Hive用户行为数仓(一)
Hive用户行为离线仓库
1、基本说明




埋点数据基本格式
公共字段:基本所有安卓手机都包含的字段
业务字段:埋点上报的字段,有具体的业务类型
下面就是一个示例,表示业务字段的上传。
示例日志(服务器时间戳 | 日志):
1540934156385|{
"ap": "gmall",
"cm": {
"uid": "1234",
"vc": "2",
"vn": "1.0",
"la": "EN",
"sr": "",
"os": "7.1.1",
"ar": "CN",
"md": "BBB100-1",
"ba": "blackberry",
"sv": "V2.2.1",
"g": "[email protected]",
"hw": "1620x1080",
"t": "1506047606608",
"nw": "WIFI",
"ln": 0
},
"et": [
{
"ett": "1506047605364", //客户端事件产生时间
"en": "display", //事件名称
"kv": { //事件结果,以key-value形式自行定义
"goodsid": "236",
"action": "1",
"extend1": "1",
"place": "2",
"category": "75"
}
},{
"ett": "1552352626835",
"en": "active_background",
"kv": {
"active_source": "1"
}
}
]
}
}
2、日志采集Flume
2.2 Flume经验
1)Source
(1)Taildir Source相比Exec Source、Spooling Directory Source的优势
- TailDir Source:断点续传、多目录。Flume1.6以前需要自己自定义Source记录每次读取文件位置,实现断点续传。
- Exec Source:可以实时搜集数据,但是在Flume不运行或者Shell命令出错的情况下,数据将会丢失。
- Spooling Directory Source监控目录,不支持断点续传。
(2)batchSize大小如何设置?
答:Event 1K左右时,500-1000合适(默认为100)
2)Channel
保证数据的安全可靠,使用类型file,把数据缓存在磁盘中。
2.3 Flume的ETL和分类型拦截器
本项目中自定义了两个拦截器,分别是:ETL拦截器、日志类型区分拦截器。
ETL拦截器主要用于,过滤时间戳不合法和Json数据不完整的日志
日志类型区分拦截器主要用于,将启动日志和事件日志区分开来
1)创建Maven工程flume-interceptor
2)创建包名:com.bigdata.flume.interceptor
3)在pom.xml文件中添加如下配置
<dependencies>
<dependency>
<groupId>org.apache.flume</groupId>
<artifactId>flume-ng-core</artifactId>
<version>1.7.0</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
<version>2.3.2</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
4)在com.bigdata.flume.interceptor包下创建LogETLInterceptor类名
Flume ETL拦截器LogETLInterceptor
import org.apache.flume.Context;
import org.apache.flume.Event;
import org.apache.flume.interceptor.Interceptor;
import java.nio.charset.Charset;
import java.util.ArrayList;
import java.util.List;
public class LogETLInterceptor implements Interceptor {
@Override
public void initialize() {
}
@Override
public Event intercept(Event event) {
// 1 获取数据
byte[] body = event.getBody();
String log = new String(body, Charset.forName("UTF-8"));
// 2 判断数据类型并向Header中赋值
if (log.contains("start")) {
if (LogUtils.validateStart(log)){
return event;
}
}else {
if (LogUtils.validateEvent(log)){
return event;
}
}
// 3 返回校验结果
return null;
}
@Override
public List<Event> intercept(List<Event> events) {
ArrayList<Event> interceptors = new ArrayList<>();
for (Event event : events) {
Event intercept1 = intercept(event);
if (intercept1 != null){
interceptors.add(intercept1);
}
}
return interceptors;
}
@Override
public void close() {
}
public static class Builder implements Interceptor.Builder{
@Override
public Interceptor build() {
return new LogETLInterceptor();
}
@Override
public void configure(Context context) {
}
}
}
4)Flume日志过滤工具类
import org.apache.commons.lang.math.NumberUtils;
public class LogUtils {
public static boolean validateEvent(String log) {
// 服务器时间 | json
// 1549696569054 | {"cm":{"ln":"-89.2","sv":"V2.0.4","os":"8.2.0","g":"[email protected]","nw":"4G","l":"en","vc":"18","hw":"1080*1920","ar":"MX","uid":"u8678","t":"1549679122062","la":"-27.4","md":"sumsung-12","vn":"1.1.3","ba":"Sumsung","sr":"Y"},"ap":"weather","et":[]}
// 1 切割
String[] logContents = log.split("\\|");
// 2 校验
if(logContents.length != 2){
return false;
}
//3 校验服务器时间
if (logContents[0].length()!=13 || !NumberUtils.isDigits(logContents[0])){
return false;
}
// 4 校验json
if (!logContents[1].trim().startsWith("{") || !logContents[1].trim().endsWith("}")){
return false;
}
return true;
}
public static boolean validateStart(String log) {
// {"action":"1","ar":"MX","ba":"HTC","detail":"542","en":"start","entry":"2","extend1":"","g":"[email protected]","hw":"640*960","l":"en","la":"-43.4","ln":"-98.3","loading_time":"10","md":"HTC-5","mid":"993","nw":"WIFI","open_ad_type":"1","os":"8.2.1","sr":"D","sv":"V2.9.0","t":"1559551922019","uid":"993","vc":"0","vn":"1.1.5"}
if (log == null){
return false;
}
// 校验json
if (!log.trim().startsWith("{") || !log.trim().endsWith("}")){
return false;
}
return true;
}
}
5)Flume日志类型区分拦截器LogTypeInterceptor
import org.apache.flume.Context;
import org.apache.flume.Event;
import org.apache.flume.interceptor.Interceptor;
import java.nio.charset.Charset;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
public class LogTypeInterceptor implements Interceptor {
@Override
public void initialize() {
}
@Override
public Event intercept(Event event) {
// 区分日志类型: body header
// 1 获取body数据
byte[] body = event.getBody();
String log = new String(body, Charset.forName("UTF-8"));
// 2 获取header
Map<String, String> headers = event.getHeaders();
// 3 判断数据类型并向Header中赋值
if (log.contains("start")) {
headers.put("topic","topic_start");
}else {
headers.put("topic","topic_event");
}
return event;
}
@Override
public List<Event> intercept(List<Event> events) {
