HiveQL的DDL操作(二)——创建、分区、查询、修改、删除表
DDL(data definition language)数据库定义语言:
关键词:create、select、alter、drop,对表的操作。
这篇博文主要详细整理了Hive中对于数据表的常用基本操作,创建一个demo表进行演示。
目录
一、创建表
1.1 创建表的完整语法及字段解释
1.2 管理表(内部表)
(1)普通创建表
(2)根据查询结果创建表(create table ~ as select * from ~)
(3)根据已存在的表结构创建表(create table ~ like ~)
(4)查询表的类型(desc formatted ~)
1.3 外部表(虚表)
(1)先上传数据到HDFS中
(2)创建外部表
(3)查看外部表的数据
ps:外部表的查询数据匹配原理
结论:
(4)删除外部表
1.4 管理表与外部表的相互转换
(1)查询表的类型
(2)内部表 ->外部表(EXTERNAL和TRUE必须为大写)
(3)外部表 ->内部表(EXTERNAL和FALSE必须为大写)
二、分区表
(1)创建分区表
(2)往分区表里导数据(load data local inpath '~' into table ~ partition(分区字段 = '~'))
(3)创建二级分区表
(4)分区表数据查询(select * from ~ where 分区字段 = '~')
(5)增加分区
(6)删除分区
(7)查看分区数
三、修改表
(1)表重命名
(2)添加列
(3)更改列名
(4)替换列(将已有全部列替换成新的列,需要保证列数一致否则会造成数据丢失)
四、删除表
一、创建表
1.1 创建表的完整语法及字段解释
create (external) table (if not exists) table_name (
col_name data_type , ...)
comment table_comment
partitioned by (col_name data_type)
clustered by (col_name , col_name , ...)
sorted by (col_name [ASC|DESC], ...)] into num_buckets BUCKETS
row format delimited fields terminated by '\t'
stored as file_format
location hdfs_path
tblproperties (property_name = property_value , ...)
as select_statement
like table table_name(1)external关键词:创建外部表;
ps:删除表的时候,外部表只删除存储在meta store中的元数据,存储在HDFS中的数据不会删除,外部表适合共享数据信息;
内部表会把元数据和数据一起删除。
(2)col_name data_type:字段名 字段数据类型;
(3)comment:为表和列添加注释;
(4)partitioned by:创建分区表;
(5)clustered by:创建分桶表;
(6)sorted by:对一个桶中的一个或多个列进行排序;
(7)row format delimited fields terminated by '\t':表中行的格式是通过制表符'\t'进行分隔的;
(8)stored as:指定存储文件的类型,
常用的有三种:textfile(文本)、sequencefile(二进制序列文件,数据可以压缩)、rcfile(列式存储格式文件);
(9)location:指定表在HDFS中的存储路径(文件夹);
(10)tblproperties:为表增加属性信息;
(11)as:后跟查询语句,表示根据查询结果来创建表;
(12)like:复制现有表的结构,但是不复制数据。
1.2 管理表(内部表)
默认创建的表都是管理表,有时也称内部表。删除管理表时,Hive会删除meta store中的元数据和存储在HDFS中的数据,所以管理表不适合共享数据。
(1)普通创建表
create table if not exists table1(id int, name string)
row format delimited fields terminated by '\t'
stored as textfile
location '/user/hive/warehouse/table1';
创建表在指定路径table1这个文件夹下,在当前数据库中保存;
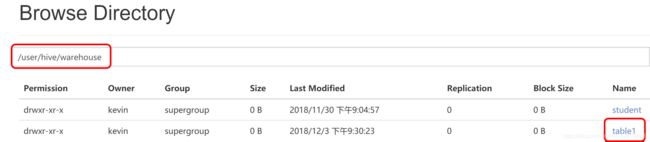
ps:如果没有location指定表的存储路径,它会默认存储在当前数据库路径的文件夹下,在当前数据库中保存。
hive (hive_db1)> create table if not exists table2(id int, name string)
> row format delimited fields terminated by '\t'
> stored as textfile;
(2)根据查询结果创建表(create table ~ as select * from ~)
hive (hive_db1)> create table table3 as select * from table1;(3)根据已存在的表结构创建表(create table ~ like ~)
hive (hive_db1)> create table table4 like table1;
(4)查询表的类型(desc formatted ~)
hive (hive_db1)> desc formatted table1;ps:对比查询详细数据库信息:desc database extended ~
1.3 外部表(虚表)
前面有说过外部表适用于在HDFS中共享数据的表,因为删除外部表,只会删除meta store中的元数据,不删除HDFS中的数据。
案例:创建table5外部表,并向其中导入数据
(1)先上传数据到HDFS中
hive (hive_db1)> dfs -mkdir /student;
hive (hive_db1)> dfs -put /opt/module/datas/student.txt /student;
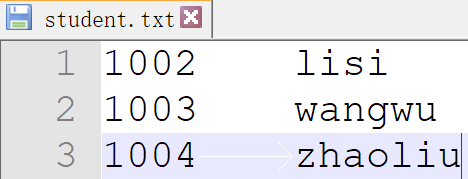
查看一下文件student.txt中的信息
[kevin@hadoop100 datas]$ cat student.txt
1002 lisi
1003 wangwu
1004 zhaoliu
(2)创建外部表
hive (hive_db1)> create external table table_external(id int , name string)
> row format delimited fields terminated by '\t'
> location '/student';
(3)查看外部表的数据
hive (hive_db1)> select * from table_external;
OK
table_external.id table_external.name
1002 lisi
1003 wangwu
1004 zhaoliu
ps:这就是外部表和内部表的区别,内部表是先创建,再导入数据;
外部表多是在HDFS上已有数据文件,在相同文件夹中创建外部表,外部表是一张虚表,能通过相同的字段名,自动匹配对应的当前文件夹下的文件数据,然后查询显示出来。
ps:外部表的查询数据匹配原理
既然外部表查询显示的是相同文件夹下的数据文件的信息,那外部表是如何匹配数据文件的呢?如果相同目录下有两个文件,查询外部表会匹配哪个数据文件呢?
