Flume + Kafka + SparkStreaming(2.0)
本文阅读需具有一定Flume Kafka SparkStreaming的基础知识。
1、Flume以及Kafka环境搭建。
版本的选择,参考http://spark.apache.org/docs/latest/streaming-kafka-integration.html
| spark-streaming-kafka-0-8 | spark-streaming-kafka-0-10 | |
|---|---|---|
| Broker Version | 0.8.2.1 or higher | 0.10.0 or higher |
| Api Stability | Stable | Experimental |
| Language Support | Scala, Java, Python | Scala, Java |
| Receiver DStream | Yes | No |
| Direct DStream | Yes | Yes |
| SSL / TLS Support | No | Yes |
| Offset Commit Api | No | Yes |
| Dynamic Topic Subscription | No | Yes |
故而这里给出Flume的Maven,对于Kafka读者可以自行参看上述官网。
groupId = org.apache.spark
artifactId = spark-streaming-flume_2.11
version = 2.0.22、Flume设计架构
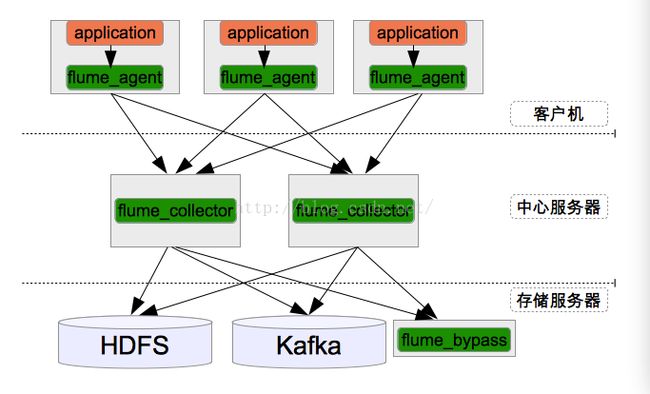
使用 基于Flume的美团日志收集系统(一)架构和设计http://www.aboutyun.com/thread-8317-1-1.html(出处: about云开发)中提到的架构(在这里对博主无私共享,表示感谢)其整体架构如下图所示:
2-1)客户端配置
参看网址:http://flume.apache.org/FlumeUserGuide.html
为了便于观察,笔者将为客户端设置3个sinks,前两个用于向flume_collector 发送数据,最后一个用于打印当前日志,配置内容如下:
agent.sources = source1
agent.channels = channel1 channel3
agent.sinks = sink1 sink2 sink3
agent.sinkgroups = group1
#配置数据来源
agent.sources.source1.channels = channel1 channel3
agent.sources.source1.type = exec
agent.sources.source1.shell = /bin/bash -c
agent.sources.source1.restart = true
agent.sources.source1.batchTimeout = 3000
agent.sources.source1.batchSize = 10000
agent.sources.source1.threads = 5
agent.sources.source1.selector.type = replicating
agent.sources.source1.command = tail -n +0 -F /usr/tomcat/tomcat8/logs/localhost_access_log.2016-11-16.txt