ArrayList<Event> interceptors = new ArrayList<>();
for (Event event : events) {
Event intercept1 = intercept(event);
interceptors.add(intercept1);
}
return interceptors;
}
@Override
public void close() {
}
public static class Builder implements Interceptor.Builder{
@Override
public Interceptor build() {
return new LogTypeInterceptor();
}
@Override
public void configure(Context context) {
}
}
}
6)打包
拦截器打包之后,只需要单独包,不需要将依赖的包上传。打包之后要放入Flume的lib文件夹下面。

注意:为什么不需要依赖包?因为依赖包在flume的lib目录下面已经存在了。
7)需要先将打好的包放入到node01、node02、node03的/kkb/install/flume-1.6.0-cdh5.14.2/lib文件夹下面。
[hadoop@node01 lib]$ ls flume-interceptor-1.0-SNAPSHOT.jar
flume-interceptor-1.0-SNAPSHOT.jar
[hadoop@node02 lib]$ ls flume-interceptor-1.0-SNAPSHOT.jar
flume-interceptor-1.0-SNAPSHOT.jar
[hadoop@node03 lib]$ ls flume-interceptor-1.0-SNAPSHOT.jar
flume-interceptor-1.0-SNAPSHOT.jar
2.4 日志采集Flume配置
1)Flume配置分析
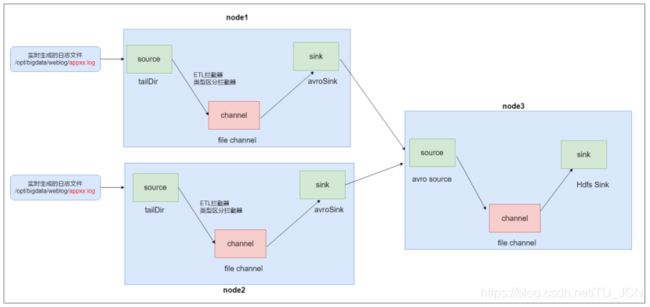
Flume直接读log日志的数据,log日志的格式是app-yyyy-mm-dd.log。
2)Flume的具体配置如下:
(1)在node01和node02主机上/kkb/install/flume-1.6.0-cdh5.14.2/myconf目录下创建flume-client.conf文件
#flume-client.conf
a1.sources = r1
a1.sinks = k1
a1.channels = c1
#配置source
a1.sources.r1.type = taildir
a1.sources.r1.positionFile = /kkb/bigdata/index/log_position.json
a1.sources.r1.filegroups = f1
a1.sources.r1.filegroups.f1 = /kkb/bigdata/weblog/app.+
a1.sources.r1.fileHeader = true
a1.sources.r1.channels = c1
#interceptor
a1.sources.r1.interceptors = i1 i2
a1.sources.r1.interceptors.i1.type = com.bigdata.flume.interceptor.LogETLInterceptor$Builder
a1.sources.r1.interceptors.i2.type = com.bigdata.flume.interceptor.LogTypeInterceptor$Builder
#配置channel
a1.channels.c1.type = file
#检查点文件目录
a1.channels.c1.checkpointDir=/kkb/bigdata/flume_checkpoint
#缓存数据文件夹
a1.channels.c1.dataDirs=/kkb/bigdata/flume_data
#配置sink
a1.sinks.k1.channel = c1
a1.sinks.k1.type = avro
#node3
a1.sinks.k1.hostname = 192.168.52.120
a1.sinks.k1.port = 4141
在文件配置如下内容
注意:
com.bigdata.flume.interceptor.LogETLInterceptor
和 com.bigdata.flume.interceptor.LogTypeInterceptor是自定义的拦截器的全类名。
需要根据用户自定义的拦截器做相应修改。
(2)在node03主机上/kkb/install/flume-1.6.0-cdh5.14.2/myconf目录下创建flume-hdfs.conf文件
#Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
#配置source
a1.sources.r1.type = avro
a1.sources.r1.bind = 192.168.52.120
a1.sources.r1.port = 4141
a1.sources.r1.channels = c1
#配置channel
a1.channels.c1.type = file
#检查点文件目录
a1.channels.c1.checkpointDir=/kkb/bigdata/flume_checkpoint
#缓存数据文件夹
a1.channels.c1.dataDirs=/kkb/bigdata/flume_data
#配置sink
a1.sinks.k1.channel = c1
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = hdfs://node01:8020/origin_data/gmall/log/%{topic}/%Y-%m-%d
a1.sinks.k1.hdfs.filePrefix = logevent-
a1.sinks.k1.hdfs.round = true
a1.sinks.k1.hdfs.roundValue = 10
a1.sinks.k1.hdfs.roundUnit = second
#不要产生大量小文件
a1.sinks.k1.hdfs.rollInterval = 10
a1.sinks.k1.hdfs.rollSize = 134217728
a1.sinks.k1.hdfs.rollCount = 1000
a1.sinks.k1.hdfs.useLocalTimeStamp = true
a1.sinks.k1.hdfs.minBlockReplicas=1
a1.sinks.k1.hdfs.fileType = CompressedStream
a1.sinks.k1.hdfs.codeC = lzop
这里需要配置hadoop支持lzo压缩
修改hadoop集群中的每台服务器配置文件core-site.xml文件,然后启动hadoop集群
io.compression.codecs
org.apache.hadoop.io.compress.GzipCodec,
org.apache.hadoop.io.compress.DefaultCodec,
org.apache.hadoop.io.compress.BZip2Codec,
com.hadoop.compression.lzo.LzoCodec,
com.hadoop.compression.lzo.LzopCodec
io.compression.codec.lzo.class
com.hadoop.compression.lzo.LzoCodec `在这里插入代码片`
2.5 日志采集Flume启动停止脚本
1)在/home/hadoop/bin目录下创建脚本flume.sh
[hadoop@node01 bin]$ vim flume.sh
在脚本中填写如下内容
#!/bin/bash
case $1 in
"start" ){
for i in node03 node02 node01
do
echo "-----------启动 $i 采集flume-------------"
if [ "node03" = $i ];then
ssh $i "source /etc/profile; nohup /kkb/install/apache-flume-1.6.0-cdh5.14.2-bin/bin/flume-ng agent -n a1 -c /kkb/install/apache-flume-1.6.0-cdh5.14.2-bin/myconf -f /kkb/install/apache-flume-1.6.0-cdh5.14.2-bin/myconf/flume-hdfs.conf -Dflume.root.logger=info,console > /dev/null 2>&1 & "
else
ssh $i "source /etc/profile; nohup /kkb/install/apache-flume-1.6.0-cdh5.14.2-bin/bin/flume-ng agent -n a1 -c /kkb/install/apache-flume-1.6.0-cdh5.14.2-bin/conf -f /kkb/install/apache-flume-1.6.0-cdh5.14.2-bin/myconf/flume-client.conf -Dflume.root.logger=info,console > /dev/null 2>&1 & "
fi
done
};;
"stop"){
for i in node03 node02 node01
do
echo "-----------停止 $i 采集flume-------------"
ssh $i "source /etc/profile; ps -ef | grep flume | grep -v grep |awk '{print \$2}' | xargs kill"
done
};;
esac
说明
1、nohup:该命令可以在你退出帐户/关闭终端之后继续运行相应的进程。nohup就是不挂起的意思,不挂断地运行命令。
2、/dev/null:代表linux的空设备文件,所有往这个文件里面写入的内容都会丢失,俗称“黑洞”。
标准输入0:从键盘获得输入 /proc/self/fd/0
标准输出1:输出到屏幕(即控制台) /proc/self/fd/1
错误输出2:输出到屏幕(即控制台) /proc/self/fd/2
2)增加脚本执行权限
[hadoop@node01 bin]$ chmod 777 flume.sh
3)flume集群启动脚本