往/student目录下再导入数据文件student2、student3,三个数据文件信息如下


我们再创建一个字段都是string类型的外部表table_external2
hive (hive_db1)> create external table table_external2(sort string , name string)
> row format delimited fields terminated by '\t'
> location '/student';
查询外部表1
hive (hive_db1)> select * from table_external;
OK
table_external.id table_external.name
1002 lisi
1003 wangwu
1004 zhaoliu
NULL lisi
NULL wangwu
NULL zhaoliu
NULL lisi 1
NULL wangwu 2
NULL zhaoliu 3查询外部表2
table_external2.sort table_external2.name
1002 lisi
1003 wangwu
1004 zhaoliu
yi lisi
er wangwu
san zhaoliu
yi lisi 1
er wangwu 2
san zhaoliu 3结论:
在同一个文件夹下存在多个信息文件时,查询该文件夹下任意一个外部表,都会显示所有文件的全部信息,信息与外部表字段类型不匹配的,会显示null。
(4)删除外部表
hive (hive_db1)> drop table table_external;
删除外部表后,发现HDFS上的数据文件并未消失,但metadata中外部表的元数据已删除。
这就是外部表的原理,创建外部表后不需要导入信息,查询时,显示的是HDFS中已有的数据信息。
1.4 管理表与外部表的相互转换
(1)查询表的类型
hive (hive_db1)> desc formatted table1;(2)内部表 ->外部表(EXTERNAL和TRUE必须为大写)
hive (hive_db1)> alter table table1 set tblproperties('EXTERNAL'='TRUE');(3)外部表 ->内部表(EXTERNAL和FALSE必须为大写)
hive (hive_db1)> alter table table1 set tblproperties('EXTERNAL'='FALSE');
二、分区表
Hive中的分区其实就是分目录,根据某些维度(例如时间等)将数据表分成多份,一个分区表对应HDFS文件系统上一个独立的文件夹,该文件夹下是该分区所有的数据文件;
查询时,通过where表达式选择查询所指定的分区即可,不用再查询整张表的所有数据,提高海量数据查询的效率。
(1)创建分区表
hive (hive_db1)> create table stu_par(id int , name string)
> partitioned by (month string)
> row format delimited fields terminated by '\t';
表的字段 id,name;分区字段为month
注意:创建分区表时,分区字段不能是表中的已有字段,否则会报错column repeated in partitioning columns;这也说明分区字段并不是表中的一列,它是一个伪列,对应HDFS中的一个分区文件夹。
(2)往分区表里导数据(load data local inpath '~' into table ~ partition(分区字段 = '~'))
hive (hive_db1)> load data local inpath '/opt/module/datas/student.txt' into table stu_par partition(month = '12');
相同的方法,给分区month=11和month=10也导入student.txt的数据;
ps:由于创建分区表时,没有指定location,它默认保存在当前数据库/hive路径下,创建分区后:
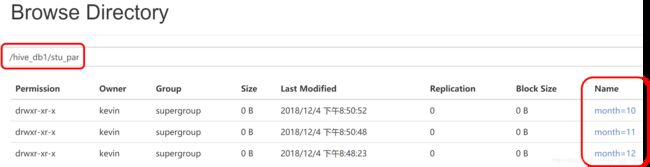
看到在/hive_db1/stu_par目录下,有三个month文件夹;
/hive_db1是当前数据库的默认路径,stu_par是分区表的存储路径,三个month是三个分区的存储路径,每个month文件夹下都有一个student.txt文件;
这就是分区表在HDFS上的存储详情。
ps:如果在default数据库中创建分区表,它的默认存储位置是/user/hive/warehouse/stu_par
(3)创建二级分区表
与创建一级分区表类似,区别点例如:partitioned by(month string , day string)
上传数据也一致,只是需要指定两级分区
hive (hive_db1)> load data local inpath '/opt/module/datas/dept.txt' into table
dept_partition2 partition(month='201709',day='10');(4)分区表数据查询(select * from ~ where 分区字段 = '~')
为了方便显示,接下来用JDBC客户端连接hive,查询如下:
单分区查询:
0: jdbc:hive2://hadoop100:10000> select * from stu_par where month = '12';
+-------------+---------------+----------------+--+
| stu_par.id | stu_par.name | stu_par.month |
+-------------+---------------+----------------+--+
| 1001 | lisi | 12 |
| 1002 | wangwu | 12 |
+-------------+---------------+----------------+--+多分区联合查询:
0: jdbc:hive2://hadoop100:10000> select * from stu_par where month = '12'
0: jdbc:hive2://hadoop100:10000> union
0: jdbc:hive2://hadoop100:10000> select * from stu_par where month = '11'
0: jdbc:hive2://hadoop100:10000> union
0: jdbc:hive2://hadoop100:10000> select * from stu_par where month = '10';