#设置数据通道
agent.channels.channel1.capacity = 100000
# Each channel's type is defined.
agent.channels.channel1.type = memory
# Other config values specific to each type of channel(sink or source)
# can be defined as well
# In this case, it specifies the capacity of the memory channel
agent.channels.channel1.transactionCapacity = 10000
agent.channels.channel3.capacity = 100000
agent.channels.channel3.type = memory
agent.channels.channel3.transactionCapacity = 10000
#设置数据输出
agent.sinks.sink1.channel = channel1
agent.sinks.sink1.type = avro
agent.sinks.sink1.hostname = lenovo1
agent.sinks.sink1.port = 12343
agent.sinks.sink1.batch-size = 0
agent.sinks.sink2.channel = channel1
agent.sinks.sink2.type = avro
agent.sinks.sink2.hostname = lenovo2
agent.sinks.sink2.port = 12343
agent.sinks.sink2.batch-size = 0
agent.sinks.sink3.type = logger
agent.sinks.sink3.channel = channel3
agent.sinks.sink3.sink.maxBytesToLog = 1000
# clientMainAgent sinks group
agent.sinkgroups.group1.sinks = sink1 sink2
# load_balance type
agent.sinkgroups.group1.processor.type = load_balance
agent.sinkgroups.group1.processor.backoff = true
agent.sinkgroups.group1.processor.selector = random在这里需要注意的是使用了两个channel,具体原因,通过下图一目了然:

Source中提取的数据只有一份,channel相当于一个缓冲池,如果所有的Sink均取自于一个Channel,那么造成的结果就是一份数据被分割。
2-2)中心服务机配置
agent.sources = source1
agent.channels = channel1 channel2
agent.sinks = sink1 sink2
#配置数据来源
agent.sources.source1.type = avro
agent.sources.source1.selector.type = replicating
agent.sources.source1.channels = channel1 channel2
agent.sources.source1.bind = 0.0.0.0
agent.sources.source1.port = 12343
agent.channels = channel1 channel2
agent.sinks = sink1 sink2
#配置数据来源
agent.sources.source1.type = avro
agent.sources.source1.selector.type = replicating
agent.sources.source1.channels = channel1 channel2
agent.sources.source1.bind = 0.0.0.0
agent.sources.source1.port = 12343
#设置数据通道
agent.channels.channel1.capacity = 1000
# Each channel's type is defined.
agent.channels.channel1.type = memory
# Other config values specific to each type of channel(sink or source)
# can be defined as well
# In this case, it specifies the capacity of the memory channel
agent.channels.channel1.capacity = 100
agent.channels.channel2.capacity = 1000
agent.channels.channel2.type = memory
agent.channels.channel2.capacity = 100
#设置数据输出
#以hdfs方式输出
agent.sinks.sink1.channel = channel1
agent.sinks.sink1.type = hdfs
agent.sinks.sink1.hdfs.useLocalTimeStamp = true
agent.sinks.sink1.hdfs.path = hdfs://lenovo1:9000/flume/events/%Y/%m/%d/%H/%M
agent.sinks.sink1.hdfs.filePrefix = l2_log
agent.sinks.sink1.hdfs.minBlockReplicas = 1
agent.sinks.sink1.hdfs.fileType = DataStream
agent.sinks.sink1.hdfs.writeFormat = Text
agent.sinks.sink1.hdfs.rollInterval = 60
agent.sinks.sink1.hdfs.rollSize = 102400
agent.sinks.sink1.hdfs.rollCount = 0
agent.sinks.sink1.hdfs.idleTimeout = 0
agent.sinks.sink1.hdfs.batchSize = 100
#以kafka形式输出
agent.sinks.sink2.channel = channel2
agent.sinks.sink2.type = org.apache.flume.sink.kafka.KafkaSink
agent.sinks.sink2.kafka.topic = mytopic
agent.sinks.sink2.kafka.bootstrap.servers = lenovo1:9092,lenovo2:9092,lenovo3:9092,lenovo4:9092,lenovo6:9092,lenovo7:9092
agent.sinks.sink2.kafka.flumeBatchSize = 20
agent.sinks.sink2.kafka.producer.acks = 0在这里,笔者要着重讲解与HDFS Sink 相关的几个参数:
hdfs.rollIterval ;hdfs.rollSize ; hdfs.rollCount ;hdfs.batchSize ;
hdfs.rollIterval :Number of seconds to wait before rolling current file (0 = never roll based on time interval)
经笔者实验之后解释为:从创建tmp文件开始,直到多长时间后会触发flush操作,log日志如下:
2016-11-16 10:30:53,058 INFO hdfs.BucketWriter: Closing hdfs://lenovo1:9000/flume/events/2016/11/16/10/29/l1_log.1479263392993.tmp