[hadoop@node01 bin]$ ./flume.sh start
4)flume集群停止脚本
[hadoop@node01 bin]$ ./flume.sh stop
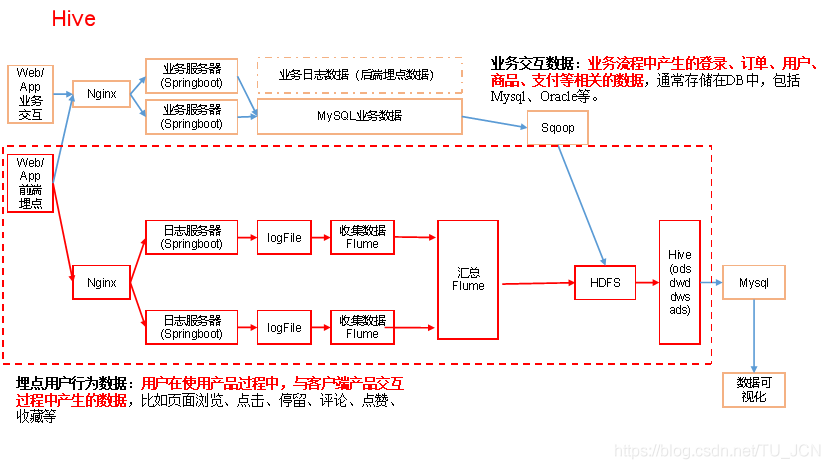
3、数仓搭建
数仓分层概念
- ods原始数据层:完整的保存hdfs的数据,启动日志表 、事件日志表
- dw数据仓库层:通过解析ods层的数据,将启动日志解析成为一张表
将用户的事件日志,解析成为11张表 - dws层:主要就是针对12张表进行各种维度的统计分析
- app数据展示层:数据报表的展示
分层好处:复杂的事情给他简单化,每一层相互进行隔绝
离线的数仓做的是T+1的任务,在实际工作当中,每天都会分析前一天的数据,表示数据的分析结果需要延迟一天



创建数据库
1)创建gmall数据库
hive (default)> create database gmall;
说明:如果数据库存在且有数据,需要强制删除时执行:drop database gmall cascade;
2)使用gmall数据库
hive (default)> use gmall;
3.1 ODS层
原始数据层,存放原始数据,直接加载原始日志、数据,数据保持原貌不做处理。
3.1.1 启动日志表ods_start_log

1)创建输入数据是lzo,输出是text,支持json解析的分区表
hive (gmall)>
drop table if exists gmall.ods_start_log;
CREATE EXTERNAL TABLE gmall.ods_start_log (`line` string)
PARTITIONED BY (`dt` string)
STORED AS
INPUTFORMAT 'com.hadoop.mapred.DeprecatedLzoTextInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION '/warehouse/gmall/ods/ods_start_log';
说明Hive的LZO压缩:
https://cwiki.apache.org/confluence/display/Hive/LanguageManual+LZO
2)加载数据
hive (gmall)>
load data inpath '/origin_data/gmall/log/topic_start/2019-02-10'
into table gmall.ods_start_log
partition(dt='2019-02-10');
注意:时间格式都配置成YYYY-MM-DD格式,这是Hive默认支持的时间格式
3)查看是否加载成功
hive (gmall)> select * from gmall.ods_start_log limit 2;
3.1.2 事件日志表ods_event_log
1)创建输入数据是lzo输出是text,支持json解析的分区表
hive (gmall)>
drop table if exists gmall.ods_event_log;
CREATE EXTERNAL TABLE gmall.ods_event_log
(`line` string)
PARTITIONED BY (`dt` string)
STORED AS
INPUTFORMAT 'com.hadoop.mapred.DeprecatedLzoTextInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION '/warehouse/gmall/ods/ods_event_log';
2)加载数据
hive (gmall)>
load data inpath '/origin_data/gmall/log/topic_event/2019-02-10'
into table gmall.ods_event_log
partition(dt='2019-02-10');
注意:时间格式都配置成YYYY-MM-DD格式,这是Hive默认支持的时间格式
3)查看是否加载成功
hive (gmall)> select * from gmall.ods_event_log limit 2;
3.1.3 ODS层加载数据脚本
1)在node03 的/home/hadoop/bin目录下创建脚本
[hadoop@node03 bin]$ vim ods_log.sh
在脚本中编写如下内容
#!/bin/bash
# 定义变量方便修改
APP=gmall
hive=/kkb/install/hive-1.1.0-cdh5.14.2/bin/hive
# 如果是输入的日期按照取输入日期;如果没输入日期取当前时间的前一天
if [ -n "$1" ] ;then
do_date=$1
else
do_date=`date -d "-1 day" +%F`
fi
echo "===日志日期为 $do_date==="
sql="
load data inpath '/origin_data/gmall/log/topic_start/$do_date'
into table "$APP".ods_start_log partition(dt='$do_date');
load data inpath '/origin_data/gmall/log/topic_event/$do_date'
into table "$APP".ods_event_log partition(dt='$do_date');
"
$hive -e "$sql"
说明1:
[ -n 变量值 ] 判断变量的值,是否为空
-- 变量的值,非空,返回true
-- 变量的值,为空,返回false
说明2:
查看date命令的使用,
[hadoop@node03 ~]$ date --help
2)增加脚本执行权限
[hadoop@node03 bin]$ chmod 777 ods_log.sh
3)脚本使用
[hadoop@node03 bin]$ ./ods_log.sh 2019-02-11
4)查看导入数据
hive (gmall)>
select * from gmall.ods_start_log where dt='2019-02-11' limit 2;
select * from gmall.ods_event_log where dt='2019-02-11' limit 2;
5)脚本执行时间
企业开发中一般在每日凌晨30分~1点
3.2、DWD层
对ODS层数据进行清洗(去除空值,脏数据,超过极限范围的数据,行式存储改为列存储,改压缩格式)。
3.2.1、启动表 dwd_start_log
1)创建启动表
hive (gmall)>
drop table if exists gmall.dwd_start_log;
CREATE EXTERNAL TABLE gmall.dwd_start_log(
`mid_id` string,
`user_id` string,
`version_code` string,
`version_name` string,
`lang` string,
`source` string,
`os` string,
`area` string,
`model` string,
`brand` string,
`sdk_version` string,
`gmail` string,
`height_width` string,
`app_time` string,
`network` string,
`lng` string,
`lat` string,
`entry` string,
`open_ad_type` string,
`action` string,
`loading_time` string,
`detail` string,
`extend1` string
)
PARTITIONED BY (dt string)
location '/warehouse/gmall/dwd/dwd_start_log/';
2) 向启动表导入数据
开启hive本地模式以加快hive查询速度
set hive.exec.mode.local.auto=true;
hive (gmall)>
insert overwrite table gmall.dwd_start_log
PARTITION (dt='2019-02-10')
select
get_json_object(line,'$.mid') mid_id,
get_json_object(line,'$.uid') user_id,
get_json_object(line,'$.vc') version_code,
get_json_object(line,'$.vn') version_name,
get_json_object(line,'$.l') lang,
get_json_object(line,'$.sr') source,
get_json_object(line,'$.os') os,
get_json_object(line,'$.ar') area,
get_json_object(line,'$.md') model,
get_json_object(line,'$.ba') brand,
get_json_object(line,'$.sv') sdk_version,
get_json_object(line,'$.g') gmail,
get_json_object(line,'$.hw') height_width,
get_json_object(line,'$.t') app_time,
get_json_object(line,'$.nw') network,
get_json_object(line,'$.ln') lng,
get_json_object(line,'$.la') lat,
get_json_object(line,'$.entry') entry,
get_json_object(line,'$.open_ad_type') open_ad_type,
get_json_object(line,'$.action') action,
get_json_object(line,'$.loading_time') loading_time,
get_json_object(line,'$.detail') detail,
get_json_object(line,'$.extend1') extend1
from gmall.ods_start_log
where dt='2019-02-10';
3)测试
hive (gmall)> select * from gmall.dwd_start_log limit 2;
DWD层启动表加载数据脚本
1)在node03的/home/hadoop/bin目录下创建脚本