+---------+-----------+------------+--+
| _u3.id | _u3.name | _u3.month |
+---------+-----------+------------+--+
| 1 | one | 11 |
| 2 | two | 11 |
| 3 | three | 11 |
| 101 | kevin | 10 |
| 102 | john | 10 |
| 103 | daniel | 10 |
| 104 | lee | 10 |
| 1001 | lisi | 12 |
| 1002 | wangwu | 12 |
+---------+-----------+------------+--+
多级分区查询:
hive> select * from table where concat_ws('-',dt,proj_id)='20190506-8535';(5)增加分区
增加单个分区:
hive (hive_db1)> alter table stu_par add partition(month = '1');
同时增加多个分区
hive (hive_db1)> alter table stu_par add partition(month = '2') partition(month = '3');
(6)删除分区
删除单个分区:
hive (hive_db1)> alter table stu_par drop partition(month = '1');
Dropped the partition month=1
OK
同时删除多个分区:
hive (hive_db1)> alter table stu_par drop partition(month = '2'),partition(month = '3');
Dropped the partition month=2
Dropped the partition month=3
OK
(7)查看分区数
hive (hive_db1)> show partitions stu_par;
OK
partition
month=10
month=11
month=12
三、修改表
(1)表重命名
hive (hive_db1)> alter table stu_par rename to stu1;
(2)添加列
hive (hive_db1)> alter table stu1 add columns(dept string);
0: jdbc:hive2://hadoop100:10000> select * from stu1;
+----------+------------+------------+-------------+--+
| stu1.id | stu1.name | stu1.dept | stu1.month |
+----------+------------+------------+-------------+--+
| 101 | kevin | NULL | 10 |
| 102 | john | NULL | 10 |
| 103 | daniel | NULL | 10 |
| 104 | lee | NULL | 10 |
| 1 | one | NULL | 11 |
| 2 | two | NULL | 11 |
| 3 | three | NULL | 11 |
| 1001 | lisi | NULL | 12 |
| 1002 | wangwu | NULL | 12 |
+----------+------------+------------+-------------+--+新增列数据全为NULL
(3)更改列名
hive (hive_db1)> alter table stu1 change column dept new int;
0: jdbc:hive2://hadoop100:10000> select * from stu1;
+----------+------------+-----------+-------------+--+
| stu1.id | stu1.name | stu1.new | stu1.month |
+----------+------------+-----------+-------------+--+
| 101 | kevin | NULL | 10 |
| 102 | john | NULL | 10 |
| 103 | daniel | NULL | 10 |
| 104 | lee | NULL | 10 |
| 1 | one | NULL | 11 |
| 2 | two | NULL | 11 |
| 3 | three | NULL | 11 |
| 1001 | lisi | NULL | 12 |
| 1002 | wangwu | NULL | 12 |
+----------+------------+-----------+-------------+--+
(4)替换列(将已有全部列替换成新的列,需要保证列数一致否则会造成数据丢失)
hive (hive_db1)> alter table stu1 replace columns(deptno string , dname string , loc string);
0: jdbc:hive2://hadoop100:10000> select * from stu1;
+--------------+-------------+-----------+-------------+--+
| stu1.deptno | stu1.dname | stu1.loc | stu1.month |
+--------------+-------------+-----------+-------------+--+
| 101 | kevin | NULL | 10 |
| 102 | john | NULL | 10 |
| 103 | daniel | NULL | 10 |
| 104 | lee | NULL | 10 |
| 1 | one | NULL | 11 |
| 2 | two | NULL | 11 |
| 3 | three | NULL | 11 |
| 1001 | lisi | NULL | 12 |
| 1002 | wangwu | NULL | 12 |
+--------------+-------------+-----------+-------------+--+
四、删除表
hive (hive_db1)> drop table stu1;
如果是外部表,则元数据在metastore中删除,但是表数据还在HDFS中,虚表;
如果是管理表(默认,内部表),则元数据在metastore中删除,表数据在HDFS中也删除,实表。