大数据运维3--zookeeper和kafaka的简单使用
Zookeeper概述
是一个开源的分布式应用程序协调服务,它是用来保证数据在集群间的事物一致性的
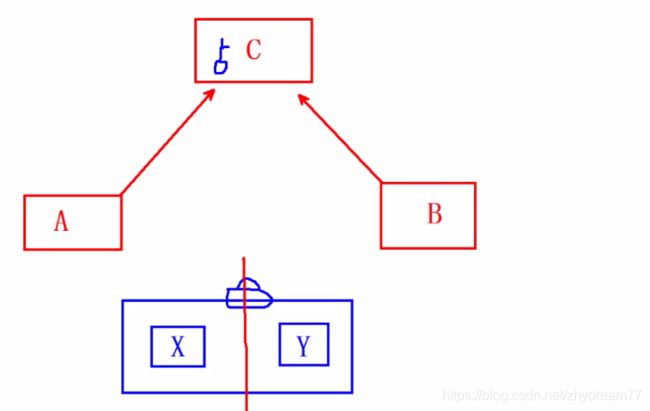
举例,比如A公司和B公司达成某个协议,A公司需要到B公司取对应的文件过程,这个过程叫通信的过程.计算机中的程序比较多,会出现资源争抢,这个时候会发生死锁,这时整个资源会出现运转不了.这个时候,如果有个交警,指挥资源的流动,这个时候就不会出现死锁.如下图,如果在单机上,资源XY可以打包一起,当需要访问的时候,需要到C中拿到对应的令牌,所有的需要访问X,Y的资源需要在访问令牌才可以访问到XY资源.如果在集群中,XY没有办法打包,这个时候,就需要zookeeper在其中协调资源.
Zookeeper应用场景:集群分布式锁,集群统一命名服务,分布式协调服务
Zookeeper角色与特性
Leader:接受所有Follower的提案请求并统一协调发起提案的投票,负责与所有的Follower进行内部数据交换
Follower:直接为客户端服务并参与提案的投票,同时与Leader进行数据交换
Observer:直接为客户端服务但不参与提案的投票,同时也与Leader进行数据交换
这里的投票机制的Follower相当于议员,Observer相当于平民,这样区分是为了不能投票涉及太多的人员导致性能下降
Zookeeper角色与选举
服务在启动的时候是没有角色的(LOOKING),角色是通过选举产生的,选举产生一个Leader,剩下的是Follower
选举Leader原则
集群中超过半数集群投票选择Leader,假如集群中拥有n台服务器,那么Leader必须得到n/2+1台服务器的投票
如果Leader死亡,重新选举Leader,如果死亡的机器数量达到一半,则集群挂掉,如果无法得到足够的投票数量,就重新发起投票,如果参与投票的机器不足n/2+1,则集群停止工作.如果Follower死亡过多,剩余机器不足n/2+1,则集群也会停止工作.Observer不计算在投票总设备数量里面.
Zookeeper原理与设计
Leader所有写相关操作,Follower读操作与响应Leader提议,在Observer出现以前,Zookeeper的伸缩性由Follower来实现,我们可以通过添加;Follower节点的数量来保证Zookeeper服务的读性能,但是随着Follower节点数量的增加,Zookeeper服务的写性能受到了影响.客户段提供一个请求,若是读请求,则由每台Server的本地副本数据库直接响应,若是写请求,需要通过一致性协议Zab来处理,
Zab协议规定:来自Client的所有写请求都要转发到ZK服务中唯一的Leader,由Leader根据该请求发起一个Proposal.然后其他的Server对该Proposa进行vote.之后Leader对Vote进行收集,当Vote数量过半时Leader会向所有的Server发送一个通知消息,最后当Client所连接的Server收到该消息时,会把该操作更新到内存中并对Client的写请求做出回应.
Zookeeper在上述协议中实际扮演了两个职能.一方面从客户端接受连接与操作请求,另一方面对操作结果进行投票.这两个职能在Zookeeper集群扩展的时候彼此制约,从Zab协议对写请求的处理过程中可以发现,增加Follower的数量,则增加了协议投票过程的压力.因为Leader节点必须等待集群中过半Server响应投票.是节点的增加使得部分计算机运行较慢,从而拖慢整个整个投票过程的可能性也随之提高.随着集群变大,写操作也会随之下降.所有.不得不在增加Client数量的期望和希望我们保持较好吞吐量的期间进行权衡.要打破这一耦合关系.引入了不参与投票的服务器Objserver.Observer可以接受客户端的连接,并将写请求转发给Leader节点.但是Leader节点不会要求Observer参与投票,Observe的扩展,给Zookeeper的可伸缩性带来了全新的景象,加入很多Observer节点.无须担心严重影响写吞吐量,但并非是无懈可击,因为协议中的通知阶段,仍然与服务器的数量呈线性关系.但是这里的串行开销非常低,因此,可以认为在通知服务器阶段的开销不会成为瓶颈.Observer提升读性能的可伸缩性,Observer提供了广域网能力.