[hadoop@node03 bin]$ vim dwd_start_log.sh
在脚本中编写如下内容
#!/bin/bash
# 定义变量方便修改
APP=gmall
hive=/kkb/install/hive-1.1.0-cdh5.14.2/bin/hive
# 如果是输入的日期按照取输入日期;如果没输入日期取当前时间的前一天
if [ -n "$1" ] ;then
do_date=$1
else
do_date=`date -d "-1 day" +%F`
fi
sql="
insert overwrite table "$APP".dwd_start_log
PARTITION (dt='$do_date')
select
get_json_object(line,'$.mid') mid_id,
get_json_object(line,'$.uid') user_id,
get_json_object(line,'$.vc') version_code,
get_json_object(line,'$.vn') version_name,
get_json_object(line,'$.l') lang,
get_json_object(line,'$.sr') source,
get_json_object(line,'$.os') os,
get_json_object(line,'$.ar') area,
get_json_object(line,'$.md') model,
get_json_object(line,'$.ba') brand,
get_json_object(line,'$.sv') sdk_version,
get_json_object(line,'$.g') gmail,
get_json_object(line,'$.hw') height_width,
get_json_object(line,'$.t') app_time,
get_json_object(line,'$.nw') network,
get_json_object(line,'$.ln') lng,
get_json_object(line,'$.la') lat,
get_json_object(line,'$.entry') entry,
get_json_object(line,'$.open_ad_type') open_ad_type,
get_json_object(line,'$.action') action,
get_json_object(line,'$.loading_time') loading_time,
get_json_object(line,'$.detail') detail,
get_json_object(line,'$.extend1') extend1
from "$APP".ods_start_log
where dt='$do_date';
"
$hive -e "$sql"
2)增加脚本执行权限
[hadoop@node03 bin]$ chmod 777 dwd_start_log.sh
3)脚本使用
[hadoop@node03 bin]$ ./dwd_start_log.sh 2019-02-11
4)查询导入结果
hive (gmall)>
select * from gmall.dwd_start_log where dt='2019-02-11' limit 2;
5)脚本执行时间
企业开发中一般在每日凌晨30分~1点
3.2.2、基础明细表 dwd_base_event_log
明细表用于存储ODS层原始表转换过来的明细数据。

1)创建事件日志基础明细表
hive (gmall)>
drop table if exists gmall.dwd_base_event_log;
CREATE EXTERNAL TABLE gmall.dwd_base_event_log(
`mid_id` string,
`user_id` string,
`version_code` string,
`version_name` string,
`lang` string,
`source` string,
`os` string,
`area` string,
`model` string,
`brand` string,
`sdk_version` string,
`gmail` string,
`height_width` string,
`app_time` string,
`network` string,
`lng` string,
`lat` string,
`event_name` string,
`event_json` string,
`server_time` string)
PARTITIONED BY (`dt` string)
stored as parquet
location '/warehouse/gmall/dwd/dwd_base_event_log/';
2)说明:
其中event_name和event_json用来对应事件名和整个事件。
这个地方将原始日志1对多的形式拆分出来了。
操作的时候我们需要将原始日志展平,需要用到UDF和UDTF。
1️⃣ 自定义UDF函数(解析公共字段)

1)创建一个maven工程:hivefunction
2)创建包名:com.bigdata.udf
3)在pom.xml文件中添加如下内容
<properties>
<project.build.sourceEncoding>UTF8</project.build.sourceEncoding>
<hive.version>1.2.1</hive.version>
</properties>
<dependencies>
<!--添加hive依赖-->
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>${hive.version}</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
<version>2.3.2</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
UDF代码:用于解析公共字段
import org.apache.commons.lang.StringUtils;
import org.apache.hadoop.hive.ql.exec.UDF;
import org.json.JSONException;
import org.json.JSONObject;
public class BaseFieldUDF extends UDF {
public String evaluate(String line, String jsonkeysString) {
// 0 准备一个sb
StringBuilder sb = new StringBuilder();
// 1 切割jsonkeys mid uid vc vn l sr os ar md
String[] jsonkeys = jsonkeysString.split(",");
// 2 处理line 服务器时间 | json
String[] logContents = line.split("\\|");
// 3 合法性校验
if (logContents.length != 2 || StringUtils.isBlank(logContents[1])) {
return "";
}
// 4 开始处理json
try {
JSONObject jsonObject = new JSONObject(logContents[1]);
// 获取cm里面的对象
JSONObject base = jsonObject.getJSONObject("cm");
// 循环遍历取值
for (int i = 0; i < jsonkeys.length; i++) {
String filedName = jsonkeys[i].trim();
if (base.has(filedName)) {
sb.append(base.getString(filedName)).append("\t");
} else {
sb.append("\t");
}
}
sb.append(jsonObject.getString("et")).append("\t");
sb.append(logContents[0]).append("\t");
} catch (JSONException e) {
e.printStackTrace();
}
return sb.toString();
}
public static void main(String[] args) {
String line = "1541217850324|{\"cm\":{\"mid\":\"m7856\",\"uid\":\"u8739\",\"ln\":\"-74.8\",\"sv\":\"V2.2.2\",\"os\":\"8.1.3\",\"g\":\"[email protected]\",\"nw\":\"3G\",\"l\":\"es\",\"vc\":\"6\",\"hw\":\"640*960\",\"ar\":\"MX\",\"t\":\"1541204134250\",\"la\":\"-31.7\",\"md\":\"huawei-17\",\"vn\":\"1.1.2\",\"sr\":\"O\",\"ba\":\"Huawei\"},\"ap\":\"weather\",\"et\":[{\"ett\":\"1541146624055\",\"en\":\"display\",\"kv\":{\"goodsid\":\"n4195\",\"copyright\":\"ESPN\",\"content_provider\":\"CNN\",\"extend2\":\"5\",\"action\":\"2\",\"extend1\":\"2\",\"place\":\"3\",\"showtype\":\"2\",\"category\":\"72\",\"newstype\":\"5\"}},{\"ett\":\"1541213331817\",\"en\":\"loading\",\"kv\":{\"extend2\":\"\",\"loading_time\":\"15\",\"action\":\"3\",\"extend1\":\"\",\"type1\":\"\",\"type\":\"3\",\"loading_way\":\"1\"}},{\"ett\":\"1541126195645\",\"en\":\"ad\",\"kv\":{\"entry\":\"3\",\"show_style\":\"0\",\"action\":\"2\",\"detail\":\"325\",\"source\":\"4\",\"behavior\":\"2\",\"content\":\"1\",\"newstype\":\"5\"}},{\"ett\":\"1541202678812\",\"en\":\"notification\",\"kv\":{\"ap_time\":\"1541184614380\",\"action\":\"3\",\"type\":\"4\",\"content\":\"\"}},{\"ett\":\"1541194686688\",\"en\":\"active_background\",\"kv\":{\"active_source\":\"3\"}}]}";
