pandas之DataFrame使用详解
pandas数据类型DataFrame
DataFrame(数据框),可以看成excel表。
DataFrame是一种表格型数据结构,它含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔型等),DataFrame既有行索引(index)也有列索引(column)。行索引和列索引是标签。
DataFrame的创建有多种方式,不过最重要的还是根据dict进行创建,以及读取csv或者txt文件来创建。
(1)创建DataFrame
import pandas as pd
#以字典dict方式建立
df1=pd.DataFrame({'name':['Tom','Jone','Marry'],
'age':[20,18,19],
'income':[1000,3000,2000]},
index=['person1','person2','person3']) #若没有写index的值,则采用默认的index:0,1,2……
print(df1)
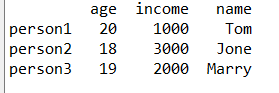
df=pd.DataFrame(np.random.randint(0,10,[2,3]),index=np.arange(0,2),columns=['A','B','C'])
print(df)

(2)查看DataFrame的属性(index,columns,values )
import pandas as pd
df1=pd.DataFrame({'name':['Tom','Jone','Marry'],
'age':[20,18,19],
'income':[1000,3000,2000]},
) #没有定义index,采用默认的index0,1,2……
print(df1)
print('____________')
print(df1.index) #行索引
print(df1.columns)#列索引
print(df1.values)#值

(3)修改列名,(rename)
修改全部列名
import pandas as pd
df1=pd.DataFrame({'name':['Tom','Jone','Marry'],
'age':[20,18,19],
'income':[1000,3000,2000]},
index=['person1','person2','person3'])
#修改columns
df1.columns=range(0,len(df1.columns)) #修改了全部的列名
print(df1.columns)#0,1,2
![]()
精准修改列名(逐一修改列名)rename
import pandas as pd
df1=pd.DataFrame({'name':['Tom','Jone','Marry'],
'age':[20,18,19],
'income':[1000,3000,2000]},
index=['person1','person2','person3'])
#修改columns
#修改单个列名
df1.rename(columns={"age":"年龄",'name':'名字'},inplace=True) #一定要写inplace=True,否则仍未修改。此外注意:True不能写成true
print(df1.columns)
![]()
(4)修改index行名(和(3)使用方法一样)
import pandas as pd
df1=pd.DataFrame({'name':['Tom','Jone','Marry'],
'age':[20,18,19],
'income':[1000,3000,2000]},
index=['person1','person2','person3'])
#修改index
df1.index=range(0,len(df1.index))
#精准修改
df1.rename(index={'person1':5},inplace=True)
(5)增加一列
import pandas as pd
df1=pd.DataFrame({'name':['Tom','Jone','Marry'],
'age':[20,18,19],
'income':[1000,3000,2000]},
index=['person1','person2','person3'])
#增加一列
df1['pay']=[20,30,40] #在最后一列添加
print(df1)
print('______________')
#修改某一列的位置
df1.insert(0,'pay',df1.pop('pay')) #将pay列移到0位置处
print(df1)
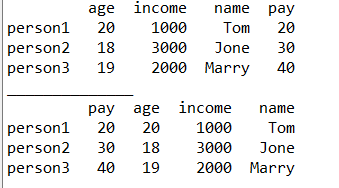
(6)增加一行(loc)
import pandas as pd
df1=pd.DataFrame({'name':['Tom','Jone','Marry'],
'age':[20,18,19],
'income':[1000,3000,2000]},
index=['person1','person2','person3'])
#增加一行
df1.loc['person4',['age','name','income']] =[20,'kittty',2000]
loc为 Selection by Label函数,简单的来讲,即为按标签取数据
(7)访问列
import pandas as pd
df1=pd.DataFrame({'name':['Tom','Jone','Marry'],
'age':[20,18,19],
'income':[1000,3000,2000]},
index=['person1','person2','person3'])
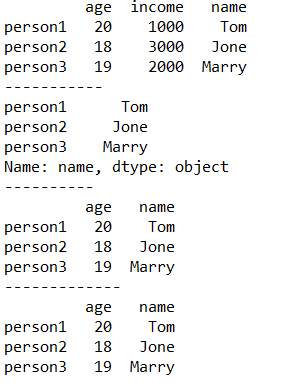
print(df1)
print('-----------')
#访问列
print(df1.name) #df.列名
print('----------')
#访问某些列
print(df1[['age','name']])
print('-------------')
#访问某些列
print(df1[[0,2]])
(8)访问行
import pandas as pd
df1=pd.DataFrame({'name':['Tom','Jone','Marry'],
'age':[20,18,19],
'income':[1000,3000,2000]},
index=['person1','person2','person3'])
#访问行
print(df1[0:2])#左闭右开
print('--------')
print(df1.loc[['person1','person3']])

(9)删除列或行(del,drop)
del
'''
del
'''
import pandas as pd
df1=pd.DataFrame({'name':['Tom','Jone','Marry'],
'age':[20,18,19],
'income':[1000,3000,2000]},
index=['person1','person2','person3'])
#del是直接在df1上删除
del df1['age']
print(df1)
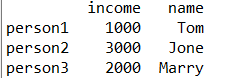
drop
'''
drop
'''
import pandas as pd
df1=pd.DataFrame({'name':['Tom','Jone','Marry'],
'age':[20,18,19],
'income':[1000,3000,2000]},
index=['person1','person2','person3'])
#删除列
data=df1.drop('age',axis=1) #axis=1表示列,axis=0表示行
print(df1)#从结果可以看出df1中没有删掉,但data中没有age列了
print('------')
print(data)
print('------')
df1.drop('age',axis=1,inplace=True) #写上inplace=True后,才能从原数据中删除。若不写默认为False
print(df1)

(10)查询DataFrame(loc()、iloc()、以及ix()方法)链接
(11)DataFrame中常见的操作(排序,值替换,重新排列数据中的列)
import pandas as pd
#定义字典
dic={'name':['Tom','Jone','Mark'],
'age':[30,18,20],
'gender':['m','f','m']}
#创建DataFrame
df=pd.DataFrame(dic)
print(df)

#根据年龄这一列,进行排序(升序和降序)
df=df.sort_values(by=['age'])#默认升序排列 #注意如果不再次赋值,df中的数据仍不会改变
print(df)
print('-----')
df=df.sort_values(by=['age'],ascending=False)#降序排列
print(df)

#值替换
df['gender']=df['gender'].replace('m','male')#注意也是需要再次赋值。
#如果想改变多个df['gender'].replace(['m','f'],['male','female']) m换成male,f换成female
#df['gender'].replace(['m','f'],'male']) m和f都换成male
print(df)
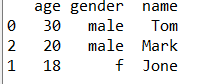
#重新排列数据中的列的位置
df=df.ix[:,['name','age','gender']]#利用ix()访问数据的方法来重新调整列的位置
print(df)
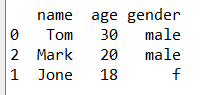
(12)数据框合并
数据框合并链接
(13)合并数据框的列
合并数据框的列链接