zookeeper的安装
[root@nn01 ~]# tar zxf zookeeper-3.4.13.tar.gz #解压zookeeper的包
[root@nn01 ~]# ls
Desktop hadoop-2.7.7.tar.gz zookeeper-3.4.13 zookeeper-3.4.13.tar.gz
[root@nn01 ~]# mv zookeeper-3.4.13 /usr/local/zookeeper #将zookeeper的包移交到/usr/local/zookeeper
[root@nn01 ~]# cd /usr/local/zookeeper/conf/
[root@nn01 conf]# cp zoo_sample.cfg zoo.cfg
[root@nn01 conf]# vim zoo.cfg #添加对应的角色节点
12 dataDir=/tmp/zookeeper #可以更改数据目录存储数据,之后需要创建出来
29 server.1=node1:2888:3888
30 server.2=node2:2888:3888
31 server.3=node3:2888:3888
32 server.4=nn01:2888:3888:observer #fallower不需要指定,但是Observer需要指定
[root@nn01 conf]# mkdir /tmp/zookeeper #创建文件
[root@nn01 conf]# echo 4 > /tmp/zookeeper/myid #指定id,这个是对应zoo.cfg的id
[root@nn01 conf]# cat /tmp/zookeeper/myid
4
[root@nn01 conf]# /usr/local/zookeeper/bin/zkServer.sh
ZooKeeper JMX enabled by default
Using config: /usr/local/zookeeper/bin/../conf/zoo.cfg
Usage: /usr/local/zookeeper/bin/zkServer.sh {start|start-foreground|stop|restart|status|upgrade|print-cmd}
[root@nn01 conf]# /usr/local/zookeeper/bin/zkServer.sh start #开启zookeeper
ZooKeeper JMX enabled by default
Using config: /usr/local/zookeeper/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
[root@nn01 conf]# /usr/local/zookeeper/bin/zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /usr/local/zookeeper/bin/../conf/zoo.cfg
Error contacting service. It is probably not running.
[root@nn01 conf]# jps #QuorumPeerMain出现就是zookeeper开启的标示
20596 NameNode
24581 QuorumPeerMain
24629 Jps
20790 SecondaryNameNode
其他的节点也需要配置
[root@nn01 conf]# for i in node{1..3}; do scp -r /usr/local/zookeeper/ $i:/usr/local/zookeeper/; done
[root@node1 ~]# mkdir /tmp/zookeeper
[root@node1 ~]# echo 1 > /tmp/zookeeper/myid
[root@node1 ~]# /usr/local/zookeeper/bin/zkServer.sh start
ZooKeeper JMX enabled by default
Using config: /usr/local/zookeeper/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
[root@node1 ~]# jps
5856 DataNode
6934 QuorumPeerMain
6952 Jps
[root@node2 ~]# mkdir /tmp/zookeeper
[root@node2 ~]# echo 2 > /tmp/zookeeper/myid
[root@node2 ~]# /usr/local/zookeeper/bin/zkServer.sh start
-bash: /usr/local/zookeeper/bin/zkServer.sh: 没有那个文件或目录
[root@node2 ~]# /usr/local/zookeeper/bin/zkServer.sh start
ZooKeeper JMX enabled by default
Using config: /usr/local/zookeeper/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
[root@node2 ~]# jps
7249 QuorumPeerMain
7276 Jps
6142 DataNode
[root@node3 ~]# mkdir /tmp/zookeeper
[root@node3 ~]# echo 3 > /tmp/zookeeper/myid
[root@node3 ~]# /usr/local/zookeeper/bin/zkServer.sh start
ZooKeeper JMX enabled by default
Using config: /usr/local/zookeeper/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
[root@node3 ~]# jps
6693 Jps
5563 DataNode
6668 QuorumPeerMain
验证集群中的状态
[root@nn01 conf]# /usr/local/zookeeper/bin/zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /usr/local/zookeeper/bin/../conf/zoo.cfg
Mode: observer
[root@node3 ~]# /usr/local/zookeeper/bin/zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /usr/local/zookeeper/bin/../conf/zoo.cfg
Mode: follower
[root@node2 ~]# /usr/local/zookeeper/bin/zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /usr/local/zookeeper/bin/../conf/zoo.cfg
Mode: leader
[root@node1 ~]# /usr/local/zookeeper/bin/zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /usr/local/zookeeper/bin/../conf/zoo.cfg
Mode: follower
使用zookeeper的命令
--可以查看整个集群中的状态信息和使用zabbix实现监控都可以,这些命令可以去官网查看