String x = new BaseFieldUDF().evaluate(line, "mid,uid,vc,vn,l,sr,os,ar,md,ba,sv,g,hw,nw,ln,la,t");
System.out.println(x);
}
}
注意:使用main函数主要用于模拟数据测试。
2️⃣自定义UDTF函数(解析具体事件字段)

1)创建包名:com.bigdata.udtf
2)在com.bigdata.udtf包下创建类名:EventJsonUDTF
3)用于展开业务字段
import org.apache.commons.lang.StringUtils;
import org.apache.hadoop.hive.ql.exec.UDFArgumentException;
import org.apache.hadoop.hive.ql.metadata.HiveException;
import org.apache.hadoop.hive.ql.udf.generic.GenericUDTF;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspectorFactory;
import org.apache.hadoop.hive.serde2.objectinspector.StructObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorFactory;
import org.json.JSONArray;
import org.json.JSONException;
import java.util.ArrayList;
public class EventJsonUDTF extends GenericUDTF {
//该方法中,我们将指定输出参数的名称和参数类型:
@Override
public StructObjectInspector initialize(ObjectInspector[] argOIs) throws UDFArgumentException {
ArrayList<String> fieldNames = new ArrayList<String>();
ArrayList<ObjectInspector> fieldOIs = new ArrayList<ObjectInspector>();
fieldNames.add("event_name");
fieldOIs.add(PrimitiveObjectInspectorFactory.javaStringObjectInspector);
fieldNames.add("event_json");
fieldOIs.add(PrimitiveObjectInspectorFactory.javaStringObjectInspector);
return ObjectInspectorFactory.getStandardStructObjectInspector(fieldNames, fieldOIs);
}
//输入1条记录,输出若干条结果
@Override
public void process(Object[] objects) throws HiveException {
// 获取传入的et
String input = objects[0].toString();
// 如果传进来的数据为空,直接返回过滤掉该数据
if (StringUtils.isBlank(input)) {
return;
} else {
try {
// 获取一共有几个事件(ad/facoriters)
JSONArray ja = new JSONArray(input);
if (ja == null)
return;
// 循环遍历每一个事件
for (int i = 0; i < ja.length(); i++) {
String[] result = new String[2];
try {
// 取出每个的事件名称(ad/facoriters)
result[0] = ja.getJSONObject(i).getString("en");
// 取出每一个事件整体
result[1] = ja.getString(i);
} catch (JSONException e) {
continue;
}
// 将结果返回
forward(result);
}
} catch (JSONException e) {
e.printStackTrace();
}
}
}
//当没有记录处理的时候该方法会被调用,用来清理代码或者产生额外的输出
@Override
public void close() throws HiveException {
}
}
2)打包
![]()
3)将hive-function-1.0-SNAPSHOT.jar上传到node03的/kkb/install/hive-1.1.0-cdh5.14.2/lib
4)将jar包添加到Hive的classpath
hive (gmall)>
add jar /kkb/install/hive-1.1.0-cdh5.14.2/lib/hive-function-1.0-SNAPSHOT.jar;
5)创建临时函数与开发好的java class关联
hive (gmall)>
create temporary function base_analizer as 'com.bigdata.udf.BaseFieldUDF';
create temporary function flat_analizer as 'com.bigdata.udtf.EventJsonUDTF';
解析事件日志基础明细表,加载数据
hive (gmall)>
insert overwrite table gmall.dwd_base_event_log
PARTITION (dt='2019-02-10')
select
mid_id,
user_id,
version_code,
version_name,
lang,
source,
os,
area,
model,
brand,
sdk_version,
gmail,
height_width,
app_time,
network,
lng,
lat,
event_name,
event_json,
server_time
from
(
select
split(base_analizer(line,'mid,uid,vc,vn,l,sr,os,ar,md,ba,sv,g,hw,t,nw,ln,la'),'\t')[0] as mid_id,
split(base_analizer(line,'mid,uid,vc,vn,l,sr,os,ar,md,ba,sv,g,hw,t,nw,ln,la'),'\t')[1] as user_id,
split(base_analizer(line,'mid,uid,vc,vn,l,sr,os,ar,md,ba,sv,g,hw,t,nw,ln,la'),'\t')[2] as version_code,
split(base_analizer(line,'mid,uid,vc,vn,l,sr,os,ar,md,ba,sv,g,hw,t,nw,ln,la'),'\t')[3] as version_name,
split(base_analizer(line,'mid,uid,vc,vn,l,sr,os,ar,md,ba,sv,g,hw,t,nw,ln,la'),'\t')[4] as lang,
split(base_analizer(line,'mid,uid,vc,vn,l,sr,os,ar,md,ba,sv,g,hw,t,nw,ln,la'),'\t')[5] as source,
split(base_analizer(line,'mid,uid,vc,vn,l,sr,os,ar,md,ba,sv,g,hw,t,nw,ln,la'),'\t')[6] as os,
split(base_analizer(line,'mid,uid,vc,vn,l,sr,os,ar,md,ba,sv,g,hw,t,nw,ln,la'),'\t')[7] as area,
split(base_analizer(line,'mid,uid,vc,vn,l,sr,os,ar,md,ba,sv,g,hw,t,nw,ln,la'),'\t')[8] as model,
split(base_analizer(line,'mid,uid,vc,vn,l,sr,os,ar,md,ba,sv,g,hw,t,nw,ln,la'),'\t')[9] as brand,
split(base_analizer(line,'mid,uid,vc,vn,l,sr,os,ar,md,ba,sv,g,hw,t,nw,ln,la'),'\t')[10] as sdk_version,
split(base_analizer(line,'mid,uid,vc,vn,l,sr,os,ar,md,ba,sv,g,hw,t,nw,ln,la'),'\t')[11] as gmail,
split(base_analizer(line,'mid,uid,vc,vn,l,sr,os,ar,md,ba,sv,g,hw,t,nw,ln,la'),'\t')[12] as height_width,
split(base_analizer(line,'mid,uid,vc,vn,l,sr,os,ar,md,ba,sv,g,hw,t,nw,ln,la'),'\t')[13] as app_time,
split(base_analizer(line,'mid,uid,vc,vn,l,sr,os,ar,md,ba,sv,g,hw,t,nw,ln,la'),'\t')[14] as network,
split(base_analizer(line,'mid,uid,vc,vn,l,sr,os,ar,md,ba,sv,g,hw,t,nw,ln,la'),'\t')[15] as lng,
