怎样系统规划大数据学习之路?
大数据的领域非常广泛,往往使想要开始学习大数据及相关技术的人望而生畏。大数据技术的种类众多,这同样使得初学者难以选择从何处下手。
这正是我想要撰写本文的原因。本文将为你开始学习大数据的征程以及在大数据产业领域找到工作指明道路,提供帮助。目前我们面临的最大挑战就是根据我们的兴趣和技能选定正确的角色。
为了解决这个问题,我在本文详细阐述了每个与大数据有关的角色,同时考量了工程师以及计算机科学毕业生的不同职位角色。
我尽量详细地回答了每一项人们在学习大数据过程中遇到或可能会遇到的问题。为帮助你根据兴趣选择发展途径,我添加了一组树图,相信会对你找到正确的途径有所帮助。
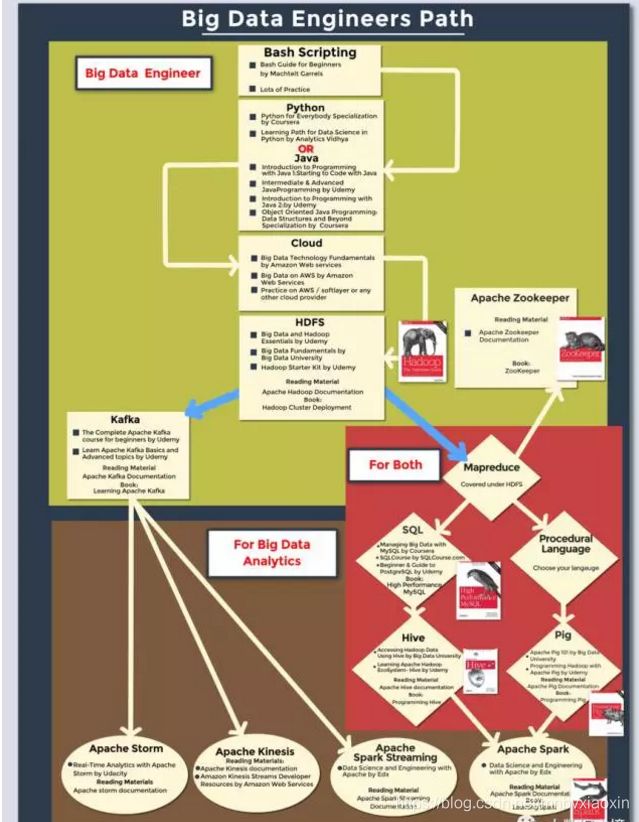
注释:学习之路树状图
在这个树状图的帮助下,你可以根据你的兴趣和目标选择路径。 然后,你可以开始学习大数据的旅程了。
目录表
1.如何开始?
2.在大数据领域有哪些职位需求?
3.你的领域是什么,适合什么方向?
4.勾勒你在大数据领域的角色
5.如何成为一名大数据工程师?
o什么是大数据行业术语?
o你需要了解的系统和结构
o学习去设计解决方案并且学习相关技术
6.大数据学习路径
7.资源
1.如何开始?
人们想开始学习大数据的时候,最常问我的问题是,“我应该学Hadoop(hadoop是一款开源软件,主要用于分布式存储和计算,他由HDFS和MapReduce计算框架组成的,他们分别是Google的GFS和MapReduce的开源实现。由于hadoop的易用性和可扩展性,因此成为最近流行的海量数据处理框架。hadoop这个单词来源于其发明者的儿子为一个玩具大象起的名字。), 分布式计算,Kafka(Kafka是由LinkedIn开发的一个分布式基于发布/订阅的消息系统),NoSQL(泛指非关系型的数据库)还是Spark(Spark 是一种与 Hadoop 相似的开源集群计算环境,但是两者之间还存在一些不同之处)?”想系统学习大数据的话,可以加入大数据技术学习扣扣君羊:522189307
而我通常只有一个答案:“这取决于你究竟想做什么。”
因此,让我们用一种有条理的方式来解决这个问题。我们将一步步地探索这条学习之路。
2. 在大数据行业有哪些职业需求?
