a pair: [0,1]
Given the total number of courses and a list of prerequisite pairs, return the ordering of courses you should take to finish all courses.There may be multiple correct orders, you just need to return one of them. If it is impossible to finish all courses, return an empty array.
For example:
2, [[1,0]]
There are a total of 2 courses to take. To take course 1 you should have finished course 0. So the correct course order is [0,1]
4, [[1,0],[2,0],[3,1],[3,2]]
There are a total of 4 courses to take. To take course 3 you should have finished both courses 1 and 2. Both courses 1 and 2 should be taken after you finished course 0. So one correct course order is [0,1,2,3]. Another correct ordering is[0,2,1,3].
题目大意:有n门可选课程,从0到n-1编号。其中课程之间存在先后顺序关系,如果课程先后顺序可以满足则输出一种可能的课程排序结果。
二、主要过程思路
这两道题都是图论相关的题目,可以使用BFS(广度优先搜索)或者DFS(深度优先搜索)算法进行处理。这里我主要使用到了DFS方法。
DFS:
其英文全称为Depth First Search,图的深度遍历原则:访问一个邻接的未访问的节点,标记它,并把它放入栈中。当不能再访问时,如果栈不为空,则从栈中弹出一个元素。直到所有元素都被访问到,遍历结束。
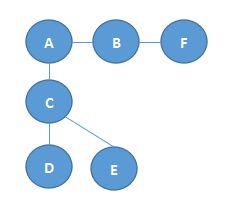
以下图为例,如从A开始,首先访问B、F,之后访问C、D。最后访问E。
Clone Graph
本题使用的是DFS算法。主要思路是利用一个表示遍历与否的map,排除空节点和已经遍历过的节点,对于每个未遍历过的相邻节点进行遍历,最后返回全部遍历完的节点。
Course Schedule II
本题的问题可以进行转化,实质上是求有向图是否有环存在,若存在则返回空集,不存在则返回课程排序结果。在读入数字之后建立一个邻接表,之后对于从0开始的每个元素进行逐次判断,看以该数字起始的子元素中是否存在环。
本题在这一部分使用的是DFS,对于每个数字进行遍历。
首先对于数字状态进行设定。
(1)visit[i]=0,说明i未被遍历过;
(2)visit[i]=-1,说明i正在遍历中,即i为当前元素的前置元素;
(3)visit[i]=1,说明i已经遍历完成且没有出现环。
遍历具体规则如下:
1.当前数字没有子元素,visit[i]标记为1,插入该元素,return true。
2.当前数字有子元素,对于每个子元素,判断该元素的visit值是否为-1,若为-1,说明产生了环,return false。
若为0,说明子元素未被访问过,标记为-1,对该元素继续进行DFS。若为1,跳过该元素。
3.遍历完所有子元素则标记该元素为1并将该元素插入数组,代表已经完成子元素的遍历且不存在环。
这道题与上周的那道题十分类似,但是由于开始想的有一些偏差,导致出现了各种问题。最后发现只需要在遍历完一个元素的时候将该元素加入数组中即可得到所需的效果。
三、相关代码
Clone Graph
/**
* Definition for undirected graph.
* struct UndirectedGraphNode {
* int label;
* vector neighbors;
* UndirectedGraphNode(int x) : label(x) {};
* };
*/
class Solution {
public:
map Course Schedule II
class Solution {
public:
vector<int> findOrder(int numCourses, vectorint , int> >& prerequisites) {
vector<vector<int> > graph(numCourses); //保存邻接表
vector<int> result;
for (int i = 0; i < prerequisites.size(); ++i) {
int s1 = prerequisites[i].first, s2 = prerequisites[i].second;
graph[s1].push_back(s2);
}
int visit[numCourses] = { 0 };
for (int i = 0; i < numCourses; i++) {
if (visit[i]!=1) {
if (!DFS(graph, i, visit, result)) {
return {};
}
}
}
return result;
}
//DFS部分,递归遍历
bool DFS(vector<vector<int> > &graph, int current, int *visit, vector<int> &result) {
if (graph[current].size() == 0) {
visit[current] = 1;
result.push_back(current);//当前数字没有子元素,标记为1,压入数组
return true;
}
visit[current] = -1;
for (int i = 0; i < graph[current].size(); i++) {
int index = graph[current][i];
if (visit[index] == -1) {
return false;
} else if (visit[index] == 0) {
visit[index] = -1;
if (!DFS(graph, graph[current][i], visit, result)) {
return false;
}
} else {
continue;
}
}
result.push_back(current); //遍历完成,压入数组
visit[current] = 1;
return true;
}
};四、感想与总结
本周主要进行了图论中DFS的练习,通过具体的题目对于这种遍历算法都进行了复习。在弄懂了题目之后相对而言还是比较简单的。这两道题都可以用BFS的方法进行替换,算法稍有不同但是本质都是图的遍历问题。