split(base_analizer(line,'mid,uid,vc,vn,l,sr,os,ar,md,ba,sv,g,hw,t,nw,ln,la'),'\t')[16] as lat,
split(base_analizer(line,'mid,uid,vc,vn,l,sr,os,ar,md,ba,sv,g,hw,t,nw,ln,la'),'\t')[17] as ops,
split(base_analizer(line,'mid,uid,vc,vn,l,sr,os,ar,md,ba,sv,g,hw,t,nw,ln,la'),'\t')[18] as server_time
from gmall.ods_event_log where dt='2019-02-10' and base_analizer(line,'mid,uid,vc,vn,l,sr,os,ar,md,ba,sv,g,hw,t,nw,ln,la')<>''
) sdk_log lateral view flat_analizer(ops) tmp_k as event_name, event_json;
2)测试
hive (gmall)> select * from gmall.dwd_base_event_log limit 2;
3.2.3、基础事件表(11张)

<1> 商品点击表 dwd_display_log
1)建表语句
hive (gmall)>
drop table if exists gmall.dwd_display_log;
CREATE EXTERNAL TABLE gmall.dwd_display_log(
`mid_id` string,
`user_id` string,
`version_code` string,
`version_name` string,
`lang` string,
`source` string,
`os` string,
`area` string,
`model` string,
`brand` string,
`sdk_version` string,
`gmail` string,
`height_width` string,
`app_time` string,
`network` string,
`lng` string,
`lat` string,
`action` string,
`goodsid` string,
`place` string,
`extend1` string,
`category` string,
`server_time` string
)
PARTITIONED BY (dt string)
location '/warehouse/gmall/dwd/dwd_display_log/';
2)导入数据
hive (gmall)>
insert overwrite table gmall.dwd_display_log
PARTITION (dt='2019-02-10')
select
mid_id,
user_id,
version_code,
version_name,
lang,
source,
os,
area,
model,
brand,
sdk_version,
gmail,
height_width,
app_time,
network,
lng,
lat,
get_json_object(event_json,'$.kv.action') action,
get_json_object(event_json,'$.kv.goodsid') goodsid,
get_json_object(event_json,'$.kv.place') place,
get_json_object(event_json,'$.kv.extend1') extend1,
get_json_object(event_json,'$.kv.category') category,
server_time
from gmall.dwd_base_event_log
where dt='2019-02-10' and event_name='display';
<2> 商品详情页表 dwd_newsdetail_log
1)建表语句
drop table if exists gmall.dwd_newsdetail_log;
CREATE EXTERNAL TABLE gmall.dwd_newsdetail_log(
`mid_id` string,
`user_id` string,
`version_code` string,
`version_name` string,
`lang` string,
`source` string,
`os` string,
`area` string,
`model` string,
`brand` string,
`sdk_version` string,
`gmail` string,
`height_width` string,
`app_time` string,
`network` string,
`lng` string,
`lat` string,
`entry` string,
`action` string,
`goodsid` string,
`showtype` string,
`news_staytime` string,
`loading_time` string,
`type1` string,
`category` string,
`server_time` string)
PARTITIONED BY (dt string)
location '/warehouse/gmall/dwd/dwd_newsdetail_log/';
2)导入数据
insert overwrite table gmall.dwd_newsdetail_log
PARTITION (dt='2019-02-10')
select
mid_id,
user_id,
version_code,
version_name,
lang,
source,
os,
area,
model,
brand,
sdk_version,
gmail,
height_width,
app_time,
network,
lng,
lat,
get_json_object(event_json,'$.kv.entry') entry,
get_json_object(event_json,'$.kv.action') action,
get_json_object(event_json,'$.kv.goodsid') goodsid,
get_json_object(event_json,'$.kv.showtype') showtype,
get_json_object(event_json,'$.kv.news_staytime') news_staytime,
get_json_object(event_json,'$.kv.loading_time') loading_time,
get_json_object(event_json,'$.kv.type1') type1,
get_json_object(event_json,'$.kv.category') category,
server_time
from gmall.dwd_base_event_log
where dt='2019-02-10' and event_name='newsdetail';
<3> 广告表 dwd_ad_log
1)建表语句
drop table if exists gmall.dwd_ad_log;
CREATE EXTERNAL TABLE gmall.dwd_ad_log(
`mid_id` string,
`user_id` string,
`version_code` string,
`version_name` string,
`lang` string,
`source` string,
`os` string,
`area` string,
`model` string,
`brand` string,
`sdk_version` string,
`gmail` string,
`height_width` string,
`app_time` string,
`network` string,
`lng` string,
`lat` string,
`entry` string,
`action` string,
`content` string,
`detail` string,
`ad_source` string,
`behavior` string,
`newstype` string,
`show_style` string,
`server_time` string)
PARTITIONED BY (dt string)
location '/warehouse/gmall/dwd/dwd_ad_log/';
2)导入数据
insert overwrite table gmall.dwd_ad_log
PARTITION (dt='2019-02-10')
select
mid_id,
user_id,
version_code,
version_name,
lang,
source,
os,
area,
model,
brand,
sdk_version,
gmail,
height_width,
app_time,
network,
lng,
lat,
get_json_object(event_json,'$.kv.entry') entry,
get_json_object(event_json,'$.kv.action') action,
get_json_object(event_json,'$.kv.content') content,
get_json_object(event_json,'$.kv.detail') detail,
get_json_object(event_json,'$.kv.source') ad_source,
get_json_object(event_json,'$.kv.behavior') behavior,
get_json_object(event_json,'$.kv.newstype') newstype,
get_json_object(event_json,'$.kv.show_style') show_style,
server_time
from gmall.dwd_base_event_log
where dt='2019-02-10' and event_name='ad';
<4> 消息通知表 dwd_notification_log
1)建表语句
hive (gmall)>
drop table if exists gmall.dwd_notification_log;