2016-11-16 10:30:53,093 INFO hdfs.BucketWriter: Renaming hdfs://lenovo1:9000/flume/events/2016/11/16/10/29/l1_log.1479263392993.tmp to hdfs://lenovo1:9000/flume/events/2016/11/16/10/29/l1_log.1479263392993
hdfs.rollSize:File size to trigger roll, in bytes (0: never roll based on file size)
解释为:当文件大小超过多少时,触发flush操作
hdfs.rollCount :Number of events written to file before it rolled(0 = never roll based on number of events)
解释为:当接收事件大于某个值时,触发flush操作
以上3个参数的设置是or关系,即只要满足任一要求即发生flush操作,需要注意:
如果读者设置了hdfs.path = %Y/%d/%H/%M 等与时间相关的文件创建及更新时,要保证在设置的最小单位时间内,能够触发上述条件之一,否则将一直不会触发flush操作。
hdfs.batchSize :number of events written to file before it is flushed to HDFS
解释为:一次性地从channel中提取事件的数量,batchSize大小直接影响到整个流程的性能。
经实践提出如下参数设置建议:
rollInterval 设置为最小单位时间向下一级时间转换所需的单位时间个数,比如文件设置为根据当前时间的分钟数进行创建,则rollInterval应该设置为60。
rollCount 设置为0,即不以rollCount作为触发flush操作的条件,当然这个前提是要存储到HDFS中
rollSize 设置为HDFS中一个块的整数倍大小(最好一次写入一个块),如果过小将产生大量HDFS小文件,严重浪费存储空间。
batchSize 设置为channel中的transactionCapacity大小,保证channel中的一次事务为一次写入HDFS。
channel中参数建议:
capacity :The maximum number of events stored in the channel
解释为:channel中最大存放的事件数量。
transactionCapacity :The maximum number of events the channel will take from a source or give to a sink pertransaction
解释为:每个事务所对应的最大事件数量。
byteCapacity : Maximum total bytes of memory allowed as a sum of all events in this channel.
The implementation only counts the Event body, which is the reason for providing thebyteCapacityBufferPercentage configuration parameter as well
Defaults to a computed value equal to 80% of the maximum memory available to the JVM (i.e. 80% of the -Xmx value passed on the command line).
解释为:最大的字节容量,一般为JVM的80%,并且只考虑了事件的主体部分,没有考虑header中内容。
上述两个参数的设置要根据内存情况进行设置。
source中参数建议:
batchSize :The max number of lines to read and send to the channel at a time
解释为:一次从文件中读取的行数
batchTimeout :Amount of time (in milliseconds) to wait, if the buffer size was not reached, before data is pushed downstream
解释为:在buffer没有存满的前提下,提交等待的时间。
在不考虑buffer的情况下,batchSize / batchTimeOut 的值应该大于数据的产生速率,否则将出现数据不能及时处理的情况。
3、编写SparkStreaming Kafka代码,参看http://spark.apache.org/docs/latest/streaming-kafka-0-10-integration.html,代码如下:
object StreamingKafka {
Logger.getLogger("org.apache.spark").setLevel(Level.WARN)
Logger.getLogger("org.eclipse.jetty.server").setLevel(Level.WARN)
def main(args: Array[String]) {
val kafkaParams = Map[String, Object](
"bootstrap.servers" -> "lenovo1:9092,lenovo2:9092,lenovo3:9092,lenovo4:9092,lenovo6:9092,lenovo7:9092",
"key.deserializer" -> classOf[StringDeserializer],
"value.deserializer" -> classOf[StringDeserializer],
"group.id" -> "groups",
"auto.offset.reset" -> "latest",
"enable.auto.commit" -> (false: java.lang.Boolean)
)
val topics = Array("mytopic")
val conf = new SparkConf()
.setMaster("spark://lenovo1:7077")
.set("spark.eventLog.enabled", "true")
.set("spark.eventLog.dir", "hdfs://cluster/spark/directory")
.setAppName(this.getClass.getSimpleName)
.setJars(Array("E:\\ScalaSpace\\Spark2_Streaming\\out\\artifacts\\Spark2.0_Archetype.jar"))
val ssc = new StreamingContext(conf, Seconds(5))
ssc.checkpoint("hdfs://cluster/spark/checkpoint/streaming")
val stream = KafkaUtils.createDirectStream[String,String](
ssc,
LocationStrategies.PreferConsistent,
Subscribe[String,String](topics, kafkaParams)
)
stream.map(record => record.value).foreachRDD(rdd => {
println("start ---------------")
rdd.collect().foreach(println)
})
// stream.print()
ssc.start()
ssc.awaitTermination()
}
}当提交到集群时可能会报出classNotFound错误,解决方法为将缺失包放入Spark jars目录下:

至此一个简单的日志收集便完成了,但是对于使用exec方式的source官方并不提倡,鉴于此读者可选择其他方案来替代。