[root@nn01 ~]# socat TCP:node2:2181 - #查看node2节点的conf
conf
clientPort=2181
dataDir=/tmp/zookeeper/version-2
dataLogDir=/tmp/zookeeper/version-2
tickTime=2000
maxClientCnxns=60
minSessionTimeout=4000
maxSessionTimeout=40000
serverId=2
initLimit=10
syncLimit=5
electionAlg=3
electionPort=3888
quorumPort=2888
peerType=0
[root@nn01 ~]# socat TCP:node2:2181 - #多少客户端连接
mntr
zk_version 3.4.13-2d71af4dbe22557fda74f9a9b4309b15a7487f03, built on 06/29/2018 04:05 GMT
zk_avg_latency 0
zk_max_latency 0
zk_min_latency 0
zk_packets_received 4
zk_packets_sent 3
zk_num_alive_connections 1
zk_outstanding_requests 0
zk_server_state leader
zk_znode_count 4
zk_watch_count 0
zk_ephemerals_count 0
zk_approximate_data_size 27
zk_open_file_descriptor_count 36
zk_max_file_descriptor_count 4096
zk_fsync_threshold_exceed_count 0
zk_followers 3
zk_synced_followers 2
zk_pending_syncs 0
zk_last_proposal_size -1
zk_max_proposal_size -1
zk_min_proposal_size -1
[root@node1 conf]# cat api.sh
#!/bin/bash
function getstatus(){
exec 9<>/dev/tcp/$1/2181 2>/dev/null
echo stat >&9
MODE=$(cat <&9 |grep -Po "(?<=Mode:).*")
exec 9<&-
echo ${MODE:-NULL}
}
for i in node{1..3} nn01;do
echo -ne "${i}\t"
getstatus ${i}
done
[root@node1 conf]# chmod 755 api.sh
[root@node1 conf]# ./api.sh
node1 follower
node2 leader
node3 follower
nn01 observer
kafaka消息队列
kafka是由LinkeIn开发的一个分布式的消息系统,Kafaka是使用Scala编写,Kafaka是消息中间件
kafaka的用途:解耦,冗余,提高扩展性,缓冲,保证顺序,灵活,削峰填谷,异步通信
生产环境用途:客户端访问web服务器的时候,将大量的比如订单数据,存入kafka中,这个时候的订单数据就相当于生产者一样,其他的数据库中间件从kafka中读取,相当于消费者一样,数据的中间件将数据读取处理之后,在分发给数据库进行数据交换,在一定的程度上减轻了数据库的读写压力.

kafaka角色与集群结构
producer:生产者,负责发布消息
consumer:消费者,负责读取处理消息
topic:消息的类别
Parition:每个Topic包含一个或多个Partition
Broker:kafka集群包含一个或多个服务器
kafka通过Zookeeper管理集群配置,选举Leader

kafka集群安装与配置
kafka集群的安装配置依赖Zookeeper,搭建kafka集群之前,请先创建好一个课用的Zookeeper集群,
安装OPenJDK运行环境,
同步kafka拷贝到所有集群主机
修改配置文件
启动与验证
[root@node1 ~]# tar -xaf kafka_2.12-2.1.0.tgz
[root@node1 ~]# mv kafka_2.12-2.1.0 /usr/local/kafka
[root@node1 ~]# cd /usr/local/kafka/config/ #转到对应的目录中
[root@node1 config]# vim server.properties #更改kafka的配置文件
21 broker.id=21 #id需要配置不一样的
123 zookeeper.connect=node1:2181,node2:2181,node3:2181
[root@node1 config]# for i in node{1..3}; do scp -r /usr/local/kafka $i:/usr/local/; done #将kafka拷贝到其他的节点,更改配置
[root@node2 ~]# vim /usr/local/kafka/config/server.properties
21 broker.id=22
[root@node3 ~]# vim /usr/local/kafka/config/server.properties
21 broker.id=23
启动kafka需要在三台上同时配置
[root@node1 ~]# /usr/local/kafka/bin/kafka-server-start.sh -daemon /usr/local/kafka/config/server.properties #开启kafka
[root@node1 ~]# jps #Kafka出现标示的kafka开启
5856 DataNode
7460 Kafka
7493 Jps
6934 QuorumPeerMain
[root@node2 ~]# /usr/local/kafka/bin/kafka-server-start.sh -daemon /usr/local/kafka/config/server.properties
[root@node2 ~]# jps
7249 QuorumPeerMain
7802 Jps
7740 Kafka
6142 DataNode
[root@node3 ~]# /usr/local/kafka/bin/kafka-server-start.sh -daemon /usr/local/kafka/config/server.properties
[root@node3 ~]# jps
7249 Jps
7187 Kafka
5563 DataNode
6668 QuorumPeerMain
测试
[root@node1 ~]# /usr/local/kafka/bin/kafka-topics.sh --create --partitions 2 --replication-factor 2 --zookeeper localhost:2181 --topic zhy #创建topic
Created topic "zhy".
[root@node1 ~]# /usr/local/kafka/bin/kafka-console-producer.sh --broker-list localhost:9092 --topic zhy #创建kafka的生产者
[root@node3 ~]# /usr/local/kafka/bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic zhy #查看kafka同步
zhuhaiyandexiaoxi
zheg1