CREATE EXTERNAL TABLE gmall.dwd_notification_log(
`mid_id` string,
`user_id` string,
`version_code` string,
`version_name` string,
`lang` string,
`source` string,
`os` string,
`area` string,
`model` string,
`brand` string,
`sdk_version` string,
`gmail` string,
`height_width` string,
`app_time` string,
`network` string,
`lng` string,
`lat` string,
`action` string,
`noti_type` string,
`ap_time` string,
`content` string,
`server_time` string
)
PARTITIONED BY (dt string)
location '/warehouse/gmall/dwd/dwd_notification_log/';
2)导入数据
hive (gmall)>
insert overwrite table gmall.dwd_notification_log
PARTITION (dt='2019-02-10')
select
mid_id,
user_id,
version_code,
version_name,
lang,
source,
os,
area,
model,
brand,
sdk_version,
gmail,
height_width,
app_time,
network,
lng,
lat,
get_json_object(event_json,'$.kv.action') action,
get_json_object(event_json,'$.kv.noti_type') noti_type,
get_json_object(event_json,'$.kv.ap_time') ap_time,
get_json_object(event_json,'$.kv.content') content,
server_time
from gmall.dwd_base_event_log
where dt='2019-02-10' and event_name='notification';
<5> 商品列表页表 dwd_loading_log
1)建表语句
hive (gmall)>
drop table if exists gmall.dwd_loading_log;
CREATE EXTERNAL TABLE gmall.dwd_loading_log(
`mid_id` string,
`user_id` string,
`version_code` string,
`version_name` string,
`lang` string,
`source` string,
`os` string,
`area` string,
`model` string,
`brand` string,
`sdk_version` string,
`gmail` string,
`height_width` string,
`app_time` string,
`network` string,
`lng` string,
`lat` string,
`action` string,
`loading_time` string,
`loading_way` string,
`extend1` string,
`extend2` string,
`type` string,
`type1` string,
`server_time` string)
PARTITIONED BY (dt string)
location '/warehouse/gmall/dwd/dwd_loading_log/';
2)导入数据
hive (gmall)>
insert overwrite table gmall.dwd_loading_log
PARTITION (dt='2019-02-10')
select
mid_id,
user_id,
version_code,
version_name,
lang,
source,
os,
area,
model,
brand,
sdk_version,
gmail,
height_width,
app_time,
network,
lng,
lat,
get_json_object(event_json,'$.kv.action') action,
get_json_object(event_json,'$.kv.loading_time') loading_time,
get_json_object(event_json,'$.kv.loading_way') loading_way,
get_json_object(event_json,'$.kv.extend1') extend1,
get_json_object(event_json,'$.kv.extend2') extend2,
get_json_object(event_json,'$.kv.type') type,
get_json_object(event_json,'$.kv.type1') type1,
server_time
from gmall.dwd_base_event_log
where dt='2019-02-10' and event_name='loading';
<6> 用户后台活跃表 dwd_active_background_log
1)建表语句
hive (gmall)>
drop table if exists gmall.dwd_active_background_log;
CREATE EXTERNAL TABLE gmall.dwd_active_background_log(
`mid_id` string,
`user_id` string,
`version_code` string,
`version_name` string,
`lang` string,
`source` string,
`os` string,
`area` string,
`model` string,
`brand` string,
`sdk_version` string,
`gmail` string,
`height_width` string,
`app_time` string,
`network` string,
`lng` string,
`lat` string,
`active_source` string,
`server_time` string
)
PARTITIONED BY (dt string)
location '/warehouse/gmall/dwd/dwd_background_log/';
2)导入数据
hive (gmall)>
insert overwrite table gmall.dwd_active_background_log
PARTITION (dt='2019-02-10')
select
mid_id,
user_id,
version_code,
version_name,
lang,
source,
os,
area,
model,
brand,
sdk_version,
gmail,
height_width,
app_time,
network,
lng,
lat,
get_json_object(event_json,'$.kv.active_source') active_source,
server_time
from gmall.dwd_base_event_log
where dt='2019-02-10' and event_name='active_background';
<7> 用户前台活跃表 dwd_active_foreground_log
1)建表语句
hive (gmall)>
drop table if exists gmall.dwd_active_foreground_log;
CREATE EXTERNAL TABLE gmall.dwd_active_foreground_log(
`mid_id` string,
`user_id` string,
`version_code` string,
`version_name` string,
`lang` string,
`source` string,
`os` string,
`area` string,
`model` string,
`brand` string,
`sdk_version` string,
`gmail` string,
`height_width` string,
`app_time` string,
`network` string,
`lng` string,
`lat` string,
`push_id` string,
`access` string,
`server_time` string)
PARTITIONED BY (dt string)
location '/warehouse/gmall/dwd/dwd_foreground_log/';
2)导入数据
hive (gmall)>
insert overwrite table gmall.dwd_active_foreground_log
PARTITION (dt='2019-02-10')
select
mid_id,
user_id,
version_code,
version_name,
lang,
source,
os,
area,
model,
brand,
sdk_version,
gmail,
height_width,
app_time,
network,
lng,
lat,
get_json_object(event_json,'$.kv.push_id') push_id,
get_json_object(event_json,'$.kv.access') access,
server_time
from gmall.dwd_base_event_log
where dt='2019-02-10' and event_name='active_foreground';
<8> 评论表 dwd_comment_log
1)建表语句
hive (gmall)>
drop table if exists gmall.dwd_comment_log;
CREATE EXTERNAL TABLE gmall.dwd_comment_log(
`mid_id` string,
`user_id` string,
`version_code` string,
`version_name` string,