在大数据行业中有很多领域。通常来说它们可以被分为两类:
-
大数据工程
-
大数据分析
这些领域互相独立又互相关联。
大数据工程涉及大量数据的设计,部署,获取以及维护(保存)。大数据工程师需要去设计和部署这样一个系统,使相关数据能面向不同的消费者及内部应用。
而大数据分析的工作则是利用大数据工程师设计的系统所提供的大量数据。大数据分析包括趋势、图样分析以及开发不同的分类、预测预报系统。
因此,简而言之,大数据分析是对数据的高级计算。而大数据工程则是进行系统设计、部署以及计算运行平台的顶层构建。
3.你的领域是什么,适合什么方向?
现在我们已经了解了行业中可供选择的职业种类,让我们想办法来确定哪个领域适合你。这样,我们才能确定你在这个行业中的位置。
通常来说,基于你的教育背景和行业经验我们可以进行如下分类:
-
教育背景
(包括兴趣,而不一定与你的大学教育有关)
-
计算机科学
-
数学
-
行业经验
-
新人
-
数据学家
-
计算机工程师(在数据相关领域工作)
因此,通过上面的分类,你可以把自己的领域定位如下:
例1:“我是一名计算机科学毕业生,不过没有坚实的数学技巧。”
你对计算机科学或者数学有兴趣,但是之前没有相关经验,你将被定义为一个新人。
例2:“我是一个计算机科学毕业生,目前正从事数据库开发工作。”
你的兴趣在计算机科学方向,你适合计算机工程师(数据相关工程)的角色。
例3:“我正作为数据科学家从事统计工作。”
你对数学领域有兴趣,适合数据科学家的职业角色。
因此,参照着定位你的领域吧。
(此处定义的领域对你确定在大数据行业的学习路径至关重要。)
4.根据领域规划你的角色
现在你已经确定了你的领域,下一步,让我们规划出你要努力的目标职位吧。
如果你有卓越的编程技巧并理解计算机如何在网络(基础)上运作,而你对数学和统计学毫无兴趣,在这种情况下,你应该朝着大数据工程职位努力。
如果你擅长编程同时有数学或者统计学的教育背景或兴趣,你应该朝着大数据分析师职位努力。
5.如何成为一名大数据工程师
让我们先定义一下,一名受到行业承认的大数据工程师都需要学习和了解什么。首先以及最重要的一步是确认你的需求。你不能在不清楚个人需求的情况下直接开始学习大数据。否则,你将一直盲人摸象。
为了明确你的需求,你必须了解常用的大数据术语。所以让我们来看一下大数据到底意味着什么?
5.1 大数据术语
大数据工程通常包括两个方面 – 数据需求以及处理需求。
5.1.1 数据需求术语
结构:你应该知道数据可以储存在表中或者文件中。储存在一个预定义的数据模型(即拥有架构)中的数据称为结构化数据。如果数据储存在文件中且没有预定义模型,则称为非结构化数据。(种类:结构化/非结构化)。
容量:我们用容量来定义数据的数量。(种类:S/M/L/XL/XXL/流)
Sink吞吐量:用系统所能接受的数据率来定义Sink吞吐量。(种类:H/M/L)
源吞吐量:定义为数据更新和转化进入系统的速度。(种类:H/M/L)
5.1.2 处理需求术语
查询时间:系统查询所需时间。(种类:长/中/短)
处理时间:处理数据所需时间。(种类:长/中/短)
精度:数据处理的精确度。(种类:准确/大约)
5.2 你需要知道的系统和架构
情景1:
为分析一个公司的销售表现需要设计一个系统,即创建一个数据池,数据池来自于多重数据源,比如客户数据、领导数据、客服中心数据、销售数据、产品数据、博客等。
5.3 学习设计解决方案和技术
情节1的解决方案:销售数据池
(这是我的个人解决方案,如果你想到一个更高明的解决方案请在下面分享一下)
那么,一个数据工程师会怎样解决这个问题呢?
需要记住的一点是,大数据系统的目的不仅仅是无缝整合各种来源的数据,而使其可用,同时它必须能使得,用于开发应用系统的数据的分析和利用变得简单迅速和易得(在这个案例中是智能控制面板)。
定义最后的目标:
1. 通过整合各种来源的数据创建一个数据池。
2. 每隔一定时间自动更新数据(在这个案例中可能是一周一次)。
3. 可用于分析的数据(在记录时间内,甚至可能是每天)
4. 易得的架构和无缝部署的分析控制面板。
既然我们知道了我们最后的目标,让我们尽量用正式术语制定我们的要求吧。