`lang` string,
`source` string,
`os` string,
`area` string,
`model` string,
`brand` string,
`sdk_version` string,
`gmail` string,
`height_width` string,
`app_time` string,
`network` string,
`lng` string,
`lat` string,
`comment_id` int,
`userid` int,
`p_comment_id` int,
`content` string,
`addtime` string,
`other_id` int,
`praise_count` int,
`reply_count` int,
`server_time` string
)
PARTITIONED BY (dt string)
location '/warehouse/gmall/dwd/dwd_comment_log/';
2)导入数据
hive (gmall)>
insert overwrite table gmall.dwd_comment_log
PARTITION (dt='2019-02-10')
select
mid_id,
user_id,
version_code,
version_name,
lang,
source,
os,
area,
model,
brand,
sdk_version,
gmail,
height_width,
app_time,
network,
lng,
lat,
get_json_object(event_json,'$.kv.comment_id') comment_id,
get_json_object(event_json,'$.kv.userid') userid,
get_json_object(event_json,'$.kv.p_comment_id') p_comment_id,
get_json_object(event_json,'$.kv.content') content,
get_json_object(event_json,'$.kv.addtime') addtime,
get_json_object(event_json,'$.kv.other_id') other_id,
get_json_object(event_json,'$.kv.praise_count') praise_count,
get_json_object(event_json,'$.kv.reply_count') reply_count,
server_time
from gmall.dwd_base_event_log
where dt='2019-02-10' and event_name='comment';
<9> 收藏表 dwd_favorites_log
1)建表语句
hive (gmall)>
drop table if exists gmall.dwd_favorites_log;
CREATE EXTERNAL TABLE gmall.dwd_favorites_log(
`mid_id` string,
`user_id` string,
`version_code` string,
`version_name` string,
`lang` string,
`source` string,
`os` string,
`area` string,
`model` string,
`brand` string,
`sdk_version` string,
`gmail` string,
`height_width` string,
`app_time` string,
`network` string,
`lng` string,
`lat` string,
`id` int,
`course_id` int,
`userid` int,
`add_time` string,
`server_time` string
)
PARTITIONED BY (dt string)
location '/warehouse/gmall/dwd/dwd_favorites_log/';
2)导入数据
hive (gmall)>
insert overwrite table gmall.dwd_favorites_log
PARTITION (dt='2019-02-10')
select
mid_id,
user_id,
version_code,
version_name,
lang,
source,
os,
area,
model,
brand,
sdk_version,
gmail,
height_width,
app_time,
network,
lng,
lat,
get_json_object(event_json,'$.kv.id') id,
get_json_object(event_json,'$.kv.course_id') course_id,
get_json_object(event_json,'$.kv.userid') userid,
get_json_object(event_json,'$.kv.add_time') add_time,
server_time
from gmall.dwd_base_event_log
where dt='2019-02-10' and event_name='favorites';
3)测试
hive (gmall)> select * from gmall.dwd_favorites_log limit 2;
<10> 点赞表 dwd_praise_log
1)建表语句
hive (gmall)>
drop table if exists gmall.dwd_praise_log;
CREATE EXTERNAL TABLE gmall.dwd_praise_log(
`mid_id` string,
`user_id` string,
`version_code` string,
`version_name` string,
`lang` string,
`source` string,
`os` string,
`area` string,
`model` string,
`brand` string,
`sdk_version` string,
`gmail` string,
`height_width` string,
`app_time` string,
`network` string,
`lng` string,
`lat` string,
`id` string,
`userid` string,
`target_id` string,
`type` string,
`add_time` string,
`server_time` string
)
PARTITIONED BY (dt string)
location '/warehouse/gmall/dwd/dwd_praise_log/';
2)导入数据
hive (gmall)>
insert overwrite table gmall.dwd_praise_log
PARTITION (dt='2019-02-10')
select
mid_id,
user_id,
version_code,
version_name,
lang,
source,
os,
area,
model,
brand,
sdk_version,
gmail,
height_width,
app_time,
network,
lng,
lat,
get_json_object(event_json,'$.kv.id') id,
get_json_object(event_json,'$.kv.userid') userid,
get_json_object(event_json,'$.kv.target_id') target_id,
get_json_object(event_json,'$.kv.type') type,
get_json_object(event_json,'$.kv.add_time') add_time,
server_time
from gmall.dwd_base_event_log
where dt='2019-02-10' and event_name='praise';
<11> 错误日志表 dwd_error_log
1)建表语句
hive (gmall)>
drop table if exists gmall.dwd_error_log;
CREATE EXTERNAL TABLE gmall.dwd_error_log(
`mid_id` string,
`user_id` string,
`version_code` string,
`version_name` string,
`lang` string,
`source` string,
`os` string,
`area` string,
`model` string,
`brand` string,
`sdk_version` string,
`gmail` string,
`height_width` string,
`app_time` string,
`network` string,
`lng` string,
`lat` string,
`errorBrief` string,
`errorDetail` string,
`server_time` string)
PARTITIONED BY (dt string)
location '/warehouse/gmall/dwd/dwd_error_log/';
2)导入数据
hive (gmall)>
insert overwrite table gmall.dwd_error_log
PARTITION (dt='2019-02-10')
select
mid_id,
user_id,
version_code,
version_name,
lang,
source,
os,
area,
model,
brand,
sdk_version,
gmail,
height_width,
app_time,
network,
lng,
lat,
get_json_object(event_json,'$.kv.errorBrief') errorBrief,
get_json_object(event_json,'$.kv.errorDetail') errorDetail,
server_time
from gmall.dwd_base_event_log
where dt='2019-02-10' and event_name='error';
3)测试
hive (gmall)> select * from gmall.dwd_error_log limit 2;